自学python网络爬虫,从小白快速成长,分别实现静态网页爬取,下载meiztu中图片;动态网页爬取,下载burberry官网所有当季新品图片。
文章目录
1.前言
2.知识储备
3.爬取静态网站
4.爬取动态网站
5.源代码
1.前言
近日疫情严重,手机已经玩吐了,闲着无聊逛衣服品牌官网发现,结果一时兴起,想学一学python,写一个爬虫下载官网所有最新上架的衣服图片和价格;说干就干,但身为一个只学过一些c和c++的python 零基础大二小白,csdn上的各种教程里涉及的各种发法、工具和库让我眼花缭乱;因此走了很多弯路,终于花三天时间完成了爬虫的设计实现。自己总结下来发现学习+上手其实 真的一点都不难!
今天我把自己的从零开始的所有经验记录下来,让所有想学爬虫但是面对各类教程不知所措的童鞋们能从中收获一二。
2.知识储备
-
python基本语法
-
尤其是列表、字典的操作
-
-
库(安装方式自行百度)
-
request库
主要用库中的get方法和post方法用来向指定的url(网址)请求数据,
import requests url = 'https://cn.burberry.com/service/shelf/mens-new-arrivals-new-in/' response = requests.get(url)值得注意的是,对于一些网页必须加入指定的headers,用来将你的爬虫伪装成阅览器,并添加一些重要的标志,否则网站不会让你访问它的数据,
User_Agent = 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:66.0) Gecko/20100101 Firefox/66.0' header = { 'User-agent':User_Agent, } response = requests.get(url,headers = header)另外,请求到的数据是requests类型,我们要对其进行分析,必须把它转化成bytes类型或者str类型,即
content = response.content #或者使用text属性得到相应字符串 #content = response.text这样就成功得到bytes类型的网站源代码啦!
接下来对该文本进行分析,怎么进行呢?有两个选择,一是正则表达式(比较难),二就是方便我们初学者使用的BeautifulSoup库啦!
但首先,我们需要安装使BeautifulSoup的使用更为方便快速的解码库lxml库 -
lxml库
用来为BeautifulSoup的初始化构造提供解码器。
-
BeautifulSoup库
主要使用库中的“构造函数”完成对bytes类型数据的格式化,即将其转化为可以利用库中方法进行检索的对象
import lxml from bs4 import BeautifulSoup soup = BeautifulSoup(content,'lxml')之后便可以利用库中的find 和 find_all方法,用来找源码中相应的标签! 举个栗子,下面是burberry官网的源码截图,
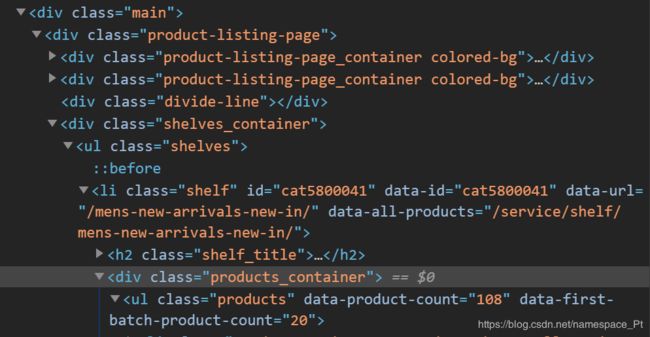
假设我们已经构造好了其BeautifulSoup类型的对象soup,
现在我们想从中找到加亮的那一行代码,首先明确其 标签 是 div, 其中class = xxx* 为该标签下的 属性,那么我们就用find函数来找:target = soup.find(name = 'div',attrs = {'class':'productts_container'}) #name代表着标签的名称 #attrs是属性的字典,class是属性名,product_container是该属性的值 #如果只匹配name,不匹配属性,会找错,因为find默认返回第一个 #找到匹配的值,而加亮代码行上面也有名为div的标签,因此必须匹配独一无二的属性值得注意的是,find函数返回的是BeautifulSoup类型的对象,如果想要访问其中的某项属性,需要使用attrs[]方法,例如现在我们要访问上述的class属性值:
class_result = target.attrs['class'] #attrs可以省略 #class_result = target['class'] print(class_result) #products_containerfind_all函数的调用方法和find函数相同,传入参数也一样,只不过find_all会找到所有匹配的项,并将其构建为一个列表
