深度学习语义分割(三)DeepLab(1,2,3,3+,auto-deeplab)系列论文解读
文章目录
- 1.引言
- 2.DeepLab1&2
- 2.1 DeepLabv1详解
- 2.2 DeepLabv2详解
- 3.DeepLab3
- 3.1 网络结构
- 3.2 实验结果
- 4.DeepLab3+
- 4.1 网络结构
- 4.2 实验结果:
- 5. AutoDeepLab
- 5.1 架构搜索空间
- 5.2 方法
- 5.3 优化
- 5.4 实验结果
1.引言
在语义分割领域,DeepLab系列算法占据了半壁江山,而DeepLabv3+是常被提及的state-of-the-art。最近同样出自谷歌的Auto-DeepLab问世,使用改进的神经架构搜索技术自动搜索图像语义分割的网络架构。本文按照时间顺序依次解读DeepLab系列论文。
2.DeepLab1&2
最早deeplab版本,为之后后面的v3和v3+奠定了基础,但其结构已经不是最先进的,但是为了完整性和连贯性,所以大概介绍这两个系列。
- 论文地址:DeepLab1,DeepLab2
- 代码地址:DeepLab1,DeepLab2
2.1 DeepLabv1详解
DeepLabv1是在VGG16的基础上做了修改:
- VGG16的全连接层转为卷积
- 最后的两个池化层去掉了下采样
- 后续卷积层的卷积核改为了空洞卷积
- 在ImageNet上预训练的VGG16权重上做finetune
利用空洞卷积进行特征提取
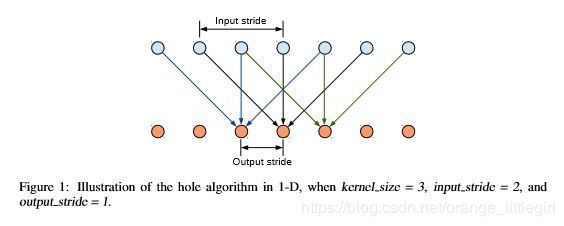
优点:
在DCNN中应用了空洞卷积密集的提取特征,对于普通利用pooling层进行缩减图像尺寸的方法:输出步幅是16,需要上采样16倍得到预测结果,结果是比较模糊的;而利用空洞卷积方法:空洞卷积采样率rate=2,保持步幅为8,只需要上采样8倍,结果清晰了很多。
利用CRF结构恢复边界信息
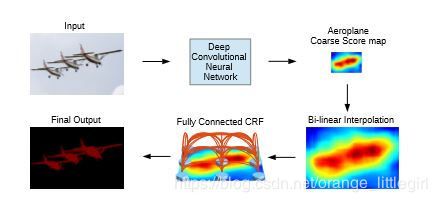
DCNN存在分类和定位之间的折中问题,预测到目标的大概位置但比较模糊,利用马尔可夫随机场进行优化边界。
实验结果:

2.2 DeepLabv2详解
- 用多尺度获得更好的分割效果(使用ASPP)
- 基础层由VGG16转为ResNet
- 使用不同的学习策略(poly)
提出ASSP
在多尺度上存储目标;在给定的特征层上使用不同采样率的卷积有效的重采样
;使用不同采样率的空洞卷积并行采样。
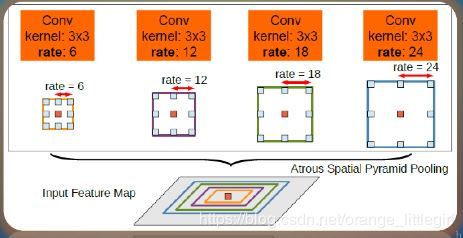
ASPP中在给定的Input Feature Map上以r=(6,12,18,24),r=(6,12,18,24)的3×33×3空洞卷积并行采样。
融合特征

训练
