Selenium+Phantomjs做Java爬虫
背景
以前,觉得爬虫是不稳定的,而且不被业界允许的,从来没想过会在实际的项目中使用。现在,由于各种突发情况,必须使用爬虫才能完成相应任务。起初,觉得爬虫不过是爬取网页,解析网页就可以了,比较简单,谁知一路心酸泪。
查阅各种资料,Java相关的爬虫工具也比较多,由于时间关系,只简单看了下面几种,分析如下:
| HtmlUnit |
webmagic |
Selenium |
phantomjs |
|
| 优点 |
Java编写的无界面浏览器,内置Rhinojs浏览器引擎,支持表单填充,点击链接,能够获取动态页面等。 |
webmagic采用完全模块化的设计,支持链接提取、页面下载、内容抽取、持久化,支持多线程抓取,分布式抓取,并支持自动重试、自定义UA/cookie等功能。另外国人编写,文档齐全,支持。 |
Web浏览器测试工具,支持获取动态网页,支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等,模拟真实用户的操作。可以用来测试项目的兼容性。 |
PhantomJS是一个基于webkit的JavaScript API。支持Dom操作、css选择器、截屏等,无界面的浏览器操作,节省内存,另外支持js脚本,功能强大。 |
| 缺点 |
对css、js支持不好,最大的缺点,获取动态网页需要指定固定等待时间,类如:Thread.sleep(10000),时间不好把控,性能极差 |
静态HTML获取方便,但动态网页无法获取,需要另外使用工具,类如Selenium浏览器模拟。 |
运行过程中会打开浏览器界面,内存消耗大,与各种浏览器版本强依赖,适用于测试项目兼容性,不适用当前业务。 |
无界面浏览器,无法显示的模拟用户操作 |
由于这次需要爬取的网站,基本上都是采取JS+AJAX获取数据,渲染的动态网页,所以最终选择了 selenium+phantomjs组合进行爬取,因为selenium封装了phantomjs,能够让我们更方便,更好的使用,节约时间和成本。
准备
phantomjs下载:
使用phantomjs则需要下载相应运行器,下载网址:https://phantomjs.org/download.html,大家可以根据自己的系统进行下载,这里我们使用windows版本—phantomjs-2.1.1-windows.zip。大家下载下来解压即可。
Maven依赖如下:
org.seleniumhq.selenium
selenium-java
3.141.59
com.codeborne
phantomjsdriver
1.4.4
使用
创建phantomjs实例对象—PhantomJSDriver
DesiredCapabilities desiredCapabilities = new DesiredCapabilities();
//ssl证书支持
desiredCapabilities.setCapability("acceptSslCerts", true);
//截屏支持,这里不需要
desiredCapabilities.setCapability("takesScreenshot", false);
//css搜索支持
desiredCapabilities.setCapability("cssSelectorsEnabled", true);
//js支持
desiredCapabilities.setJavascriptEnabled(true);
//驱动支持
desiredCapabilities.setCapability(PhantomJSDriverService.PHANTOMJS_EXECUTABLE_PATH_PROPERTY,
"G:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe");
//创建无界面浏览器对象
PhantomJSDriver driver = new PhantomJSDriver(desiredCapabilities);
//这里注意,把窗口的大小调整为最大,如果不设置可能会出现元素不可用的问题
driver.manage().window().maximize();上述是对爬虫实例对象设置请求头信息,由于我们爬取的网站采用JS+AJAX进行渲染页面,所以需要js支持,必须设置setJavascriptEnabled(true),否则无法运行js代码,无法正常拿到渲染后的页面。
//用于设置phantomjs运行器的位置
desiredCapabilities.setCapability(PhantomJSDriverService.PHANTOMJS_EXECUTABLE_PATH_PROPERTY,"G:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe");特别注意,第一次使用的时候遇到的一个坑,driver.manage().window().maximize();在爬取网页的时候,最好先加上这一句代码,用于设置窗口的大小,否则你可能会遇到如下异常:
selenium.common.exceptions.ElementNotVisibleException Message errorMessage Element is not currently visible and may not be manipulated
大致意思就是说,元素不可交互。这就很奇怪,元素能够正常获取到,但是你给我说元素不可交互,后面才发现,原来phantomjs在运行的时候,窗口有一个默认大小,由于窗口太小,你能够通过id获取到元素,但是你不能点击它。如遇到上述问题,大家记得加上driver.manage().window().maximize()。