-
-
JSON文件基础
-
在爬取动态网页时会用到,我理解其为字典的列表,其中字典有嵌套的结构
-
具体可参考
-
3.爬取静态网站
-
流程(我们遵循csdn传统~以下载https://www.mzitu.com/221136每一页图片为例,内容不重要!学习才是根本目的)
1.我们看到网站的每一页图片都是加载好的,即没有***查看更多***等按钮,也不会随着鼠标 滚轮拖动而加载新的内容,所以是静态网页。
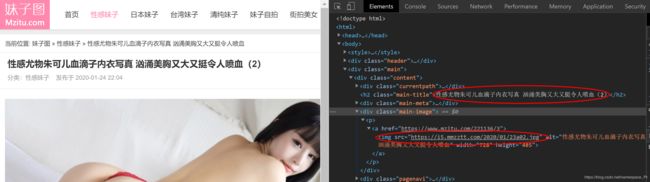
2.用开发人员工具f12分析原网页,一步步找到要爬的图片所在的位置,如图,一个红圈是标题,一个红圈是图片所在的url,一个是当前页数,一个是总页数
- 发现标题是在名为h2的标签的字符串,并且该标签有class属性,其值为main-title
- 同时图片的url存在名为img的标签的src属性里,并且该img标签还有属性alt,其值和标题相同
- 我们不关心当前是第几页,只需要获取页数上界,而页数存储在名为div,有属性class = pagenavi的标签的名为a的子标签的名为span的子标签的字符串里,而上界存在倒数第二个上述标签中(自己观察网页,发现最后一个存的是下一页)
3.分析网址的变化:
- 我们点进第二页图片,发现网站url在初始页的基础上添加了’/2’,如图:

- 同时第二页的标题、图片url所在位置都没有发生变化,如图:
- 再试一试能否通过在原url上添加’/1’能否访问到第一页,发现可以;至此,全部分析结束,开始写代码。
4.用requests库的get方法获得数据
import requests import lxml from bs4 import BeautifulSoup #引入库 url = 'https://www.mzitu.com/221136' header = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:66.0) Gecko/20100101 Firefox/66.0", "Referer":"https://www.mzitu.com/jiepai/comment-page-1/"} #header里必须设置Referer属性,否则无法下载图片 response = requests.get(url,headers = header) #请求网页4.将其构造为BeautifulSoup对象
bsobj = BeautifulSoup(content,'lxml') #解析html5.用find、find_all方法找到相应的数据
#get_text()方法获取中文字样,用string属性也可以 title = bsobj.find('h2',class_ = 'main-title').get_text() #按照分析出存储页数上界的位置寻找,存储其string属性即得最大页数 picture_max = bsobj.find('div',class_ = 'pagenavi').find_all('a')[-2].string #按照分析出的网址变化形式逐页访问 for i in range(1,int(picture_max)): href = url + '/' + str(i) #访问每一页 response = requests.get(href,headers = header) #请求数据 content = response.content #得到二进制对象 soup = BeautifulSoup(content,'lxml') #初始化 #找img标签,访问src属性,找图片url picture_url = soup.find('img',alt = title).attrs['src'] #访问图片url response_img = requests.get(picture_url['src'],headers = header) #获取二进制图片文件 content_img = response_img.content #命名文件,注意加.jpg file_name = title + '-' + str(i) + '.jpg' #写入,注意以二进制写入方式打开 with open(file_name,'wb') as f: f.write(content_img)不出意外,会在代码所在目录下得到44张图片yeah!
