spark0.9分布式安装
spark安装包:spark-0.9.0-incubating-bin-hadoop2.tgz
操作系统: CentOS6.4
jdk版本: jdk1.7.0_21
1. Cluster模式
1.1安装Hadoop
用VMware Workstation创建三台CentOS虚拟机,hostname分别设置为 master,slaver01, slaver02,设置SSH无密码登陆,安装hadoop,然后启动hadoop集群。参考我的这篇博客,hadoop-2.2.0分布式安装.
1.2 Scala
在三台机器上都要安装 Scala 2.9.3,按照我的博客SparK安装的步骤。JDK在安装Hadoop时已经安装了。进入master节点。
$ cd$ scp -r scala-2.10.3 root@slaver01:~$ scp -r scala-2.10.3 root@slaver02:~
1.3在master上安装并配置Spark
解压
$ tar -zxf spark-0.9.0-incubating-bin-hadoop2.tgz$ mv spark-0.9.0-incubating-bin-hadoop2 spark-0.9在 inconf/spark-env.sh中设置SCALA_HOME
$ cd ~/spark-0.9/conf$ mv spark-env.sh.template spark-env.sh$ vi spark-env.sh# add the following lineexport SCALA_HOME=/root/scala-2.10.3export JAVA_HOME=/usr/java/jdk1.7.0_21export SPARK_MASTER_IP=192.168.159.129
export SPARK_WORKER_MEMORY=1000m
# save and exit
在conf/slaves,添加Sparkworker的hostname,一行一个。
$ vim slavesslaver01slaver02master# save and exit(可选)设置 SPARK_HOME环境变量,并将SPARK_HOME/bin加入PATH
$ vim /etc/profile# add the following lines at the endexport SPARK_HOME=$HOME/spark-0.9export PATH=$PATH:$SPARK_HOME/bin# save and exit vim#make the bash profile take effect immediately$ source /etc/profile1.4在所有worker上安装并配置Spark
既然master上的这个文件件已经配置好了,把它拷贝到所有的worker即可。注意,三台机器spark所在目录必须一致,因为master会登陆到worker上执行命令,master认为worker的spark路径与自己一样。
$ cd$ scp -r spark-0.9 root@slaver01:~$ scp -r spark-0.9 root@slaver02:~1.5启动 Spark集群
在master上执行
$ cd ~/spark-0.9$ ./sbin/start-all.sh检测进程是否启动
[root@master ~]# jps3200 SecondaryNameNode7350 Master7470 Worker3025 NameNode8022 Jps3332 ResourceManager 浏览master的web UI(默认http://master:8080).这是你应该可以看到所有的work节点,以及他们的CPU个数和内存等信息。
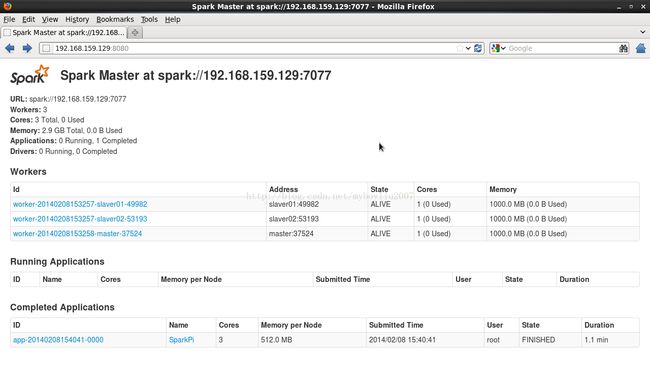
1.6运行Spark自带的例子
运行SparkPi
$ cd ~/spark-0.90.646: [GC 16448K->5202K(59328K), 0.0075490 secs]
0.758: [GC 21650K->8626K(59328K), 0.0068840 secs]
1.746: [GC 25074K->11294K(59328K), 0.0109470 secs]
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/mnt/home/cr10/spark-1.0/examples/target/scala-2.10/spark-examples-1.0.0-SNAPSHOT-hadoop2.3.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/mnt/home/cr10/spark-1.0/assembly/target/scala-2.10/spark-assembly-1.0.0-SNAPSHOT-hadoop2.3.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
14/05/15 17:54:07 INFO SparkConf: Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
14/05/15 17:54:07 ERROR SparkConf:
SPARK_JAVA_OPTS was detected (set to '-verbose:gc -XX:-PrintGCDetails -XX:+PrintGCTimeStamps').
This has undefined behavior when running on a cluster and is deprecated in Spark 1.0+.
Please instead use:
- ./spark-submit with conf/spark-defaults.conf to set defaults for an application
- ./spark-submit with --driver-java-options to set -X options for a driver
- spark.executor.extraJavaOptions to set -X options for executors
- SPARK_DAEMON_OPTS to set java options for standalone daemons (i.e. master, worker)
14/05/15 17:54:07 WARN SparkConf: Setting 'spark.executor.extraJavaOptions' to '-verbose:gc -XX:-PrintGCDetails -XX:+PrintGCTimeStamps' as a work-around.
14/05/15 17:54:07 WARN SparkConf: Setting 'spark.driver.extraJavaOptions' to '-verbose:gc -XX:-PrintGCDetails -XX:+PrintGCTimeStamps' as a work-around.
14/05/15 17:54:07 INFO SecurityManager: SecurityManager, is authentication enabled: false are ui acls enabled: false users with view permissions: Set(cr10)
2.875: [GC 27741K->13240K(59328K), 0.0259670 secs]
14/05/15 17:54:08 INFO Slf4jLogger: Slf4jLogger started
14/05/15 17:54:08 INFO Remoting: Starting remoting
3.567: [GC 29688K->15857K(59328K), 0.0147370 secs]
14/05/15 17:54:08 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://spark@chaoren1:48825]
14/05/15 17:54:08 INFO Remoting: Remoting now listens on addresses: [akka.tcp://spark@chaoren1:48825]
14/05/15 17:54:08 INFO SparkEnv: Registering MapOutputTracker
14/05/15 17:54:08 INFO SparkEnv: Registering BlockManagerMaster
14/05/15 17:54:08 INFO DiskBlockManager: Created local directory at /tmp/spark-local-20140515175408-651c
14/05/15 17:54:08 INFO MemoryStore: MemoryStore started with capacity 555.7 MB.