v2用Resnet 101作为backbone,有一定提升,v1和v2都用了CRF。关于CRF的不再赘述了,其实后面的版本都没有用这个了。训练用的poly策略。
实验结果:

3.DeepLab3
- 论文地址:DeepLab3
- 代码地址:github
- 创新:提出了更通用的框架,适用于任何网络;复制了ResNet最后的block,并级联起来;在ASPP中使用BN层,没使用CRF
3.1 网络结构
语义分割网络结构概述
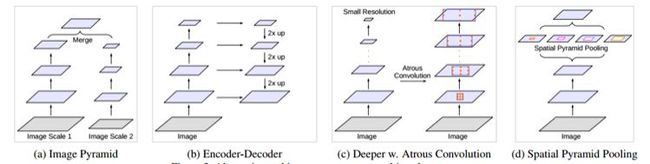
(a)图像金字塔。输入图像进行尺度变换得到不同分辨率input,然后将所有尺度的图像放入CNN中得到不同尺度的分割结果
(b)编码-解码。类似FCN和UNet等结构
(c)本文提出的串联结构。
(d)本文提出的Deeplab v3结构。最后两个结构右边其实还需要8×/16×的upsample,在deeplab v3+中有所体现。
ASSP改进
针对ASPP,作者设计了一种“纵式”的结构,如下图:
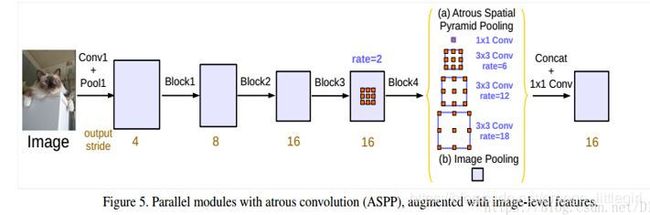
改进后的aspp长下图那个样子,多了个1x1的conv和global avg pool。
(1)1x1卷积,论文中3.3第一段解释的有点意思,当rate=feature map size时,dilation conv就变成了1x1 conv,所以这个1x1conv相当于rate很大的空洞卷积。(2)此外引入了全局池化这个branch,这个思想是来源于PSPnet,简言之就是spp在分割上的应用,多尺度pooling。(3)每个branch后面都没有relu,其实有没有BN,BN是线性操作,可以合并到conv里面,论文的Sec 4.1 说明了V3的所有层是用了BN的,BN可以加速训练还有弱正则,所以一般都会用。
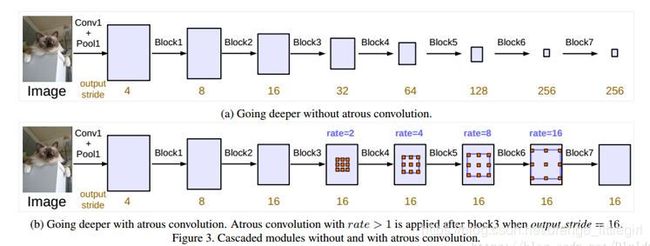
串联结构
对RestNet进行改进,利用空洞卷积进行扩大视野的操作,提出了串联结构,经过实验发现有较高的精度,但还是不及改进的ASSP
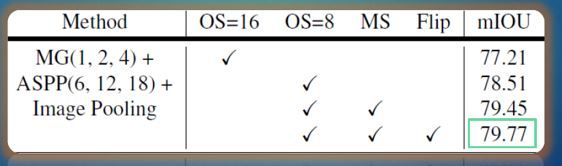
3.2 实验结果
最好的结果包含:ASPP输出步幅为8,翻转和随机缩放的数据增强

4.DeepLab3+
- 论文地址:Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
- 代码地址:github
- 创新:设计基于v3的decode module;用modify xception作为backbone。
4.1 网络结构
网络结构概述
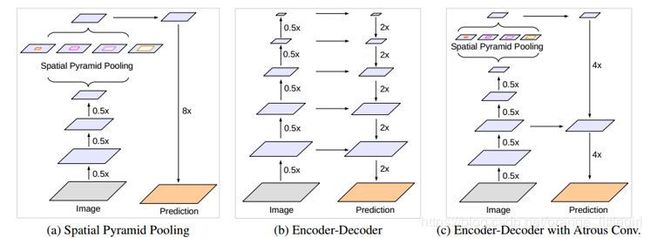
(a)DeepLabv3的纵式结构
(b)是常见的编码—解码结构