现在我们已经完成了对静态网站的爬取,是不是很简单啊!那么好学的我们肯定不满足于此啦,现在的大部分网站都有动态加载的功能,具体实现机制可以自行学习,有了上述的知识储备和简单实践,动态网页的爬取任务对我们也不过是piece of cake,那么就来试试吧!
4.爬取动态网站
-
流程(以下载burberry男士最新上架的图片为例)
1.点开网站发现有一个浏览全部按钮!怎么回事,打开f12康一康:
- 咦,为什么右边多了一堆没显示的东西,格式也和上面的不一样?而且为什么只有四张图片是和右边源码相匹配的,剩下的图片呢?
- 于是我们尝试点开浏览全部
- 哇塞,又多出来好多内容啊。。。这可怎么办?如果直接访问这个url,没有办法点开浏览全部的话,那撑死只能下载到源代码中最开始展示的寥寥几张图片,达不到我们想要下载全部最新上架图片的目的啊!
- 因此,我们也有了针对这一类动态加载时间的新的处理办法!
2.分析由点击浏览全部而触发的事件:
-
一般的,这一类动态加载都会由一个javascript或xhr触发,通过ajax将其内容(一般是json)异步加载到网页上来(这里说的都是我根据各教程学习后自己的理解,可能有不正确的地方,建议感兴趣的伙伴自行搜索,或者大神在评论区指点),我们的首要任务就是找到这个脚本:
1. 刷新网页后,f12,切换到network栏,选中JS
2.点击浏览全部,发现JS中没有新加载的项
3.再刷新界面,选中XHR
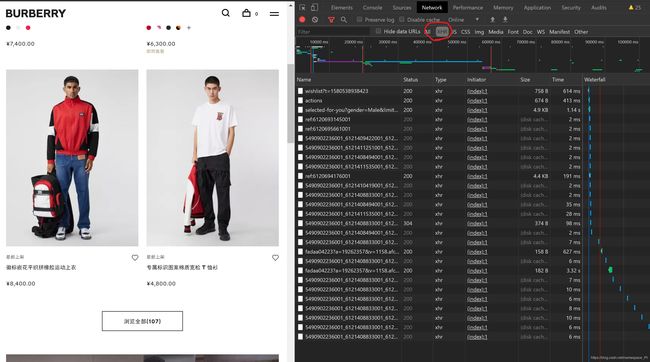
4.点击浏览全部按钮
咦,怎么瞬间多出来一项?之后又多出来好多项?!
原来这就是我们要找的脚本——也就是关键所在啦~ -
这个脚本的作用就是链接到一个新的url,该url指向一个json文件,然后把文件里的内容加载到了网页里!现在需要找出这个url,并且分析访问它的条件:
1.点击该脚本
发现其访问的url在General栏中已经给出,为https://cn.burberry.com/service/shelf/mens-new-arrivals-new-in/?_=1580538937924
但直接访问这个链接,发现不成功?!原来是网站自动过滤了我们的访问请求,因为我们给出的信息不足,人家不让看!那么怎么办呢?