14/05/15 17:54:09 INFO ConnectionManager: Bound socket to port 44663 with id = ConnectionManagerId(chaoren1,44663)
14/05/15 17:54:09 INFO BlockManagerMaster: Trying to register BlockManager
14/05/15 17:54:09 INFO BlockManagerInfo: Registering block manager chaoren1:44663 with 555.7 MB RAM
14/05/15 17:54:09 INFO BlockManagerMaster: Registered BlockManager
14/05/15 17:54:09 INFO HttpServer: Starting HTTP Server
14/05/15 17:54:09 INFO HttpBroadcast: Broadcast server started at http://10.161.74.123:50743
14/05/15 17:54:09 INFO HttpFileServer: HTTP File server directory is /tmp/spark-e4ebc9a4-96af-4d71-af3f-213db7cb32e0
14/05/15 17:54:09 INFO HttpServer: Starting HTTP Server
4.166: [GC 32305K->18970K(59328K), 0.0156590 secs]
14/05/15 17:54:09 INFO SparkUI: Started SparkUI at http://chaoren1:4040
14/05/15 17:54:10 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
5.153: [GC 35418K->21456K(59328K), 0.0214030 secs]
14/05/15 17:54:12 INFO SparkContext: Added JAR /mnt/home/cr10/spark-1.0/examples/target/scala-2.10/spark-examples-1.0.0-SNAPSHOT-hadoop2.3.0.jar at http://10.161.74.123:36570/jars/spark-examples-1.0.0-SNAPSHOT-hadoop2.3.0.jar with timestamp 1400147652306
7.181: [Full GC 27566K->5233K(59328K), 0.0621170 secs]
14/05/15 17:54:12 INFO SparkContext: Starting job: reduce at SparkPi.scala:39
14/05/15 17:54:12 INFO DAGScheduler: Got job 0 (reduce at SparkPi.scala:39) with 2 output partitions (allowLocal=false)
14/05/15 17:54:12 INFO DAGScheduler: Final stage: Stage 0 (reduce at SparkPi.scala:39)
14/05/15 17:54:12 INFO DAGScheduler: Parents of final stage: List()
14/05/15 17:54:12 INFO DAGScheduler: Missing parents: List()
14/05/15 17:54:12 INFO DAGScheduler: Submitting Stage 0 (MappedRDD[1] at map at SparkPi.scala:35), which has no missing parents
14/05/15 17:54:12 INFO DAGScheduler: Submitting 2 missing tasks from Stage 0 (MappedRDD[1] at map at SparkPi.scala:35)
14/05/15 17:54:12 INFO TaskSchedulerImpl: Adding task set 0.0 with 2 tasks
14/05/15 17:54:12 INFO TaskSetManager: Starting task 0.0:0 as TID 0 on executor localhost: localhost (PROCESS_LOCAL)
14/05/15 17:54:12 INFO TaskSetManager: Serialized task 0.0:0 as 1419 bytes in 4 ms
14/05/15 17:54:12 INFO Executor: Running task ID 0
14/05/15 17:54:12 INFO Executor: Fetching http://10.161.74.123:36570/jars/spark-examples-1.0.0-SNAPSHOT-hadoop2.3.0.jar with timestamp 1400147652306
14/05/15 17:54:12 INFO Utils: Fetching http://10.161.74.123:36570/jars/spark-examples-1.0.0-SNAPSHOT-hadoop2.3.0.jar to /tmp/fetchFileTemp4557014535629526465.tmp
14/05/15 17:54:13 INFO Executor: Adding file:/tmp/spark-003a8e43-e6a7-411a-99e3-06ead7d8d967/spark-examples-1.0.0-SNAPSHOT-hadoop2.3.0.jar to class loader
8.497: [GC 21617K->8154K(59328K), 0.0127120 secs]
14/05/15 17:54:13 INFO Executor: Serialized size of result for 0 is 675
14/05/15 17:54:13 INFO Executor: Sending result for 0 directly to driver
14/05/15 17:54:13 INFO Executor: Finished task ID 0
14/05/15 17:54:13 INFO TaskSetManager: Starting task 0.0:1 as TID 1 on executor localhost: localhost (PROCESS_LOCAL)
14/05/15 17:54:13 INFO TaskSetManager: Serialized task 0.0:1 as 1419 bytes in 0 ms
14/05/15 17:54:13 INFO Executor: Running task ID 1
14/05/15 17:54:13 INFO DAGScheduler: Completed ResultTask(0, 0)
14/05/15 17:54:13 INFO TaskSetManager: Finished TID 0 in 818 ms on localhost (progress: 1/2)
14/05/15 17:54:13 INFO Executor: Serialized size of result for 1 is 675
14/05/15 17:54:13 INFO Executor: Sending result for 1 directly to driver
14/05/15 17:54:13 INFO Executor: Finished task ID 1
14/05/15 17:54:13 INFO TaskSetManager: Finished TID 1 in 97 ms on localhost (progress: 2/2)
14/05/15 17:54:13 INFO DAGScheduler: Completed ResultTask(0, 1)
14/05/15 17:54:13 INFO DAGScheduler: Stage 0 (reduce at SparkPi.scala:39) finished in 0.925 s
14/05/15 17:54:13 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
14/05/15 17:54:13 INFO SparkContext: Job finished: reduce at SparkPi.scala:39, took 1.18208852 s
Pi is roughly 3.14166
14/05/15 17:54:13 INFO SparkUI: Stopped Spark web UI at http://chaoren1:4040
14/05/15 17:54:15 INFO MapOutputTrackerMasterActor: MapOutputTrackerActor stopped!
