Excel中的Pivot Table/Pivot Chart可以说是一个即强大,使用起来又很简单的功能。有时候结合函数来使用,基本上都可以解决我在工作中遇到的数据分析问题。
在Excel 2010 中又推出了PowerPivot ,是EXCEL 2010的一个插件,顾名思义强大版的Pivot。根据官网的介绍,可以处理在短时间内处理很大的数据,可以使用DAX(数据分析表达式)来对数据进行分析处理,同时在拥有很多强大功能的同时,不会占用很大的内存和CPU,可以有效地利用内存和CPU.
传统透视表的数据来源可以是Excel工作表,也可以是分析服务中的多维数据集这两种主要的方式。相对前者由于数据是存储在Excel的工作表中,所以业务操作人员很容易上手,很适合小规模的数据统计分析。后者分析服务的多维数据集这种方式,由于数据是以一种特殊的方式聚合在独特的文件系统中,所以适合大规模的数据量分析,缺点是分析服务的开发对于IT的要求比较高,只能由IT人员完成,所以业务人员的一个需求往往会等待很长的时间才会得到响应。
那么,业务操作人员是否可以有一种高性能的去分析稍微大一点的规模的数据呢?PowerPivot就是微软提供的一个方案。在这个方案中,数据直接加载到内存当中,并且经过一定的优化,保证了通过透视表的统计有一个很高的性能。
首先,在Excel 2013之前的版本中,这个工具是需要单独下载的。如果你没有Office 2013,那么我建议你的版本不要低于2010,在这个版本之中PowerPivot的版本得以演化。
下载需要留意Excel对应的语言版本还有是32位版还是64位版。
还有需要注意的一个地方是,这个是PovitTable是针对 Excel 2010的第二个版本,之前还有一个版本,在微软目前的教程以及本文的介绍中缺失了部分功能。所以如果你已经先前安装了PowerPivot,请务必确认这个版本是否正确。
安装完毕后,打开Excel后,可以看到Ribbon菜单中多了一项:
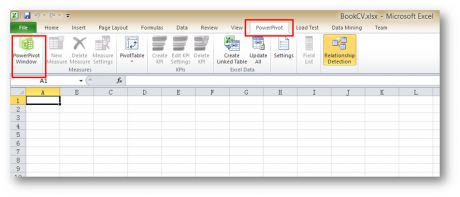
使用这个工具前,需要先准备数据。你可以直接使用在 Excel工作表里面的数据,也可以使用SQLServer等其它数据源的数据。
这里假定一个销售部门的数据,已经在IT部门的数据仓库中存在了,而销售分析人员,只需要把相关的数据导入到PowerPivot中,然后通过简单的设置就可以生成自己的分析模型了。
在PowerPivot选项卡中单击powerpoint Window,会打开PowerPivot工具:
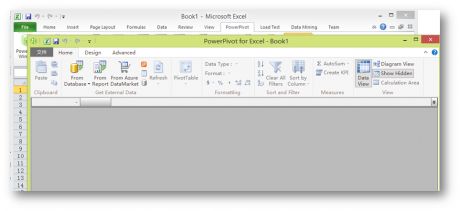
假定IT部门已经授予了销售分析部门的数据仓库系统部分响应表的访问权限,那么这里分析人员需要做的就是把相应的表导入到PivotTable工具中。
点击上图工具栏中的From Database:

选择From sql server。从这里可以看到,PowerPivot支持的数据源很多,还有Access和SSAS等。
在弹出的表导入工具中,输入数据仓库所在的服务器名称和数据仓库的名称。
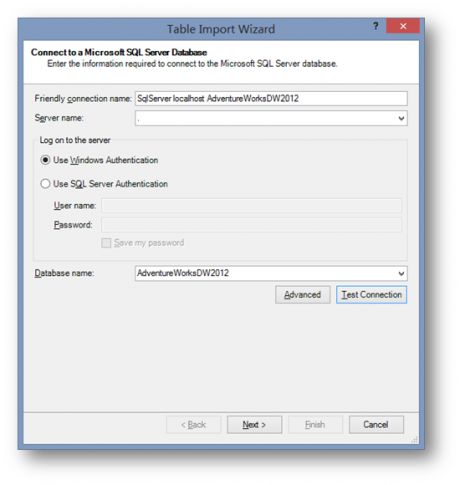
这里我们使用微软的示例数据库Adventure Works来做演示,关于如何获取和部署这些示例,可以参考我的这篇随笔。
设置好连接信息后,点击Next。