简单!完善信息就行了!2.我们发现General里给出的Request Method是Get,那么我们就点开Request Headers进行分(fu)析(zhi)
在Request Headers栏中给出了一系列键值,我们把其中所有内容复制在我们爬虫的header里url = 'https://cn.burberry.com/service/shelf/mens-new-arrivals-new-in/?_=1580313287552' #User-Agent可以自定 USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:66.0) Gecko/20100101 Firefox/66.0" Cookie = '_ga=GA1.3.396709042.1580187372; Hm_lvt_0a183129752754c550277ef8f347c9a3=1580187372; mm-if-site-persist-ua-44=%5B%22Fredhopper%20Search%20vs%20ATG%20Search%3Dsearch%3Avariant%22%2C%22T103%20-%20For%20U%20Entrance_CN%3Dnavbarlink%3Avariant%22%5D; storeId=store_cn; language=zh_CN; burberryId=7bb25b00-418a-11ea-b799-55681cc34864_NULL_NULL; _cs_c=1; LPVID=Y5OTExZWZkN2E2ODU3MjJm; recentViewed=80255061; fita.sid.burberry_cn=_m_DQ-7-69P0cFThc2tobfutAzbPHGD4; sessionId=s%3AReNqxNlCK1NzYQoeLWwIj_coMlvnjpWk.0%2Bg%2FXkrRjQkaRGXI7EDgnCh%2BZFsWsJfMDSqfUwNsPI0; useFredhopperSearchApi=true; _gid=GA1.3.742106807.1580274394; favouritesUuid=1f8625c0-4255-11ea-a013-5bf3d8c0acce; mmapi.p.bid=%22lvsvwcgeu01%22; mmapi.p.srv=%22lvsvwcgeu01%22; mediamathReferralUrl=http%3A%2F%2Fcn.burberry.com%2Fmens-new-arrivals-new-in%2F; LPSID-6899673=mMKP-pQCSxW3XarPamAv-A; _gat=1; Hm_lpvt_0a183129752754c550277ef8f347c9a3=1580313289; mmapi.p.pd=%22-681797386%7CXAAAAApVAwBTKATmpxIU4AABEgABQgAP7o0iBQBakVOV06TXSIkNP2Wuo9dIAAAAAP%2F%2F%2F%2F%2F%2F%2F%2F%2F%2FAA9jbi5idXJiZXJyeS5jb20CpxIFAAAAAAAAAAAA5bYCAOW2AgDltgIAAwA4JAEAuJua%2FVenEgD%2F%2F%2F%2F%2FAacSqBL%2F%2FxcAAAEAAAAAAeDhAgDcqwMAAeW2AgAXAAAAAg4BAJjThIWOpxIA%2F%2F%2F%2F%2FwGnEqgS%2F%2F8XAAABAAAAAAGMpgIAkFsDAAHltgIAFwAAAPkeAQAuhS3GMKcSAP%2F%2F%2F%2F8BpxKoEv%2F%2FFwAAAQAAAAABnNMCAIOZAwAB5bYCABcAAAAAAAAAAAFF%22; _cs_id=2468e318-c811-a969-be08-20c949f87206.1580187380.7.1580313293.1580312933.1.1614351380113; _cs_s=5.1' Refer = 'https://cn.burberry.com/mens-new-arrivals-new-in/' header = { 'Authority':'cn.burberry.com', 'User-agent':USER_AGENT, 'Cookie':Cookie, 'Referer':Refer, 'Accept':'application/json, text/javascript, */*; q=0.01', 'Accept-encoding':'gzip, deflate, br', 'Accept-language':'zh-CN,zh;q=0.9', 'Sec-fetch-mode':'cors', 'Sec-fetch-site':'same-origin', 'X-csrf-token':'p6nTTTy3-IcLowOIEB_u1lbpowcTgZ3wVPkA', 'X-newrelic-id':'VwIOVFFUGwIJVldQBAQA', 'X-requested-with':'XMLHttpRequest' }这样我们就完善了信息!接下来进行访问!
-
访问脚本文件,将其下载到本地,并进行分析:
1.访问并下载
import requests from bs4 import BeautifulSoup #访问 web_response = requests.get(url,headers=header) #用text属性取得字符串,方便写入文件 web_text = web_response.text #web_content = web_response.content with open('html.json','w',encoding='utf-8') as f: f.write(web_text)2.利用线上json分析器对下载下来的一堆字符进行分析~即将html.json中的所有字符复制到网站中
人家把缩进啥的都给咱加好啦!我们要做的就是找数据!名称、价格和图片源~- 发现名称都存在label属性中
- 图片源url存在images的img属性中
- 价格存在price属性中
- 这样我们就找全啦,开始代码??
-
等等!我们想要完成的是任何时候运行代码就能得到所有最新上架,但是现在这个网页是固定死的呀!没办法让它保持更新,怎么办呢?