14/05/15 17:54:15 INFO ConnectionManager: Selector thread was interrupted!
14/05/15 17:54:15 INFO ConnectionManager: ConnectionManager stopped
14/05/15 17:54:15 INFO MemoryStore: MemoryStore cleared
14/05/15 17:54:15 INFO BlockManager: BlockManager stopped
14/05/15 17:54:15 INFO BlockManagerMasterActor: Stopping BlockManagerMaster
14/05/15 17:54:15 INFO BlockManagerMaster: BlockManagerMaster stopped
14/05/15 17:54:15 INFO SparkContext: Successfully stopped SparkContext
14/05/15 17:54:15 INFO RemoteActorRefProvider$RemotingTerminator: Shutting down remote daemon.
14/05/15 17:54:15 INFO RemoteActorRefProvider$RemotingTerminator: Remote daemon shut down; proceeding with flushing remote transports.
[cr10@chaoren1 spark-1.0]$
运行SparkLR
#Logistic Regression
[root@master spark-0.9]# ./bin/run-example org.apache.spark.examples.SparkLR spark://192.168.159.129:7077SLF4J: Class path contains multiple SLF4J bindings.SLF4J: Found binding in [jar:file:/root/spark-0.9/examples/target/scala-2.10/spark-examples_2.10-assembly-0.9.0-incubating.jar!/org/slf4j/impl/StaticLoggerBinder.class]SLF4J: Found binding in [jar:file:/root/spark-0.9/assembly/target/scala-2.10/spark-assembly_2.10-0.9.0-incubating-hadoop2.2.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.SLF4J: Actual binding is of type [org.slf4j.impl.SimpleLoggerFactory]0 [spark-akka.actor.default-dispatcher-4] INFO akka.event.slf4j.Slf4jLogger - Slf4jLogger started95 [spark-akka.actor.default-dispatcher-4] INFO Remoting - Starting remoting441 [spark-akka.actor.default-dispatcher-2] INFO Remoting - Remoting started; listening on addresses :[akka.tcp://spark@master:59496]441 [spark-akka.actor.default-dispatcher-2] INFO Remoting - Remoting now listens on addresses: [akka.tcp://spark@master:59496]494 [main] INFO org.apache.spark.SparkEnv - Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties494 [main] INFO org.apache.spark.SparkEnv - Registering BlockManagerMaster565 [main] INFO org.apache.spark.storage.DiskBlockManager - Created local directory at /tmp/spark-local-20140208155527-140e569 [main] INFO org.apache.spark.storage.MemoryStore - MemoryStore started with capacity 148.5 MB.607 [main] INFO org.apache.spark.network.ConnectionManager - Bound socket to port 46771 with id = ConnectionManagerId(master,46771)kend - Registered executor: Actor[akka.tcp://sparkExecutor@slaver02:37832/user/Executor#1651743406] with ID 345103 [spark-akka.actor.default-dispatcher-4] INFO org.apache.spark.scheduler.cluster.SparkDeploySchedulerBackend - Executor 1 disconnected, so removing it45103 [spark-akka.actor.default-dispatcher-4] ERROR org.apache.spark.scheduler.TaskSchedulerImpl - Lost executor 1 on slaver01: remote Akka client disassociated45103 [spark-akka.actor.default-dispatcher-4] INFO org.apache.spark.scheduler.TaskSetManager - Re-queueing tasks for 1 from TaskSet 0.045104 [spark-akka.actor.default-dispatcher-4] WARN org.apache.spark.scheduler.TaskSetManager - Lost TID 1 (task 0.0:0)45104 [spark-akka.actor.default-dispatcher-4] INFO org.apache.spark.scheduler.TaskSetManager - Starting task 0.0:0 as TID 3 on executor 3: slaver02 (PROCESS_LOCAL)45105 [spark-akka.actor.default-dispatcher-5] INFO org.apache.spark.scheduler.DAGScheduler - Executor lost: 1 (epoch 1)45105 [spark-akka.actor.default-dispatcher-13] INFO org.apache.spark.storage.BlockManagerMasterActor - Trying to remove executor 1 from BlockManagerMaster.45106 [spark-akka.actor.default-dispatcher-5] INFO org.apache.spark.storage.BlockManagerMaster - Removed 1 successfully in removeExecutor45433 [spark-akka.actor.default-dispatcher-4] INFO org.apache.spark.scheduler.TaskSetManager - Serialized task 0.0:0 as 551899 bytes in 329 ms45453 [spark-akka.actor.default-dispatcher-4] INFO org.apache.spark.deploy.client.AppClient$ClientActor - Executor updated: app-20140208155019-0001/1 is now FAILED (Command exited with code 1)45453 [spark-akka.actor.default-dispatcher-4] INFO org.apache.spark.scheduler.cluster.SparkDeploySchedulerBackend - Executor app-20140208155019-0001/1 removed: Command exited with code 145468 [spark-akka.actor.default-dispatcher-14] INFO org.apache.spark.deploy.client.AppClient$ClientActor - Executor added: app-20140208155019-0001/5 on worker-20140208153257-slaver01-49982 (slaver01:49982) with 1 cores45469 [spark-akka.actor.default-dispatcher-14] INFO org.apache.spark.scheduler.cluster.SparkDeploySchedulerBackend - Granted executor ID app-20140208155019-0001/5 on hostPort slaver01:49982 with 1 cores, 512.0 MB RAM45472 [spark-akka.actor.default-dispatcher-5] ERROR