现在,我们有了实例对象了,可以进行网页爬取了,以CSDN为例,给大家简单说一下工具的使用。
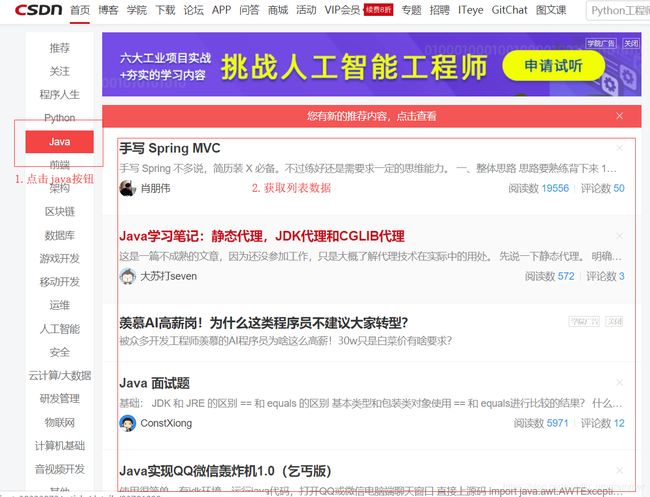
假设我们现在需要获取JAVA模块的文章(标题+链接),我们来看看应该怎么做。
String href = "https://www.csdn.net";
PhantomJSDriver driver = create();
//获取csdn主页
driver.get(href);
//定位到Java按钮
WebElement java = driver.findElementByLinkText("Java");
//执行点击
java.click();
//用于定位到Java模块列表
WebElement feedlist_id = driver.findElementById("feedlist_id");
List liList = feedlist_id.findElements(By.className("clearfix"));
//循环遍历li
for (WebElement li : liList) {
WebElement title = li.findElement(By.className("title"));
WebElement a = title.findElement(By.tagName("a"));
System.out.println("标题:" + a.getText() + " 链接:" + a.getAttribute("href"));
}
执行结果如下:
标题:手写 Spring MVC 链接:https://blog.csdn.net/qq_40147863/article/details/96505433
标题:Java学习笔记:静态代理,JDK代理和CGLIB代理 链接:https://blog.csdn.net/sinat_38393872/article/details/93781299
标题:Java 面试题 链接:https://blog.csdn.net/meism5/article/details/92830778
标题:Java实现QQ微信轰炸机1.0(乞丐版) 链接:https://blog.csdn.net/xiao_xiao_b/article/details/93619747
标题:Java分类导航 链接:https://blog.csdn.net/qq_41293896/article/details/86535257
标题:面向对象总结 链接:https://blog.csdn.net/L6_6LXXX/article/details/96445205
标题:Java基础面试题50题 链接:https://blog.csdn.net/meetbetterhc/article/details/96568451
标题:java学习血泪史 链接:https://blog.csdn.net/qq_44082148/article/details/97616527
标题:再看Java之温故知新(体系篇) 链接:https://blog.csdn.net/LucasXu01/article/details/93022464
...大家是不是觉得特别简单呢,现在就简单介绍一下相关API:
1.获取指定网页
driver.get(String href)2.假设我们想知道获取的网页是否是我们需要的,可以通过如下方式获取网页信息
driver.getPageSource();3.获取元素的方式很多,常用的如下:
//通过id的方式获取元素
public WebElement findElementById(String using)
//通过链接文本方式获取单个元素
public WebElement findElementByLinkText(String using)
//通过标签名方式获取单个元素
public WebElement findElementByTagName(String using)
//通过标签名方式获取多个元素
public List findElementsByTagName(String using)
//通过name属性方式获取单个元素
public WebElement findElementByName(String using)
//通过name属性方式获取多个元素
public List findElementsByName(String using)
//通过类名方式获取单个元素
public WebElement findElementByClassName(String using)
//通过类名方式获取多个元素
public List findElementsByClassName(String using)
//通过css选择器方式获取单个元素
public WebElement findElementByCssSelector(String using)
//通过css选择器方式获取多个元素
public List findElementsByCssSelector(String using)
//通过xpath方式获取单个元素
public WebElement findElementByXPath(String using)
//通过xpath方式获取多个元素
public List findElementsByXPath(String using) 在使用css选择器,类似于findElementByCssSelector的时候,前提是desiredCapabilities.setCapability("cssSelectorsEnabled", true);css选择器在什么情形能够使用呢,好像上面已经包含的很全了,想不到什么地方需要用呢?
