28.Spring Cloud Sleuth追踪数据存储
前面的演示,ZipkinServer是将数据存储在内存中。这种方式一般不适用于生产环境。因为一直Zipkinserver重启或发生崩溃,就会导致历史数据丢失。
ZipkinServer支持多后端存储。列如mysql,Elasticsearch.其实现是通过消息中间件rabbitmq,kafka收集数据,然后存储到mysql中。这里只需要改造ZipkinServer,各个微服务和之前通过消息中间件收集数据一样。
ZipkinServer-mysql
pom.xml
io.zipkin.java
zipkin-autoconfigure-ui
io.zipkin.java
zipkin-server
org.springframework.cloud
spring-cloud-stream-binder-rabbit
org.springframework.cloud
spring-cloud-sleuth-zipkin-stream
org.springframework.boot
spring-boot-starter-jdbc
mysql
mysql-connector-java
application.properties
server.port=9411
#注册中心地址
eureka.client.serviceUrl.defaultZone=http://testhost:8000/eureka/,http://testhost2:8001/eureka/
#把客户端的检测检测交给actuator来完成
eureka.client.healthcheck.enabled=true
spring.application.name=zipkin-server
#rabiitmq
spring.rabbitmq.host=localhost
spring.rabbitmq.port=5672
spring.rabbitmq.username=springcloud
spring.rabbitmq.password=123456
#将trace信息持久化到mysql中
spring.datasource.schema=classpath:/mysql.sql
spring.datasource.url=jdbc:mysql://localhost:3306/bootdb
spring.datasource.username=root
spring.datasource.password=123456
spring.datasource.initialize=true
spring.datasource.continueOnError=true
spring.sleuth.enabled=false
zipkin.storage.type=mysql
mysql脚本
CREATE TABLE IF NOT EXISTS zipkin_spans (
`trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit',
`trace_id` BIGINT NOT NULL,
`id` BIGINT NOT NULL,
`name` VARCHAR(255) NOT NULL,
`parent_id` BIGINT,
`debug` BIT(1),
`start_ts` BIGINT COMMENT 'Span.timestamp(): epoch micros used for endTs query and to implement TTL',
`duration` BIGINT COMMENT 'Span.duration(): micros used for minDuration and maxDuration query'
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
ALTER TABLE zipkin_spans ADD UNIQUE KEY(`trace_id_high`, `trace_id`, `id`) COMMENT 'ignore insert on duplicate';
ALTER TABLE zipkin_spans ADD INDEX(`trace_id_high`, `trace_id`, `id`) COMMENT 'for joining with zipkin_annotations';
ALTER TABLE zipkin_spans ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTracesByIds';
ALTER TABLE zipkin_spans ADD INDEX(`name`) COMMENT 'for getTraces and getSpanNames';
ALTER TABLE zipkin_spans ADD INDEX(`start_ts`) COMMENT 'for getTraces ordering and range';
CREATE TABLE IF NOT EXISTS zipkin_annotations (
`trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit',
`trace_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.trace_id',
`span_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.id',
`a_key` VARCHAR(255) NOT NULL COMMENT 'BinaryAnnotation.key or Annotation.value if type == -1',
`a_value` BLOB COMMENT 'BinaryAnnotation.value(), which must be smaller than 64KB',
`a_type` INT NOT NULL COMMENT 'BinaryAnnotation.type() or -1 if Annotation',
`a_timestamp` BIGINT COMMENT 'Used to implement TTL; Annotation.timestamp or zipkin_spans.timestamp',
`endpoint_ipv4` INT COMMENT 'Null when Binary/Annotation.endpoint is null',
`endpoint_ipv6` BINARY(16) COMMENT 'Null when Binary/Annotation.endpoint is null, or no IPv6 address',
`endpoint_port` SMALLINT COMMENT 'Null when Binary/Annotation.endpoint is null',
`endpoint_service_name` VARCHAR(255) COMMENT 'Null when Binary/Annotation.endpoint is null'