akka.remote.EndpointWriter - AssociationError [akka.tcp://spark@master:52897] -> [akka.tcp://sparkExecutor@slaver01:57904]: Error [Association failed with [akka.tcp://sparkExecutor@slaver01:57904]] [akka.remote.EndpointAssociationException: Association failed with [akka.tcp://sparkExecutor@slaver01:57904]Caused by: akka.remote.transport.netty.NettyTransport$$anonfun$associate$1$$anon$2: Connection refused: slaver01/192.168.159.130:57904]45483 [spark-akka.actor.default-dispatcher-4] ERROR akka.remote.EndpointWriter - AssociationError [akka.tcp://spark@master:52897] -> [akka.tcp://sparkExecutor@slaver01:57904]: Error [Association failed with [akka.tcp://sparkExecutor@slaver01:57904]] [akka.remote.EndpointAssociationException: Association failed with [akka.tcp://sparkExecutor@slaver01:57904]Caused by: akka.remote.transport.netty.NettyTransport$$anonfun$associate$1$$anon$2: Connection refused: slaver01/192.168.159.130:57904]45780 [spark-akka.actor.default-dispatcher-5] ERROR akka.remote.EndpointWriter - AssociationError [akka.tcp://spark@master:52897] -> [akka.tcp://sparkExecutor@slaver01:57904]: Error [Association failed with [akka.tcp://sparkExecutor@slaver01:57904]] [akka.remote.EndpointAssociationException: Association failed with [akka.tcp://sparkExecutor@slaver01:57904]Caused by: akka.remote.transport.netty.NettyTransport$$anonfun$associate$1$$anon$2: Connection refused: slaver01/192.168.159.130:57904]45781 [spark-akka.actor.default-dispatcher-15] INFO org.apache.spark.deploy.client.AppClient$ClientActor - Executor updated: app-20140208155019-0001/5 is now RUNNING46589 [spark-akka.actor.default-dispatcher-2] INFO org.apache.spark.storage.BlockManagerMasterActor$BlockManagerInfo - Added rdd_0_1 in memory on master:44542 (size: 717.5 KB, free: 296.3 MB)46762 [Result resolver thread-0] INFO org.apache.spark.scheduler.TaskSetManager - Finished TID 2 in 20510 ms on master (progress: 0/2)46767 [spark-akka.actor.default-dispatcher-2] INFO org.apache.spark.scheduler.DAGScheduler - Completed ResultTask(0, 1)50080 [spark-akka.actor.default-dispatcher-13] INFO org.apache.spark.scheduler.cluster.SparkDeploySchedulerBackend - Registered executor: Actor[akka.tcp://sparkExecutor@slaver01:60056/user/Executor#1166039681] with ID 554828 [spark-akka.actor.default-dispatcher-2] INFO org.apache.spark.storage.BlockManagerMasterActor$BlockManagerInfo - Registering block manager slaver01:43329 with 297.0 MB RAM62254 [spark-akka.actor.default-dispatcher-4] INFO org.apache.spark.storage.BlockManagerMasterActor$BlockManagerInfo - Registering block manager slaver02:55569 with 297.0 MB RAM89782 [spark-akka.actor.default-dispatcher-3] INFO org.apache.spark.storage.BlockManagerMasterActor$BlockManagerInfo - Added rdd_0_0 in memory on slaver02:55569 (size: 717.5 KB, free: 296.3 MB)90043 [Result resolver thread-1] INFO org.apache.spark.scheduler.TaskSetManager - Finished TID 3 in 44939 ms on slaver02 (progress: 1/2)90043 [spark-akka.actor.default-dispatcher-3] INFO org.apache.spark.scheduler.DAGScheduler - Completed ResultTask(0, 0)90061 [spark-akka.actor.default-dispatcher-3] INFO org.apache.spark.scheduler.DAGScheduler - Stage 0 (reduce at SparkLR.scala:64) finished in 84.257 s90066 [Result resolver thread-1] INFO org.apache.spark.scheduler.TaskSchedulerImpl - Remove TaskSet 0.0 from pool90075 [main] INFO org.apache.spark.SparkContext - Job finished: reduce at SparkLR.scala:64, took 84.881569465 sOn iteration 290100 [main] INFO org.apache.spark.SparkContext - Starting job: reduce at SparkLR.scala:6490100 [spark-akka.actor.default-dispatcher-3] INFO org.apache.spark.scheduler.DAGScheduler - Got job 1 (reduce at SparkLR.scala:64) with 2 output partitions (allowLocal=false)90100 [spark-akka.actor.default-dispatcher-3] INFO org.apache.spark.scheduler.DAGScheduler - Final stage: Stage 1 (reduce at SparkLR.scala:64)90101 [spark-akka.actor.default-dispatcher-3] INFO org.apache.spark.scheduler.DAGScheduler - Parents of final stage: List()90103 [spark-akka.actor.default-dispatcher-3] INFO org.apache.spark.scheduler.DAGScheduler - Missing parents: List()90104 [spark-akka.actor.default-dispatcher-3] INFO org.apache.spark.scheduler.DAGScheduler - Submitting Stage 1 (MappedRDD[2] at map at SparkLR.scala:62), which has no missing parents90164 [spark-akka.actor.default-dispatcher-3] INFO org.apache.spark.scheduler.DAGScheduler - Submitting 2 missing tasks from Stage 1 (MappedRDD[2] at map at SparkLR.scala:62)90165 [spark-akka.actor.default-dispatcher-3] INFO org.apache.spark.scheduler.TaskSchedulerImpl - Adding task set 1.0 with 2 tasks90169 [spark-akka.actor.default-dispatcher-13] INFO org.apache.spark.scheduler.TaskSetManager - Starting task 1.0:1 as TID 4 on executor 4: master (PROCESS_LOCAL)90191 [spark-akka.actor.default-dispatcher-13] INFO org.apache.spark.scheduler.TaskSetManager - Serialized task 1.0:1 as 551895 bytes in 21 ms90194 [spark-akka.actor.default-dispatcher-13] INFO org.apache.spark.scheduler.TaskSetManager - Starting task 1.0:0 as TID 5 on executor 3: slaver02 (PROCESS_LOCAL)90220 [spark-akka.actor.default-dispatcher-13] INFO org.apache.spark.scheduler.TaskSetManager - Serialized task 1.0:0 as 551895 bytes in 25 ms91222 [Result resolver thread-2] INFO org.apache.spark.scheduler.TaskSetManager - Finished TID 4 in 1053 ms on master (progress: 0/2)91224 [spark-akka.actor.default-dispatcher-16] INFO org.apache.spark.scheduler.DAGScheduler - Completed ResultTask(1, 1)91609 [Result resolver thread-3] INFO org.apache.spark.scheduler.TaskSetManager - Finished TID 5 in 1415 ms on slaver02 (progress: 1/2)91610 [spark-akka.actor.default-dispatcher-16] INFO org.apache.spark.scheduler.DAGScheduler - Completed ResultTask(1, 0)91610 [spark-akka.actor.default-dispatcher-16] INFO org.apache.spark.scheduler.DAGScheduler - Stage 1 (reduce at SparkLR.scala:64) finished in 1.437 s91611 [main] INFO org.apache.spark.SparkContext - Job finished: reduce at SparkLR.scala:64, took 1.510467278 sOn iteration 391616 [Result resolver thread-3] INFO org.apache.spark.scheduler.TaskSchedulerImpl - Remove TaskSet 1.0 from pool91622 [main] INFO org.apache.spark.SparkContext - Starting job: reduce at SparkLR.scala:6491623 [spark-akka.actor.default-dispatcher-2] INFO org.apache.spark.scheduler.DAGScheduler - Got job 2 (reduce at SparkLR.scala:64) with 2 output partitions (allowLocal=false)91623 [spark-akka.actor.default-dispatcher-2] INFO org.apache.spark.scheduler.DAGScheduler - Final stage: Stage 2 (reduce at SparkLR.scala:64)91623 [spark-akka.actor.default-dispatcher-2] INFO org.apache.spark.scheduler.DAGScheduler - Parents of final stage: List()91624 [spark-akka.actor.default-dispatcher-2] INFO org.apache.spark.scheduler.DAGScheduler - Missing parents: List()91624 [spark-akka.actor.default-dispatcher-2] INFO org.apache.spark.scheduler.DAGScheduler - Submitting Stage 2 (MappedRDD[3] at map at SparkLR.scala:62), which has no missing parents91777 [spark-akka.actor.default-dispatcher-2] INFO org.apache.spark.scheduler.DAGScheduler - Submitting 2 missing tasks from Stage 2 (MappedRDD[3] at map at SparkLR.scala:62)91777 [spark-akka.actor.default-dispatcher-2] INFO org.apache.spark.scheduler.TaskSchedulerImpl - Adding task set 2.0 with 2 tasks91779 [spark-akka.actor.default-dispatcher-5] INFO org.apache.spark.scheduler.TaskSetManager - Starting task 2.0:1 as TID 6 on executor 4: master (PROCESS_LOCAL)91899 [spark-akka.actor.default-dispatcher-5] INFO org.apache.spark.scheduler.TaskSetManager - Serialized task 2.0:1 as 551896 bytes in 119 ms91899 [spark-akka.actor.default-dispatcher-5] INFO org.apache.spark.scheduler.TaskSetManager - Starting task 2.0:0 as TID 7 on executor 3: slaver02 (PROCESS_LOCAL)91922 [spark-akka.actor.default-dispatcher-5] INFO org.apache.spark.scheduler.TaskSetManager - Serialized task 2.0:0 as 551896 bytes in 23 ms92290 [Result resolver thread-0] INFO org.apache.spark.scheduler.TaskSetManager - Finished TID 6 in 511 ms on master (progress: 0/2)92291 [spark-akka.actor.default-dispatcher-14] INFO org.apache.spark.scheduler.DAGScheduler - Completed ResultTask(2, 1)92694 [Result resolver thread-1] INFO org.apache.spark.scheduler.TaskSetManager - Finished TID 7 in 794 ms on slaver02 (progress: 1/2)92694 [Result resolver thread-1] INFO org.apache.spark.scheduler.TaskSchedulerImpl - Remove TaskSet 2.0 from pool92694 [spark-akka.actor.default-dispatcher-4] INFO org.apache.spark.scheduler.DAGScheduler - Completed ResultTask(2, 0)92695 [spark-akka.actor.default-dispatcher-4] INFO org.apache.spark.scheduler.DAGScheduler - Stage 2 (reduce at SparkLR.scala:64) finished in 0.913 s92695 [main] INFO org.apache.spark.SparkContext - Job finished: reduce at SparkLR.scala:64, took 1.072671482 sOn iteration 492704 [main] INFO org.apache.spark.SparkContext - Starting job: reduce at SparkLR.scala:6492704 [spark-akka.actor.default-dispatcher-3] INFO org.apache.spark.scheduler.DAGScheduler - Got job 3 (reduce at SparkLR.scala:64) with 2 output partitions (allowLocal=false)92704 [spark-akka.actor.default-dispatcher-3] INFO org.apache.spark.scheduler.DAGScheduler - Final stage: Stage 