接下来的界面会指定如何导入数据,是通过选取表或者视图的方式,还是一个查询的方式。这里选择第一个,点Next。
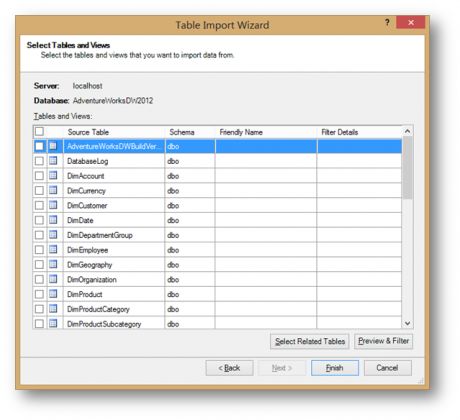
在数据仓库下的所有表被列了出来。在这个界面中,可以通过Friendly Name来指定一个友好名称,然后通过Filter Details指定需要表里的哪些列。
这里假定销售人员要做Internet Sales分析,在列表里直接找到FactInternetSales表:

这张表是分析用的事实表,然后需要指定相关的维度表。
在PowerPivot有一个很赞的功能就是Selected Related Tables,选择相关表。假如在数据仓库中已经定义好了主外键关系(现在似乎很少有人愿意这么做,但我觉得定义好还是一个不错的习惯),那么在这里面会直接检测到,并且自动勾选上那些维表。点击这个按钮后,可以发现很多Dim开头的维表已经都被选中了。
实际的操作中,还是建议这里给每一个表都指定一个Friendly Name,并且做适应的Filter。但这里为了演示方便直接点Finish开始导入数据。
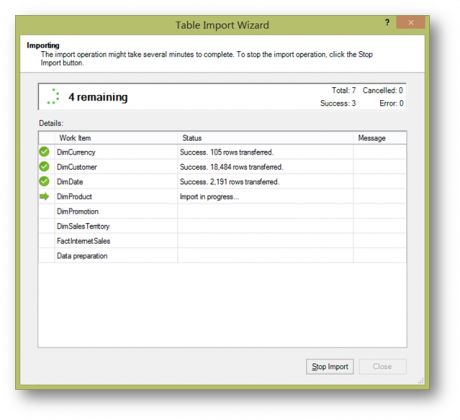
工具开始把数据仓库里的数据加载到PowerPivot中。完成后点击Close关闭这个界面。

然后就可以看到被导入进来的表。
在实际环境中,数据仓库里额数据是每天都在发生变化的,那么如何保持PowerPivot里的数据跟数据仓库的数据保持同步呢?

如图单击Refresh All,PowerPivot就会根据先前的连接设置重新加载这些数据。
导入完毕后,把界面切换到Diagram模式:

界面会从数据视图切换到Diagram模式(顺便说一下,Excel 的第一个PowerPivot版是没有这个Diagram功能的,这也就是为什么前边提到一定要确定是第二版):

在这个关系视图里继承了数据仓库中定义的主外键结构(熟悉SSAS的同学可以把这里理解为数据源视图的定义)。
假如实际环境中,数据仓库没有定义这部分内容,就需要自己来指定表之间的关系(这个过程对于开发SSAS的朋友来说,更像是在指定”维度用法”)。而方法很简单,假如我要建立FactInternetSales表中ProductKey和DimProduct中的ProductKey列的主外键关系,只需拖拽FactInternetSales表中的ProductKey字段到DimProduct表中的ProductKey字段就可以了。
接下来指定一个层次结构。建立层次结构的好处在于,可以方便在后续的透视表操作中,方便维度属性的导航,比如对于区域维度的,从大洲到国家到省再到市,或者一个时间维度的从年到半年再到季度然后月份和天的导航。这里我们在DimDate表中定义一个年月日的层次结构导航关系。
右键DimDate表,选择Create Hierarchy:
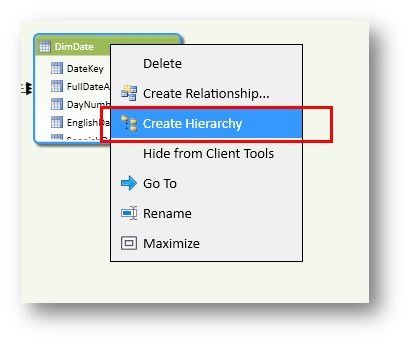
然后,可以看到在表的后面加入了一个新”列”。
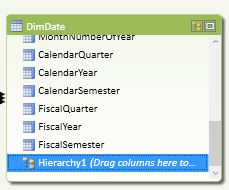
重命名这个Hierarchy的名称为DateHierarchy。
然后,一次拖拽表中的如下列到这个新建的层次中:
CalendarYear
EnglishMonthName
DayNumberOfMonth
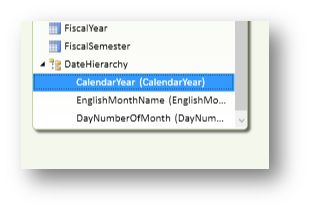
为了显示的友好性,右键层次中的CalendarYear,选择Rename将其重命名为Year,然后依次命名其它层次为Month和Day。