- ,很多地方的class都类似于class="feedlist_mod java" ,这个时候我们想使用类名获取元素,如果采用 findElementByClassName(String using) 是获取不到的,这个时候就必须使用css选择器了,例如: driver.findElementByCssSelector("[class='feedlist_mod java']");
4.执行元素点击
void click();5.获取属性值
String getAttribute(String name)6.获取元素内容
标签文本:String getText()
输入框value值:element.getAttribute("value")
现在我们需求变了,我们想要在CSDN搜索某类文章,应该怎么办呢?请往下看。
WebElement searchElement = driver.findElementById("toolber-keyword");
searchElement.clear();
searchElement.sendKeys("SpringCloud");7.clear()用于清空元素的内容
8.sendKeys(CharSequence... keysToSend)用于给输入框赋值
当然,在某些时候,我们可能不是简单的获取元素这么简单,可能会模拟某种情形,执行相关事件,类似于下拉选择框,单选按钮,复选框,表单提交。
9.选择下拉框元素
Select select = new Select(driver.findElementById("select"));
//通过索引选择
select.selectByIndex(1);
//通过value值获取
select.selectByValue("zhangsan")
//通过文本值获取
select.selectByVisibleText("张三");10.单选按钮比较简单
WebElement radio = driver.findElementById("radio"); radio.click();11.复选框选择
复选框其实和单选按钮一样,都是定位元素,点击元素,在选择元素之前,我们可以通过isSelected()来判断元素是否被选择,isEnabled()来判断元素是否被禁用。
12.表单提交
WebElement form = driver.findElementById("form");
//只能用于表单提交
form.submit();在某些时候,有些网站在执行的时候可能会打开另外一个窗口,这个时候,如果我们想要回到原先的窗口,应该怎么办呢?
13.窗口切换
//获取窗口的句柄
String windowHandle = driver.getWindowHandle();
//另外一个窗口执行...
//另外一个窗口执行结束后,我们可以通过switchTo()去返回到原先窗口
driver.switchTo().window(windowHandle);在某些AJAX请求进行渲染的页面,可能我们不能立即获取到渲染后的页面,那么我们就需要进行等待,这里支持两种类型的等待方式:
1.隐形等待
driver.manage().timeouts().implicitlyWait(10, TimeUnit.SECONDS);针对全局设置,所有命令的超时时间都是10s,如果超过等待时间,则抛出异常。
2.显示等待
WebDriverWait webDriverWait = new WebDriverWait(driver, 10);
webDriverWait.until(new ExpectedCondition() {
@Override
public WebElement apply(WebDriver webDriver) {
return webDriver.findElement(By.id("toolber-keyword"));
}
}); 等待某个元素,最大等待10s,默认0.5s为搜索间隔,搜索到元素则停止等待。在使用AJAX获取数据的网站中,使用该方式十分方便,若10s都没有结果,那么则认定系统出现故障。
某些时候,我们可能通过getText()的方式获取标签的文本值并不会生效,也有可能通过getPageSource()能够看到某些元素,但是我们就是获取不到它们,这是为什么呢?
额,其中原理,我也不知道是什么情况,暂时抛开这个问题,有时间再深究它。不过,目前可以通过另外的方式解决,phantomjs能够执行js语句,这可是一个好方式,我们可以通过写js语句来解决大部分问题。
执行js语句
Object executeScript(String script, Object... args);
该方法可以供我们执行js语句,script代表我们的js语句,args代表散列值,接受参数使用arguments[0]依次来接受。示例如下:
假设我们想要获取某个标签的文本值
第一种方式:
driver.executeScript("document.getElementById('blogClick').innerText")第二种方式:
WebElement blogClick = driver.findElementById("blogClick");
driver.executeScript("arguments[0].innerText",blogClick);总结
采用爬虫处理业务,如果是静态网页还比较好处理,如果是AJAX+JS渲染的动态页面,在爬取的过程中,会遇到各种各样的坑,希望这篇文章能够带大家入门,如果大家遇到需要使用爬虫才能处理的业务,希望大家能够少掉点头发。