3 (reduce at SparkLR.scala:64)92704 [spark-akka.actor.default-dispatcher-3] INFO org.apache.spark.scheduler.DAGScheduler - Parents of final stage: List()92707 [spark-akka.actor.default-dispatcher-3] INFO org.apache.spark.scheduler.DAGScheduler - Missing parents: List()92707 [spark-akka.actor.default-dispatcher-3] INFO org.apache.spark.scheduler.DAGScheduler - Submitting Stage 3 (MappedRDD[4] at map at SparkLR.scala:62), which has no missing parents92734 [spark-akka.actor.default-dispatcher-3] INFO org.apache.spark.scheduler.DAGScheduler - Submitting 2 missing tasks from Stage 3 (MappedRDD[4] at map at SparkLR.scala:62)92734 [spark-akka.actor.default-dispatcher-3] INFO org.apache.spark.scheduler.TaskSchedulerImpl - Adding task set 3.0 with 2 tasks92736 [spark-akka.actor.default-dispatcher-14] INFO org.apache.spark.scheduler.TaskSetManager - Starting task 3.0:1 as TID 8 on executor 4: master (PROCESS_LOCAL)92759 [spark-akka.actor.default-dispatcher-14] INFO org.apache.spark.scheduler.TaskSetManager - Serialized task 3.0:1 as 551899 bytes in 23 ms92760 [spark-akka.actor.default-dispatcher-14] INFO org.apache.spark.scheduler.TaskSetManager - Starting task 3.0:0 as TID 9 on executor 3: slaver02 (PROCESS_LOCAL)92789 [spark-akka.actor.default-dispatcher-14] INFO org.apache.spark.scheduler.TaskSetManager - Serialized task 3.0:0 as 551899 bytes in 28 ms93091 [Result resolver thread-2] INFO org.apache.spark.scheduler.TaskSetManager - Finished TID 8 in 356 ms on master (progress: 0/2)93092 [spark-akka.actor.default-dispatcher-13] INFO org.apache.spark.scheduler.DAGScheduler - Completed ResultTask(3, 1)96638 [Result resolver thread-3] INFO org.apache.spark.scheduler.TaskSetManager - Finished TID 9 in 3878 ms on slaver02 (progress: 1/2)96638 [Result resolver thread-3] INFO org.apache.spark.scheduler.TaskSchedulerImpl - Remove TaskSet 3.0 from pool96639 [spark-akka.actor.default-dispatcher-2] INFO org.apache.spark.scheduler.DAGScheduler - Completed ResultTask(3, 0)96639 [spark-akka.actor.default-dispatcher-2] INFO org.apache.spark.scheduler.DAGScheduler - Stage 3 (reduce at SparkLR.scala:64) finished in 3.899 s96639 [main] INFO org.apache.spark.SparkContext - Job finished: reduce at SparkLR.scala:64, took 3.935444196 sOn iteration 596646 [main] INFO org.apache.spark.SparkContext - Starting job: reduce at SparkLR.scala:6496646 [spark-akka.actor.default-dispatcher-4] INFO org.apache.spark.scheduler.DAGScheduler - Got job 4 (reduce at SparkLR.scala:64) with 2 output partitions (allowLocal=false)96646 [spark-akka.actor.default-dispatcher-4] INFO org.apache.spark.scheduler.DAGScheduler - Final stage: Stage 4 (reduce at SparkLR.scala:64)96646 [spark-akka.actor.default-dispatcher-4] INFO org.apache.spark.scheduler.DAGScheduler - Parents of final stage: List()96649 [spark-akka.actor.default-dispatcher-4] INFO org.apache.spark.scheduler.DAGScheduler - Missing parents: List()96649 [spark-akka.actor.default-dispatcher-4] INFO org.apache.spark.scheduler.DAGScheduler - Submitting Stage 4 (MappedRDD[5] at map at SparkLR.scala:62), which has no missing parents96677 [spark-akka.actor.default-dispatcher-4] INFO org.apache.spark.scheduler.DAGScheduler - Submitting 2 missing tasks from Stage 4 (MappedRDD[5] at map at SparkLR.scala:62)96677 [spark-akka.actor.default-dispatcher-4] INFO org.apache.spark.scheduler.TaskSchedulerImpl - Adding task set 4.0 with 2 tasks96678 [spark-akka.actor.default-dispatcher-16] INFO org.apache.spark.scheduler.TaskSetManager - Starting task 4.0:1 as TID 10 on executor 4: master (PROCESS_LOCAL)96702 [spark-akka.actor.default-dispatcher-16] INFO org.apache.spark.scheduler.TaskSetManager - Serialized task 4.0:1 as 551896 bytes in 24 ms96703 [spark-akka.actor.default-dispatcher-16] INFO org.apache.spark.scheduler.TaskSetManager - Starting task 4.0:0 as TID 11 on executor 3: slaver02 (PROCESS_LOCAL)96726 [spark-akka.actor.default-dispatcher-16] INFO org.apache.spark.scheduler.TaskSetManager - Serialized task 4.0:0 as 551896 bytes in 23 ms97554 [Result resolver thread-0] INFO org.apache.spark.scheduler.TaskSetManager - Finished TID 10 in 876 ms on master (progress: 0/2)97555 [spark-akka.actor.default-dispatcher-4] INFO org.apache.spark.scheduler.DAGScheduler - Completed ResultTask(4, 1)97810 [Result resolver thread-1] INFO org.apache.spark.scheduler.TaskSetManager - Finished TID 11 in 1108 ms on slaver02 (progress: 1/2)97811 [Result resolver thread-1] INFO org.apache.spark.scheduler.TaskSchedulerImpl - Remove TaskSet 4.0 from pool97811 [spark-akka.actor.default-dispatcher-14] INFO org.apache.spark.scheduler.DAGScheduler - Completed ResultTask(4, 0)97811 [spark-akka.actor.default-dispatcher-14] INFO org.apache.spark.scheduler.DAGScheduler - Stage 4 (reduce at SparkLR.scala:64) finished in 1.130 s97811 [main] INFO org.apache.spark.SparkContext - Job finished: reduce at SparkLR.scala:64, took 1.165505777 sFinal w: (5816.075967498865, 5222.008066011391, 5754.751978607454, 3853.1772062206846, 5593.565827145932, 5282.387874201054, 3662.9216051953435, 4890.78210340607, 4223.371512250292, 5767.368579668863)[root@master spark-0.9]# [root@master spark-0.9]#1.6从HDFS读取文件并运行WordCount