基本的分析模型建立完毕之后,就可以在透视表中浏览这些数据了。
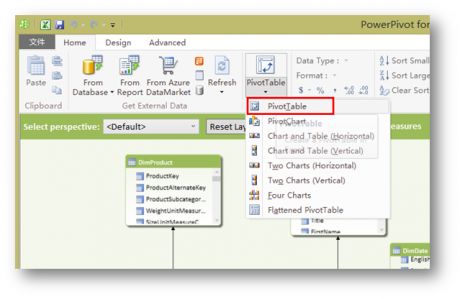
如图,在PivotTable界面中Home标签点击PivotTable然后选择其下的PivotTable。

系统会提示问透视表在新建一个工作表中还是在现有工作表的一个区域,这里选择新建。

然后,可以看到熟悉的透视表,并且这个透视表自动连接到了PowerPivot里的数据。
实际上这种模式中还有一个PowerPivot Filed List,点击上图中的Filed List:

可以看到PowerPivot的Filed List要比传统的透视表Filed List多了两个切片器。通过它们可以更明了的进行数据切片分析。
比如,要分析销售出去的产品中,各个颜色的数据以分析用户对于颜色的偏好:

拖拽DimProduct的Color到Slicers Vertial,DimDate的DateHierarchy到Row Labels,FactInternetSales的Sum of SalesAmount到Values。
图中可以看到Color切片器,通过这个切片器里不同颜色的选择,可以在透视表中依次看到不同颜色的产品分别的销售额是多少。通过这种切片分析的方法,比透视表中的Report Filter会更直观一些。
并且可以看到,由于刚才对DimDate建立了一个层次,所以在透视表中使用它的时候,时间变成了可以展开的模式。
以上,一个简单的分析模型创建完毕,接下来的分析操作跟传统的透视表操作是一样的了,这里不做详细介绍。
如本文开头所描述,跟传统的透视表相比,PowerPivot是把数据加载到内存中的,从任务管理器中我们可以看到Excel此时的内存消耗:
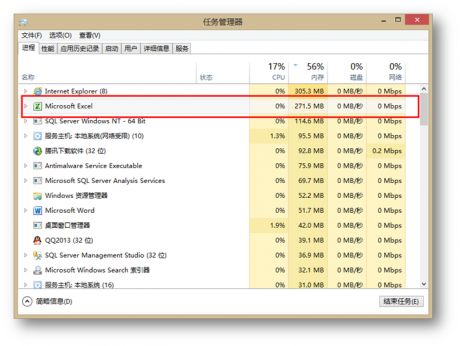
正因为数据是被加载到了内存,所以可以保证在数据量很多的情况下,通过透视表也可以进行快速的分析。但是,PowerPivot对数据两还是有一定的要求的,参考PowerPivot容量规范:
http://technet.microsoft.com/zh-cn/library/gg413465.aspx
里面有如下描述:

也就是说,PowerPivot能应付差不多20亿条的数据,但还是需要留意这个还要取决于你机器的内存大小。所以,对于中等规模的数据分析,PowerPivot还是很合适不过的,而对于更大一点规模额数据,自然用PowerPivot去连接分析服务数据库是最合适不过的了。具体采用哪一种方案,还需要根据这些方案不同的特点具体情况具体分析。
[quick-chat room=”PowerPivot”]
转载于:http://www.17bigdata.com/使用powerpivot建立简单的分析模型.html