1.分析url,看到结尾的一长串数字,我们联想到时间,一查,果然,这是从1970-1-1一直到访问网页的时刻的总毫秒数,于是我们利用time库确定当前时间~并把url稍作修改:
import time #修正url,保留时间戳前的部分 url = 'https://cn.burberry.com/service/shelf/mens-new-arrivals-new-in/?_=' #获取当前时间 _time = int(time.time()*1000) #修改url url += str(_time)2.接下来就可以放心写代码啦
-
写代码
import json #定义保存路径,需要提前创建文件夹 savePath = 'C:/Users/Administrator/Pictures/Burberry_New_Arrivals/' def download(imgSrc,title): #定义文件名 fileName = savePath + title + '.jpg' #图片url img_url = 'http:' + imgSrc #访问 img_response = requests.get(img_url,headers = header) img_content = img_response.content #下载写入 with open(fileName,'wb') as file: file.write(img_content) #创建列表,存储信息 name_list = list() price_list = list() img_list = list() #将bytes类型读取为json类型 json_content = json.loads(web_content) #根据分析结果,找名称、价格、图片源 for item in json_content: #利用json的get方法找属性 name_list.append(item.get('label')) price_list.append(item.get('price')) img_list.append(item.get('images').get('img').get('src')) #利用zip打包三个列表 img_zip = zip(name_list,price_list,img_list) for each in img_zip: #用名称+价格作为标题 title = each[0] + str(each[1]) #下载 download(each[2],title)完成!
5.源代码
-
爬取静态网页spider.py
import requests import lxml import re from bs4 import BeautifulSoup url = 'https://www.mzitu.com/221136' header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:66.0) Gecko/20100101 Firefox/66.0", "Referer": "https://www.mzitu.com/jiepai/comment-page-1/" } response = requests.get(url, headers=header) # 请求网页 content = response.content # 获取html bsobj = BeautifulSoup(content, 'lxml') # 解析html title = bsobj.find('h2', class_='main-title').string # 需要用class_ picture_max = bsobj.find('div', class_='pagenavi').find_all('a')[-2].string # 一共多少张图 for i in range(1, int(picture_max)): href = url + '/' + str(i) # 访问每一页 response = requests.get(href, headers=header) # 请求数据 content = response.content # 得到二进制对象 soup = BeautifulSoup(content, 'lxml') # 初始化 # 找img标签,访问src属性,找图片url picture_url = soup.find('img', alt=title).attrs['src'] # 访问图片url response_img = requests.get(picture_url, headers=header) # 获取二进制图片文件 content_img = response_img.content # 命名文件,注意加.jpg file_name = title + '-' + str(i) + '.jpg' # 写入,注意以二进制写入方式打开 with open(file_name, 'wb') as f: f.write(content_img)-
爬取动态网页burberryInfo.py
import re import requests import lxml import random import json import time from bs4 import BeautifulSoup def download(imgSrc, title): fileName = savePath + title + '.jpg' img_url = 'http:' + imgSrc # print(img_url) img_response = requests.get(img_url, headers=header) img_content = img_response.content with open(fileName, 'wb') as file: file.write(img_content) url = 'https://cn.burberry.com/service/shelf/mens-new-arrivals-new-in/?