第23部分- Linux ARM汇编ARM32到ARM64迁移
第23部分- Linux ARM汇编ARM32到ARM64迁移
1、在32位ARM系统中,可以通过指令本身中的条件字段来支持的分支判断。 例如在T32中,有用于构建条件序列的IT(如果-则-then)指令。 A64不支持此功能,但有一组不同的特定条件说明。
2、64位仍可以对第二个操作数进行移位,旋转和符号扩展或零扩展,但A64位不支持以相同的方式将移位和旋转操作“嵌入”到数据处理指令中。
3、通常不再可以访问程序计数器(PC)。 特别是,它不能像其他通用寄存器一样被读取或修改。 有伪指令可用于间接使用它(例如,在运行时生成相对于PC的地址)。
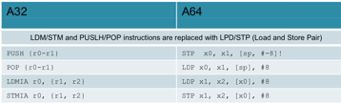
4、加载和存储多条指令已被加载和存储成对的64位寄存器的指令所取代。 它们也用于堆栈操作,以代替早期的PUSH和POP。
5、NEON架构区别,32位时候
是

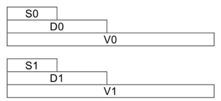
S0是D0的下半部分,是V0的下半部分。 S1是D1的下半部分,它是V1的下半部分,依此类推。 这消除了编译器在自动向量化高级代码时遇到的许多问题。
指令集
指令集,A64添加了将加载或存储与内存屏障结合在一起的加载获取(LDAR)和存储释放(STLR)指令。 简化了关键部分的实施。
另外,指令级别的可选加密加速支持。 这些指令在向量库上运行,提供了常见的构建块操作,可有效实现例如 AES和SHA加密算法。
与早期版本的指令集不同,A64不支持有条件地执行单个指令(例如ARM指令集)或指令组(例如Thumb指令集)。 相反,它支持一系列指令(如CSINC –条件选择和增量),其行为由条件代码标志的当前状态修改。 再加上全套的条件分支,这些使得控制流程非常紧凑和高效。
内存模式
普通内存中支持用于加载和存储的未对齐访问(只有极少数例外,例如“加载和存储独占”指令)。
尽管可以为Big-endian支持而构建数据接口,但是数据和指令接口本来就是little-endian。尽管单个应用程序无法更改其自己的字节序,但是操作系统可以同时托管big-endian和little-endian应用程序。
有更多的预加载提示说明。这些允许预加载以进行加载和存储,并提供有关是否应缓存预加载数据的提示。
一对“单向”屏障指令,即Load-Acquire(LDAR)和Store-Release(STLR),比DMB / DSB具有更大的灵活性。下面的“汇编代码”部分显示了一个示例。
AArch64不支持强排序的内存(在ARMv7-A中已弃用),并且设备内存已获得一些额外的功能以使其更加灵活(能够为收集,重新排序和早期写入确认定义各自的限制) 。
重编译或重写
在大多数情况下,目标是使前者最大化而使后者最小化。
好消息是,很多代码将简单地重新编译。 但是,由于许多基本类型的大小将发生变化,因此需要谨慎行事。 尽管编写良好的C代码不应对单个类型的大小有很多依赖性,但是不可避免地会遇到一些。
最佳实践必须是在重新编译时启用所有警告和错误,并确保您注意到编译器的所有警告问题,即使代码看起来没有编译器错误。
特别要特别注意代码中的任何显式类型转换,因为当基础类型的大小更改时,这些类型转换通常是错误的来源。
编译选项
--cpu 8A.32
--cpu 8A.32.crypto
--cpu 8A.32.no_neon
--cpu 8A.64
--cpu 8A.64.crypto
--cpu 8A.64.no_neon
在ARMv8-A中为A32进行编译(将以AArch32状态执行的代码)与为ARMv7-A进行编译非常相似。 为A32编译的代码将能够利用一些新指令(例如“加载获取和存储发行版”),并且避免使用ARMv7-A中已弃用但现在已在A32中删除的指令(例如SWP)。
使用no_neon选项进行编译将避免使用NEON / VFP指令或寄存器。 对于其中SIMD单元永远不会通电的系统或对于特定的代码段(例如,重置代码和异常处理程序)而言,这对于确保不使用NEON / VFP非常重要,这可能很有用。
ARMv8编译有关的预定义宏
编译器定义了许多预处理器宏,这些宏可在确定当前编译选项时使用。
__a32__
__a64__
__arm__
__thumb__
__t32__
可选特性:
__ARM_NEON__
__TARGET_ARCH_8_A
__TARGET_PROFILE_A
汇编代码
汇编代码只能重写没有办法。有差异的地方:
需要注意的事,64位APCS需要128位堆栈对齐。
这解释了为什么在表的A64示例中使用X寄存器(因为推入/弹出一对W寄存器将无法保持对齐)。
CPSR被PSTATE中的命名字段替换。