(c)是本文提出的基于deeplab v3的encode-decode结构
改进的Xception网络
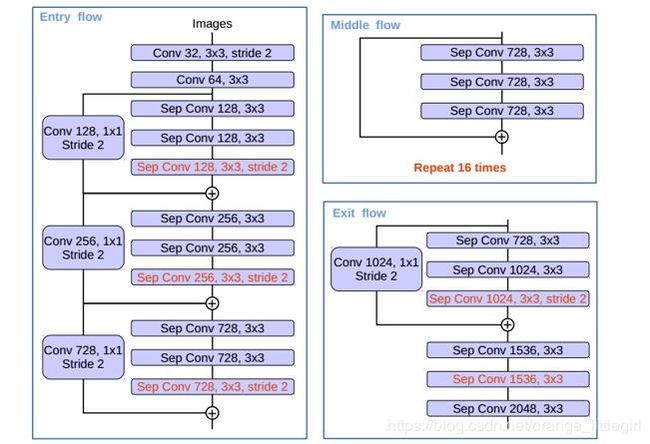
具体结构参照下图。和原来的xception不一样的地方:(1)Middle flow重复了16次,ori xception是8次,也就是用了more layers;(2)pooling均换为了dw+pw+s=2;(3)在所有的dw层后面加上了BN和relu
整体网络结构

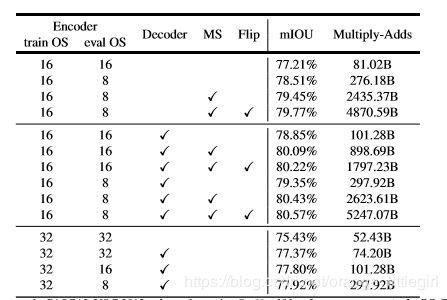
4.2 实验结果:
5. AutoDeepLab
-
论文地址:Auto-DeepLab: HierarchicalNeuralArchitectureSearchforSemanticImageSegmentation
-
代码地址(非官方):github
-
特点:1. 当然是搜索到了优秀的架构,语义分割计算量小精度依然优秀;2. 搜索计算量小,是少数平民能训练得起的神经架构搜索算法;
-
参考博客:机器之心
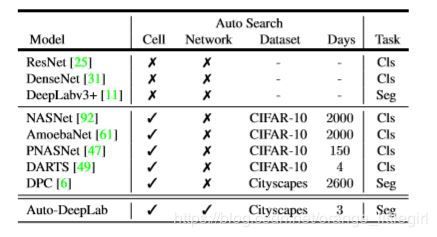
它可以在两级分层架构上进行有效搜索,在单个GPU上只需3天。
5.1 架构搜索空间
两级分层结构搜索空间。 对于内部单元级,复用前人中采用的方法,从而与以前的工作保持一致。对于外部网络级,基于对许多流行设计的观察和总结提出了一种新颖的搜索空间。
单元级搜索空间
我们将一个小的全卷积模块定义为一个单元(cell),通常它会在整个神经网络中重复很多次。更具体地说,一个单元是由 B B B个块(block)组成的有向无环图。每个块是双分支结构,将两个输入张量(tensor)映射到一个输出张量。 O O O是输入张量的层类型的选择。
可能的层类型 O O O的集合由以下8个操作(operator)组成,这些操作在现代CNN中都很普遍:
(1)3 × 3的深度分离卷积;(2)5 × 5的深度分离卷积;(3)3 × 3的孔洞卷积 ,孔洞率为2;(4)5 × 5的孔洞卷积 ,孔洞率为2;(5)3 × 3的平均池化;(6)3 × 3的最大池化;(7)跳跃连接;(8)无连接
网络级搜索空间
在由图像分类NAS框架中,一旦找到单元结构,整个网络就使用预定义的模式构建。因此,网络级不是架构搜索的一部分,因此其搜索空间从未被提出或设计过。
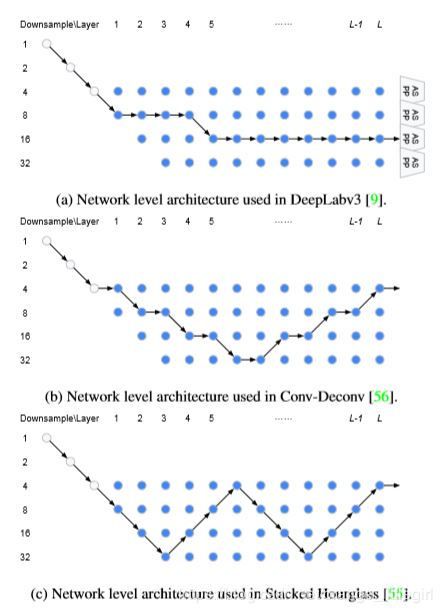
这种预定义的模式简单明了:通过插入“缩小单元”(将空间分辨率除以2并将滤波器数乘以2的单元),将许多“正常单元”(保持特征张量空间分辨率的单元)平等的分隔开。这种下采样策略在图像分类情况下是合理的,但在密集图像预测中,保持高空间分辨率也很重要,因此存在更多的网络级别变化[9,56,55]。