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
ALTER TABLE zipkin_annotations ADD UNIQUE KEY(`trace_id_high`, `trace_id`, `span_id`, `a_key`, `a_timestamp`) COMMENT 'Ignore insert on duplicate';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`, `span_id`) COMMENT 'for joining with zipkin_spans';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTraces/ByIds';
ALTER TABLE zipkin_annotations ADD INDEX(`endpoint_service_name`) COMMENT 'for getTraces and getServiceNames';
ALTER TABLE zipkin_annotations ADD INDEX(`a_type`) COMMENT 'for getTraces';
ALTER TABLE zipkin_annotations ADD INDEX(`a_key`) COMMENT 'for getTraces';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id`, `span_id`, `a_key`) COMMENT 'for dependencies job';
CREATE TABLE IF NOT EXISTS zipkin_dependencies (
`day` DATE NOT NULL,
`parent` VARCHAR(255) NOT NULL,
`child` VARCHAR(255) NOT NULL,
`call_count` BIGINT,
`error_count` BIGINT
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
启动类
package com.niugang;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
import org.springframework.cloud.sleuth.zipkin.stream.EnableZipkinStreamServer;
/**
* zipserver启动类
* @author niugang
*
*/
@SpringBootApplication
@EnableDiscoveryClient
@EnableZipkinStreamServer
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
启动注册中心,zipkinserver,各个微服务。查看数据库。
![]() 生成三张存储表
生成三张存储表
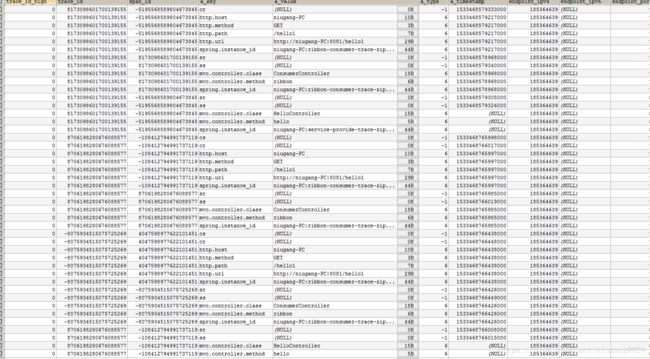
追踪添加的数据
ZipkinServer-Elasticsearch
在使用Elasticsearch是一定要和springcloud spring-cloud-sleuth zipkin版本兼容。用Elasticsearch6.x因为去掉了string类型,追踪的数据无法存储,所以又切回到了Elasticsearch2.3
1.pom.xml
io.zipkin.java
zipkin-autoconfigure-ui
io.zipkin.java
zipkin-server
org.springframework.cloud
spring-cloud-stream-binder-rabbit
org.springframework.cloud
spring-cloud-sleuth-zipkin-stream
io.zipkin.java
zipkin-autoconfigure-storage-elasticsearch-http
1.14.3
2.application.properties
server.port=9411
#注册中心地址
eureka.client.serviceUrl.defaultZone=http://testhost:8000/eureka/,http://testhost2:8001/eureka/
#把客户端的检测检测交给actuator来完成
eureka.client.healthcheck.enabled=true
spring.application.name=zipkin-server
#rabiitmq
spring.rabbitmq.host=localhost
spring.rabbitmq.port=5672
spring.rabbitmq.username=springcloud
spring.rabbitmq.password=123456
#将trace信息持久化到elasticsearch中
#zipkin.autoconfigure.storage.elasticsearch.http.ZipkinElasticsearchHttpStorageProperties 配置属性
zipkin.storage.type=elasticsearch
zipkin.storage.elasticsearch.cluster=elasticsearch
zipkin.storage.elasticsearch.hosts=http://localhost:9200
#默认index就是zipkin
zipkin.storage.elasticsearch.index=zipkin3.启动类
package com.niugang;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;
import org.springframework.cloud.sleuth.zipkin.stream.EnableZipkinStreamServer;
/**
* zipserver启动类
* @author niugang
*
*/
@SpringBootApplication
@EnableDiscoveryClient
@EnableZipkinStreamServer
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
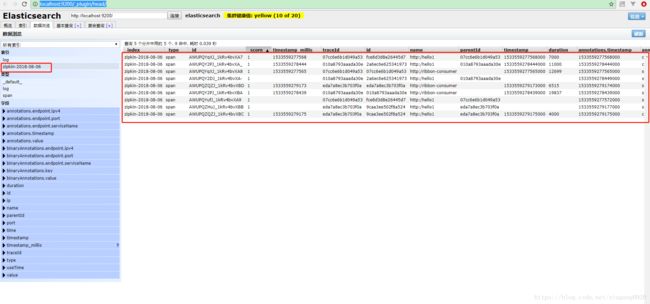
启动Elasticsearch,rabbitmq,注册中心,各个微服务发送请求,产生追踪数据。访问http://localhost:9200/_plugin/head/
微信公众号:

JAVA程序猿成长之路
分享资源,记录程序猿成长点滴。专注于Java,Spring,SpringBoot,SpringCloud,分布式,微服务。