跳转指令

函数返回

注意,在某些情况下,仍然可以通过将地址直接复制到程序计数器来分支。
但是,RET指令向处理器提供了一个明确的提示,即分支是函数返回这可以大大改善分支预测(通过使用返回堆栈)。
浮点和NEON
浮点指令和NEON指令包含在主指令集中(而不是像以前的体系结构那样以协处理器为目标)。
意味着这些指令直接设置核心条件标志(NZCV),而不是具有单独的状态标志集。 使用NEON / FP寄存器组时,这使得混合控制和数据流变得更加容易。
堆栈指针
堆栈指针和零寄存器均通过ARM内核寄存器31进行编码。只有很少的指令将此编码识别为堆栈指针(其余部分将其视为零寄存器)。 以下说明可以访问堆栈指针:
- 所有加载和存储都可以使用SP作为基本寄存器
- AND,ORR和EOR(具有立即数和不具有标志设置)可以将SP用作目标
- 具有立即数的ADD / SUB可以将SP用作目标或第一个操作数
- ADD / SUB扩展可以将SP用作目标或第一个操作数
值得注意的是,某些指令(例如CMP)是这些指令的别名,也可以以相同的方式访问SP。
使用LDP / STP指令进行PUSH和POP操作。
这些示例显示涉及64位X寄存器对的传输,因为传输32位W寄存器对将不会保留堆栈指针的128位对齐。 当然可以使用PUSH / POP W寄存器,但是需要将它们以4组为一组进行传输以保持对齐。 但是,不能简单地将堆栈指针作为两对进行传输,每次将堆栈指针更新为8个字节,因为第二条指令将不使用对齐的堆栈指针值,而这将被硬件捕获。
// PUSH (w0, w1, w2, w3)
STP w3, w2, [sp, #-16]! // push first pair, create space for second STP w1, w0, [sp, #8] // push second pair
地址模式
A64加载和存储指令的一个重要特征是寻址模式与寄存器类型正交。
例如,对NEON / FP寄存器之一的加载与对内核寄存器的整数加载具有相同的寻址模式,范围和功能。
此外,NEON / FP寄存器组还支持与A32类似的解交织或“结构化”加载和存储指令。
Zero寄存器
零寄存器简化了许多指令的编码。它始终读为零,并忽略写入。 这意味着CMP指令可被编码为SUB,以零寄存器为目标。
LDAR和STLR
这些新指令起到“单向”barrier的作用,并且可以简化某些需要barrier的情况。
例如,按以下顺序,在LDAR之后观察到LDAR之后的所有访问,而LDAR之前的访问不受影响。
LDR ; these two accesses may be observed after the LDAR STR
LDAR ; “barrier” which affects subsequent accesses only
LDR ; these accesses must be observed after LDAR
STR
同理:
LDR ; these two accesses must be observed before STLR STR
STLR ; “barrier” which affects prior accesses only
LDR ; these accesses may be observed before STLR
STR
通用语言问题
64位的AAPCS大量使用了额外的寄存器,以提高过程调用的效率。

有8个64位寄存器可用于传递参数和返回结果。 通常,单个64位结果在X0中返回,或者单个128位结果在X1:X0中返回。 X8被指定为XR(间接结果位置参数),并且可以由调用方传递以指向用于返回结构的内存区域。
X9至X15这七个寄存器可被调用的函数破坏,因此可用作暂存空间。
IP0和IP1(过程内调用临时寄存器)可用于例如 单板或分支孤岛在过程调用中。 他们否则是可破坏的
平台寄存器(Platform Register,PR)保留供特定的ABI特定使用,分配器不得将其用于任何其他目的。 如果在特定平台上不需要PR,则可以将PR用作暂存器,但此类代码不一定可移植到其他平台。
X19-X28被指定为已保存被调用方,因此必须通过函数调用保留。
帧指针(X29)用于链接堆栈帧。
尽管不能用作通用寄存器,但是堆栈指针必须在任何公共接口处对齐16字节。 在用于访问内存的任何位置,它还必须对齐16字节。 这是在硬件中强制执行的。 请注意,对齐检查在堆栈指针上,而不在实际访问的地址上。
下表显示了为A32和LP64编译C代码时的内置类型。

