sqlserver非聚聚索引原理
本文所使用的测试数据库:SQLSERVER2012
非聚集索引和聚集索引都是B+树数据类型,但是在存储上有很大的区别。下面我们通过创建测试表来研究一下非聚集索引的存储结构。
CREATE TABLE [dbo].[Department8](
[DepartmentID] [int] IDENTITY(1,1) NOT NULL,
[Name] [nvarchar](200) NOT NULL,
[GroupName] [nvarchar](200) NOT NULL,
[Company] [nvarchar](300) NULL,
[ModifiedDate] [datetime] NOT NULL
)创建非聚集索引:
CREATE NONCLUSTERED INDEX [NCL_Name_GroupName] ON [dbo].[Department8]
(
[Name] ASC,
[GroupName] ASC
)向数据表中插入10万条数据
declare @i int=0;
while @i<100000
begin
insert into Department8(Name,GroupName,Company,ModifiedDate)
values('销售部'+convert(varchar(50),@i),'销售组'+convert(varchar(50),@i),'中国你好有限公司XX分公司',getdate())
set @i=@i+1
end创建一个表来存储Department8表的内部数据存储结构:
CREATE TABLE [dbo].[DBCCResult8](
[PageFID] [nvarchar](200) NULL,
[PagePID] [nvarchar](200) NULL,
[IAMFID] [nvarchar](200) NULL,
[IAMPID] [nvarchar](200) NULL,
[ObjectID] [nvarchar](200) NULL,
[IndexID] [nvarchar](200) NULL,
[PartitionNumber] [nvarchar](200) NULL,
[PartitionID] [nvarchar](200) NULL,
[iam_chain_type] [nvarchar](200) NULL,
[PageType] [nvarchar](200) NULL,
[IndexLevel] [nvarchar](200) NULL,
[NextPageFID] [nvarchar](200) NULL,
[NextPagePID] [nvarchar](200) NULL,
[PrevPageFID] [nvarchar](200) NULL,
[PrevPagePID] [nvarchar](200) NULL
) 将Department8表的内部数据存储结构信息插入到表DBCCResult8中:
insert into [dbo].[DBCCResult8] exec('dbcc ind(indextest,Department8,-1)')下面我们来分析一下表DBCCResult8的数据:

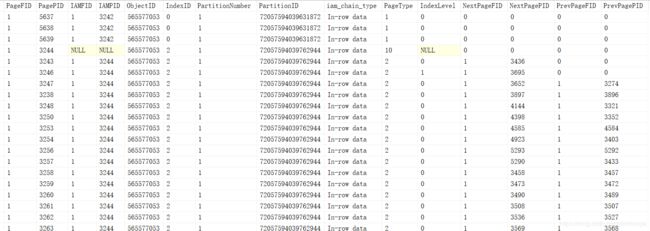
因为数据页太多,索引只截取了2部分有意义的数据。
PageType:10:IAM页面;1:数据页面;2:索引页面
IndexID:0:堆;1:聚集索引;2-255:非聚集索引
IndexLevel:页面所在树的层级,0表示叶子节点,即数据页
第一张图PageType=1,IndexID=0,IndexLevel=0,表示非聚集索引的数据页在堆表中,而聚集索引的数据页在叶子节点中
第二张图PageType=2,IndexID=2,IndexLevel=0,表示这些页面都是索引页
下面我们先来看看索引页有哪些信息:
dbcc traceon(3604,-1)
dbcc page('indextest',1,3243,3)dbcc traceon(3604,-1)这个命令用来打开跟踪标志;dbcc page这个命令用来显示页面3243的页面信息。在我的电脑上3243是我随机选择的一个索引页,大家可根据自己电脑上页面信息自行修改这个页号。

可以看到这个索引页存储了Name和GroupName,还有RID,RID即指向堆表中对应行的指针。KeyHashValue是用哈希函数根据非聚集索引的第一个列的键值生成的散列值。
在讲聚集索引的时候我们说过,聚集索引只能定位到一个页面,然后在页面中查找要搜索的值。而非聚集索引可以用RID直接定位到行。也就是说非聚集索引里包含了数据表中多有的行,数据表有多少行非聚集索引就有多少行,只是非聚集索引只包含了创建非聚集索引时所用的列。当数据量很少的时候,数据库会使用全表扫描,因为全表扫描能查出更多的列。
下面我们可以测试一下,新建一个Department9,数据结构和Department8一模一样,和Department8建一样的索引,使用同样的查询语句。唯一的区别就是Department9表只插入的10条数据,而Department8表里有10万条记录。使用执行计划分析的结果如下:
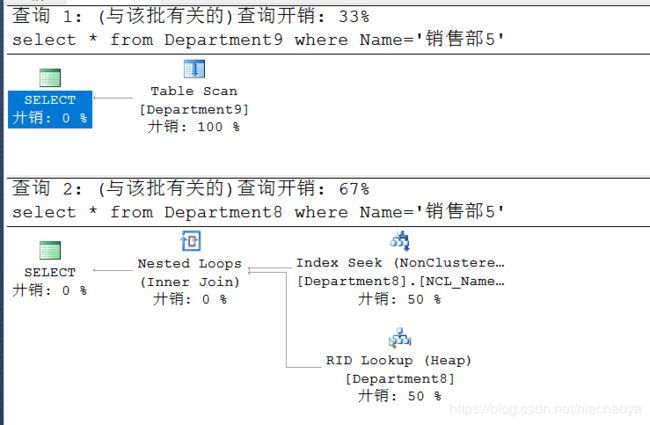
数据量少的走的全表扫描,而数据量大的走的是非聚集索引扫描和书签查找。
我们创建非聚集索引的时候一般会创建多个列的索引,即复合索引。
在使用复合索引查找的时候有一点千万要注意:创建复合索引的第一列必须包含在where查询字段中,否则不会走非聚集索引查找。我们来做个测试:
select GroupName from [dbo].[Department8] where GroupName='销售组9'
GroupName是索引的第二个字段,所以走的是非聚集索引扫描,而不是查找
select GroupName from [dbo].[Department8] where GroupName='销售组9' and Name='销售部9'
这个查询因为加上了列Name,所以走的是非聚集索引查找。注意Name在where查询字段中的顺序并不会影响查询优化器对索引的选择。
覆盖索引
关于覆盖索引的介绍,msdn上给出了详细的解释和用法:https://docs.microsoft.com/zh-cn/previous-versions/sql/sql-server-2005/ms190806(v=sql.90)