用于密集图像预测的各种网络架构中,我们注意到两个一致的原则:
(1)下一层的空间分辨率要么是两倍大,要么是两倍小,要么保持不变。
(2)最小的空间分辨率是下采样32倍。
我们提出以下网络级搜索空间。网络的开头是一个双层“枝干”(stem)结构,每个枝干都将空间分辨率降低2倍。之后,总共有L层具有未知空间分辨率的单元,分辨率的最大值是被下采样4倍,最小值是被下采样32倍。由于每层空间分辨率可能至多为2倍不同,因此枝干后的第一层只能被下采样4倍或8倍。我们在图1中说明了我们的网络级搜索空间。我们的目标是在这个L层网格中找到一条好的路径。
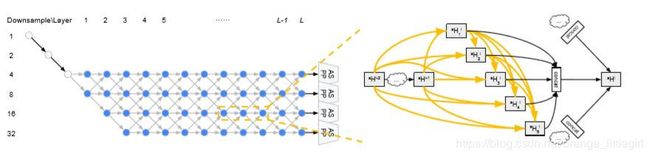
在下图中,我们展示了我们的搜索空间足以覆盖许多流行的设计。在未来,我们计划进一步放宽这个搜索空间以包括U-net架构。
5.2 方法
我们首先介绍与上述分层架构搜索完全匹配的连续松弛的(指多数个)离散架构。然后,我们讨论如何进行架构搜索优化,以及如何在搜索终止后解码一个离散架构。
单元架构
![]()
这一节和上一节中块的五元组 ( I 1 , I 2 , O 1 , O 2 , C ) (I_1,I_2,O_1,O_2,C) (I1,I2,O1,O2,C) 对应,求解 H H H这也就是上一节节中说的简单的对应元素相加。
网络架构
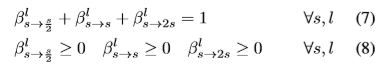
显示了如何将两级分层结构的连续松弛编织在一起。
5.3 优化
引入这种连续松弛的优点是控制不同隐藏状态之间的连接强度的标量现在是可微分计算图的一部分。因此,它们可以通过梯度下降方法得到有效的优化。并将训练集分为两个不相交的集合trainA和trainB。优化在以下二者之间交替进行
5.4 实验结果
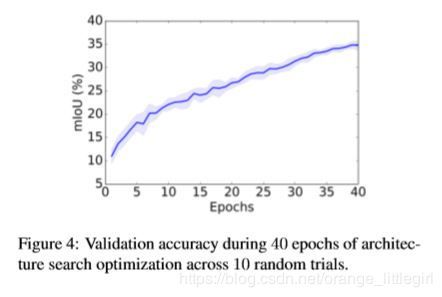
10 次随机试验中,40 个 epoch 中架构搜索优化的验证准确率。
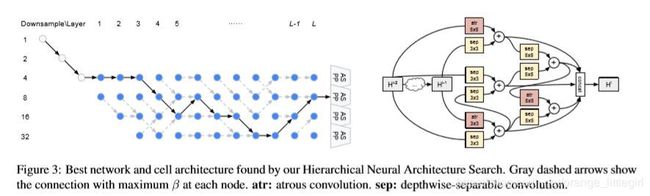
使用本研究提出的分层神经架构搜索方法找到的最优网络架构和单元架构。
灰色虚线箭头表示每个节点处具备最大 β 值的连接。atr 指空洞卷积(atrous convolution),sep 指深度可分离卷积(depthwise-separable convolution)。
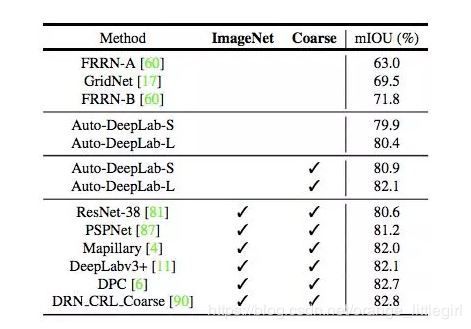
模型在推断过程中使用多尺度输入时在 Cityscapes 测试集上的结果。
ImageNet:在 ImageNet 上预训练的模型。Coarse:利用粗糙注释的模型。
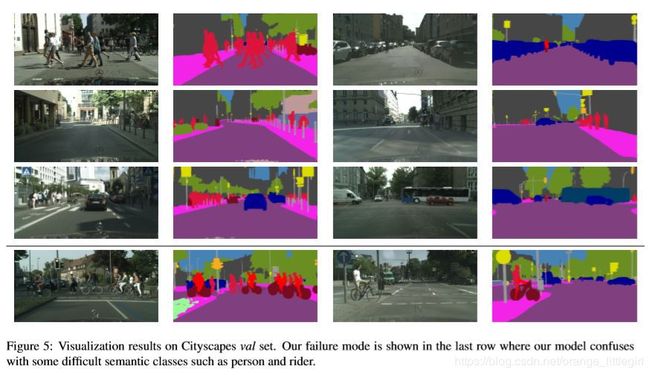
在CityScapes上可视化结果。