只要代码以可移植的方式使用了指针(例如,从未将指针存储在int变量中,并且从未将指针转换为int或反之亦然),那么要注意的主要是sizeof( int)!= sizeof(long)。
除其他效果外,这将更改参数列表结构的大小,甚至可能更改其对齐方式。 在存储长度很重要的情况下,应小心使用stdint.h中的int32_t和int64_t类型。
还要注意,在A64-LP64中,size_t和ssize_t都很长(64位)。
尽管似乎可以将指针存储在“长”变量中,但是应该使用intptr_t之类的类型以最大程度地提高可移植性和安全性。
技巧
显式和隐式类型转换
当表达式中缺少不同长度和/或符号的数据类型时,C / C ++中的内部提升和类型转换会导致一些意外的问题。 特别地,有时重要的是要了解在表达式的评估中在什么时候进行了转换。
例如:
int + long -> long unsigned + signed -> unsigned如果在第二次转换(符号丢失)之前执行第二次转换(转换为long),则将其分配给有符号的long时结果可能不正确。
如果在表达式中混合使用无符号和有符号的32位整数并将结果分配给有符号的long,则一种解决方案是将其中一个操作数转换为其64位类型。 这将导致其他操作数提升为64位,并且在分配表达式时不需要进一步的转换。 另一种解决方案是强制转换整个表达式,以使符号扩展在赋值时发生。
例如:
long long a; int b; unsigned int c; b = -2; c = 1; a = b + c;a的预期是会得到-1.
这将保留为0x00000000FFFFFFFFFF(十进制|的4294967295),显然是意外的和不正确的结果。 这是因为相加的结果在转换为long long之前先转换为unsigned。
改成:
long long a; int b; unsigned int c; b = -2; c = 1; n = (long) b + c;这样得出的结果为0xFFFFFFFFFFFFFFFFFF(-1以2的补码符号表示),这是预期结果。 现在,所有计算均以64位算术进行,现在转换为正负号可以得出正确的结果。
位操作操作
请注意,位掩码的宽度正确。 C中的隐式类型转换有可能
表达式可能会产生一些意想不到的效果。 考虑以下功能或在64位变量中设置指定的位:
long SetBitN(long value, unsigned bitNum) {
long mask;
mask = 1 << bitNum;
return value | mask;
}
此功能在32位环境中可以正常工作,并且允许将位设置为0到31。为了将其移植到64位系统,您可能会认为只需更改掩码的类型即可 位要设置在位置0至63。
long long SetBitN(long long value, unsigned bitNum) {
long long mask;
mask = 1 << bitNum;
return value | mask;
}
由于数字文字“ 1”具有int类型,因此无法正常工作。 确切的行为取决于各个编译器的配置和假设。
使代码正确运行,您需要为常量提供与掩码相同的类型:
long long SetBitN(long long value, unsigned bitNum) {
long long mask
mask = (long long) 1 << bitNum;
return value | mask;
}
您还应注意为文字值指定类型,例如:
1L // (long)
1LL // (long long)
1U // (unsigned)
1UL // (unsigned long)
1ULL // (unsigned long long)
这也将为避免此类问题提供某种方式。
魔术数字
所有代码都包含一些描述常量。 但是,请注意常量,这些常量会假设基本类型的大小,例如
#define BYTES_IN_WORD 4索引
在64位环境中使用大型数组或对象时,请注意int可能不再足够大以索引所有条目。 使用int索引遍历数组时,尤其要小心。
size_t Count = BIG_NUMBER;
for (unsigned int index = 0; index != Count; index++) ...
由于size_t是64位类型,而unsigned int是32位类型,因此可以定义对象的大小,以使循环永远不会终止。
指针和整数
int i, *p, *q;
p = &i; q = (int *) (int) &i;在A32中,p == q。 在A64-LP64中,p!= q。
为了防止这种情况,您应该对指针类型使用intptr_t(来自stdint.h)。
在指针算术中,应该将从指针添加或减去的变量声明为ptrdiff_t,因为int(以及带符号)可能不足以容纳两个指针之间的差。
结构体pdding
单个元素的大小变化及其相应对齐要求的更改,将更改许多结构的大小。
struct foo {
int a;
long l;
int x;
}
在ILP32中,此结构的大小为12(字节),并且元素之间没有填充。
在LP64中,它的大小为20。“ long”已从4个字节和8个字节增加,现在必须是双字对齐的。 这在第一个“ int”的末尾与“ long”的末尾之间引入了四个填充字节。