_=' USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:66.0) Gecko/20100101 Firefox/66.0" Cookie = '_ga=GA1.3.396709042.1580187372; Hm_lvt_0a183129752754c550277ef8f347c9a3=1580187372; mm-if-site-persist-ua-44=%5B%22Fredhopper%20Search%20vs%20ATG%20Search%3Dsearch%3Avariant%22%2C%22T103%20-%20For%20U%20Entrance_CN%3Dnavbarlink%3Avariant%22%5D; storeId=store_cn; language=zh_CN; burberryId=7bb25b00-418a-11ea-b799-55681cc34864_NULL_NULL; _cs_c=1; LPVID=Y5OTExZWZkN2E2ODU3MjJm; recentViewed=80255061; fita.sid.burberry_cn=_m_DQ-7-69P0cFThc2tobfutAzbPHGD4; sessionId=s%3AReNqxNlCK1NzYQoeLWwIj_coMlvnjpWk.0%2Bg%2FXkrRjQkaRGXI7EDgnCh%2BZFsWsJfMDSqfUwNsPI0; useFredhopperSearchApi=true; _gid=GA1.3.742106807.1580274394; favouritesUuid=1f8625c0-4255-11ea-a013-5bf3d8c0acce; mmapi.p.bid=%22lvsvwcgeu01%22; mmapi.p.srv=%22lvsvwcgeu01%22; mediamathReferralUrl=http%3A%2F%2Fcn.burberry.com%2Fmens-new-arrivals-new-in%2F; LPSID-6899673=mMKP-pQCSxW3XarPamAv-A; _gat=1; Hm_lpvt_0a183129752754c550277ef8f347c9a3=1580313289; mmapi.p.pd=%22-681797386%7CXAAAAApVAwBTKATmpxIU4AABEgABQgAP7o0iBQBakVOV06TXSIkNP2Wuo9dIAAAAAP%2F%2F%2F%2F%2F%2F%2F%2F%2F%2FAA9jbi5idXJiZXJyeS5jb20CpxIFAAAAAAAAAAAA5bYCAOW2AgDltgIAAwA4JAEAuJua%2FVenEgD%2F%2F%2F%2F%2FAacSqBL%2F%2FxcAAAEAAAAAAeDhAgDcqwMAAeW2AgAXAAAAAg4BAJjThIWOpxIA%2F%2F%2F%2F%2FwGnEqgS%2F%2F8XAAABAAAAAAGMpgIAkFsDAAHltgIAFwAAAPkeAQAuhS3GMKcSAP%2F%2F%2F%2F8BpxKoEv%2F%2FFwAAAQAAAAABnNMCAIOZAwAB5bYCABcAAAAAAAAAAAFF%22; _cs_id=2468e318-c811-a969-be08-20c949f87206.1580187380.7.1580313293.1580312933.1.1614351380113; _cs_s=5.1' Refer = 'https://cn.burberry.com/mens-new-arrivals-new-in/' header = { 'Authority': 'cn.burberry.com', 'User-agent': USER_AGENT, 'Cookie': Cookie, 'Referer': Refer, 'Accept': 'application/json, text/javascript, */*; q=0.01', 'Accept-encoding': 'gzip, deflate, br', 'Accept-language': 'zh-CN,zh;q=0.9', 'Sec-fetch-mode': 'cors', 'Sec-fetch-site': 'same-origin', 'X-csrf-token': 'p6nTTTy3-IcLowOIEB_u1lbpowcTgZ3wVPkA', 'X-newrelic-id': 'VwIOVFFUGwIJVldQBAQA', 'X-requested-with': 'XMLHttpRequest' } _time = int(time.time()*1000) url += str(_time) # 定义保存路径,根据自己需要修改,需要提前创建文件夹 savePath = 'C:/Users/Pt/Pictures/Burberry_New_Arrivals/' # 访问 web_response = requests.get(url, headers=header) web_content = web_response.content # 用text属性取得字符串,方便写入文件 # web_text = web_response.text # with open('html3.json','w',encoding='utf-8') as f: # f.write(web_content) # 创建列表,存储信息 name_list = list() price_list = list() img_list = list() # 将bytes类型读取为json类型 json_content = json.loads(web_content) # 根据分析结果,找名称、价格、图片源 for item in json_content: #利用json的get方法找属性 name_list.append(item.get('label')) price_list.append(item.get('price')) img_list.append(item.get('images').get('img').get('src')) # 利用zip打包三个列表 img_zip = zip(name_list,price_list,img_list) for each in img_zip: # 用名称+价格作为标题 title = each[0] + str(each[1]) # 下载 download(each[2],title) -