$ cd ~/spark-0.9$ MASTER=spark:// 192.168.159.129:7077 ./spark-shell[root@master spark-0.9]# MASTER=spark://192.168.159.129:7077 bin/spark-shell14/02/08 16:17:57 INFO HttpServer: Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties14/02/08 16:17:57 INFO HttpServer: Starting HTTP ServerWelcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 0.9.0 /_/ Using Scala version 2.10.3 (Java HotSpot(TM) Client VM, Java 1.7.0_21)Type in expressions to have them evaluated.Type :help for more information.14/02/08 16:18:04 INFO Slf4jLogger: Slf4jLogger started14/02/08 16:18:04 INFO Remoting: Starting remoting14/02/08 16:18:04 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://spark@master:57338]14/02/08 16:18:04 INFO Remoting: Remoting now listens on addresses: [akka.tcp://spark@master:57338]14/02/08 16:18:04 INFO SparkEnv: Registering BlockManagerMaster14/02/08 16:18:04 INFO DiskBlockManager: Created local directory at /tmp/spark-local-20140208161804-d96e14/02/08 16:18:04 INFO MemoryStore: MemoryStore started with capacity 297.0 MB.14/02/08 16:18:04 INFO ConnectionManager: Bound socket to port 54967 with id = ConnectionManagerId(master,54967)14/02/08 16:18:04 INFO BlockManagerMaster: Trying to register BlockManager14/02/08 16:18:04 INFO BlockManagerMasterActor$BlockManagerInfo: Registering block manager master:54967 with 297.0 MB RAM14/02/08 16:18:04 INFO BlockManagerMaster: Registered BlockManager14/02/08 16:18:04 INFO HttpServer: Starting HTTP Server14/02/08 16:18:04 INFO HttpBroadcast: Broadcast server started at http://192.168.159.129:5119314/02/08 16:18:04 INFO SparkEnv: Registering MapOutputTracker14/02/08 16:18:04 INFO HttpFileServer: HTTP File server directory is /tmp/spark-a63d283e-90dd-4a09-b2de-d9feda31f60714/02/08 16:18:04 INFO HttpServer: Starting HTTP Server14/02/08 16:18:05 INFO SparkUI: Started Spark Web UI at http://master:404014/02/08 16:18:05 INFO AppClient$ClientActor: Connecting to master spark://192.168.159.129:7077...14/02/08 16:18:06 INFO SparkDeploySchedulerBackend: Connected to Spark cluster with app ID app-20140208161806-000714/02/08 16:18:06 INFO AppClient$ClientActor: Executor added: app-20140208161806-0007/0 on worker-20140208153258-master-37524 (master:37524) with 1 cores14/02/08 16:18:06 INFO SparkDeploySchedulerBackend: Granted executor ID app-20140208161806-0007/0 on hostPort master:37524 with 1 cores, 512.0 MB RAM14/02/08 16:18:06 INFO AppClient$ClientActor: Executor added: app-20140208161806-0007/1 on worker-20140208153257-slaver01-49982 (slaver01:49982) with 1 cores14/02/08 16:18:06 INFO SparkDeploySchedulerBackend: Granted executor ID app-20140208161806-0007/1 on hostPort slaver01:49982 with 1 cores, 512.0 MB RAM14/02/08 16:18:06 INFO AppClient$ClientActor: Executor added: app-20140208161806-0007/2 on worker-20140208153257-slaver02-53193 (slaver02:53193) with 1 cores14/02/08 16:18:06 INFO SparkDeploySchedulerBackend: Granted executor ID app-20140208161806-0007/2 on hostPort slaver02:53193 with 1 cores, 512.0 MB RAM14/02/08 16:18:06 INFO AppClient$ClientActor: Executor updated: app-20140208161806-0007/1 is now RUNNING14/02/08 16:18:06 INFO AppClient$ClientActor: Executor updated: app-20140208161806-0007/0 is now RUNNING14/02/08 16:18:06 INFO AppClient$ClientActor: Executor updated: app-20140208161806-0007/2 is now RUNNING14/02/08 16:18:07 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableCreated spark context..Spark context available as sc.scala> val file = sc.textFile("hdfs://192.168.159.129:9000//tmp-output101/part-r-00000")14/02/08 17:16:29 INFO MemoryStore: ensureFreeSpace(132668) called with curMem=132636, maxMem=31138775014/02/08 17:16:29 INFO MemoryStore: Block broadcast_1 stored as values to memory (estimated size 129.6 KB, free 296.7 MB)file: org.apache.spark.rdd.RDD[String] = MappedRDD[3] at textFile at :12 scala> val count = file.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_+_)14/02/08 17:16:42 INFO FileInputFormat: Total input paths to process : 1count: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[8] at reduceByKey at :14 scala> count.collect()14/02/08 17:16:49 INFO SparkContext: Starting job: collect at :17 14/02/08 17:16:49 INFO DAGScheduler: Registering RDD 6 (reduceByKey at :14) 14/02/08 17:16:49 INFO DAGScheduler: Got job 0 (collect at :17) with 2 output partitions (allowLocal=false) 14/02/08 17:16:49 INFO DAGScheduler: Final stage: Stage 0 (collect at :17) 14/02/08 17:16:49 INFO DAGScheduler: Parents of final stage: List(Stage 1)14/02/08 17:16:49 INFO DAGScheduler: Missing parents: List(Stage 1)14/02/08 17:16:49 INFO DAGScheduler: Submitting Stage 1 (MapPartitionsRDD[6] at reduceByKey at :14), which has no missing parents 14/02/08 17:16:49 INFO DAGScheduler: Submitting 2 missing tasks from Stage 1 (MapPartitionsRDD[6] at reduceByKey at :14) 14/02/08 17:16:49 INFO TaskSchedulerImpl: Adding task set 1.0 with 2 tasks14/02/08 17:16:49 INFO TaskSetManager: Starting task 1.0:0 as TID 0 on executor 2: slaver02 (NODE_LOCAL)14/02/08 17:16:49 INFO TaskSetManager: Serialized task 1.0:0 as 1955 bytes in 47 ms14/02/08 17:16:49 INFO TaskSetManager: Starting task 1.0:1 as TID 1 on executor 1: slaver01 (NODE_LOCAL)14/02/08 17:16:49 INFO TaskSetManager: Serialized task 1.0:1 as 1955 bytes in 0 ms14/02/08 17:17:02 INFO TaskSetManager: Finished TID 1 in 13049 ms on slaver01 (progress: 0/2)14/02/08 17:17:02 INFO DAGScheduler: Completed ShuffleMapTask(1, 1)14/02/08 17:17:05 INFO TaskSetManager: Finished TID 0 in 15876 ms on slaver02 (progress: 1/2)14/02/08 17:17:05 INFO DAGScheduler: Completed ShuffleMapTask(1, 0)14/02/08 17:17:05 INFO DAGScheduler: Stage 1 (reduceByKey at :14) finished in 15.877 s 14/02/08 17:17:05 INFO DAGScheduler: looking for newly runnable stages14/02/08 17:17:05 INFO DAGScheduler: running: Set()14/02/08 17:17:05 INFO DAGScheduler: waiting: Set(Stage 0)14/02/08 17:17:05 INFO DAGScheduler: failed: Set()14/02/08 17:17:05 INFO DAGScheduler: Missing parents for Stage 0: List()14/02/08 17:17:05 INFO DAGScheduler: Submitting Stage 0 (MapPartitionsRDD[8] at reduceByKey at :14), which is now runnable 14/02/08 17:17:05 INFO TaskSchedulerImpl: Remove TaskSet 1.0 from pool14/02/08 17:17:05 INFO DAGScheduler: Submitting 2 missing tasks from Stage 0 (MapPartitionsRDD[8] at reduceByKey at :14) 14/02/08 17:17:05 INFO TaskSchedulerImpl: Adding task set 0.0 with 2 tasks14/02/08 17:17:05 INFO TaskSetManager: Starting task 0.0:0 as TID 2 on executor 2: slaver02 (PROCESS_LOCAL)14/02/08 17:17:05 INFO TaskSetManager: Serialized task 0.0:0 as 1807 bytes in 1 ms14/02/08 17:17:05 INFO TaskSetManager: Starting task 0.0:1 as TID 3 on executor 1: slaver01 (PROCESS_LOCAL)14/02/08 17:17:05 INFO TaskSetManager: Serialized task 0.0:1 as 1807 bytes in 0 ms14/02/08 17:17:05 INFO MapOutputTrackerMasterActor: Asked to send map output locations for shuffle 0 to spark@slaver01:4304814/02/08 17:17:05 INFO MapOutputTrackerMaster: Size of output statuses for shuffle 0 is 147 bytes14/02/08 17:17:05 INFO MapOutputTrackerMasterActor: Asked to send map output locations for shuffle 0 to spark@slaver02:4239314/02/08 17:17:07 INFO TaskSetManager: Finished TID 2 in 1741 ms on slaver02 (progress: 0/2)14/02/08 17:17:07 INFO DAGScheduler: Completed ResultTask(0, 0)14/02/08 17:17:07 INFO TaskSetManager: Finished TID 3 in 2311 ms on slaver01 (progress: 1/2)14/02/08 17:17:07 INFO DAGScheduler: Completed ResultTask(0, 1)14/02/08 17:17:07 INFO DAGScheduler: Stage 0 (collect at :17) finished in 2.321 s 14/02/08 17:17:07 INFO TaskSchedulerImpl: Remove TaskSet 0.0 from pool14/02/08 17:17:07 INFO SparkContext: Job finished: collect at :17, took 18.921360252 s res1: Array[(String, Int)] = Array((Fate 1,1), (wayside. 1,1), (energetic 3,1), (fourth 7,1), (gouging 1,1), (Frances 1,1), (NOVEMBER 1,1), (about. 2,1), (propel 1,1), (beginning. 2,1), (faunas 1,1), (natural 26,1), (calves, 1,1), (tends 5,1), (sea-level. 1,1), (molluscs. 1,1), (supported 3,1), (stoneless 1,1), (Here 9,1), (Planet 1,1), (dwell 1,1), (behaviour--experimenting, 1,1), (Actual 1,1), (Sluggish 1,1), (Looked 1,1), (mysterious 12,1), (fauna, 2,1), (primaries 1,1), (Mercury's 2,1), (_instinctively_ 2,1), (females 2,1), (ELECTRICITY? 1,1), (claws, 1,1), (sedimentary 6,1), (Vertebrates 4,1), ("little-brain" 4,1), (fertilises 3,1), (word. 1,1), (all; 3,1), ("atomism." 1,1), (reactions. 3,1), (away. 10,1), (beginning, 2,1), (groove. 1,1), (Egg-eating 1,1), (depreciate 1,1), (know, ...scala>1.8停止 Spark集群
$ cd ~/spark-0.9$ ./sbin/stop-all.sh