【DNN】W&D(Wide and Deep)
0.介绍
Google 发表在 DLRS 2016 上发表的文章。Wide & Deep 模型的核心思想是结合线性模型的记忆能力和 DNN 模型的泛化能力,从而提升整体模型性能。该结构被提出后即引起热捧,在业界影响力非常大,很多公司纷纷仿照该结构并成功应用于自身的推荐等相关业务。我是在18年工作的代码中看到了这个模型,线上服务有wide deep类,但是模型迭代时,工具封装的太好了,都没有见到过显示的网络结构,只是将对应部分输入,然后得到模型,上线即可,今日来彻底捋捋这个框架。
wide&deep网络中,wide部分是将特征和线性模型结合,可以取得不错的效果,模型简单且可解释性好。但整体来看,该网络结构对特征的依赖比较大,需要大量的人工参与才能获取到好的效果。后续会有一些做特征交叉组合的网络衍生,比如DCN,PNN。
1.核心
Motivation
推荐系统的主要挑战之一,是同时解决Memorization和Generalization,理解这两个概念是理解全文思路的关键,下面分别进行解释。
- Wide侧就是普通LR,一般根据人工先验知识,将一些简单、明显的特征交叉,喂入Wide侧,让Wide侧能够记住这些规则。
- Deep侧就是DNN,通过embedding的方式将categorical/id特征映射成稠密向量,让DNN学习到这些特征之间的深层交叉,以增强扩展能力。
- Memorization--- 可能只推荐用户有过行为的item
面对拥有大规模离散sparse特征的CTR预估问题时,将特征进行非线性转换,然后再使用线性模型是在业界非常普遍的做法,最流行的即「LR+特征叉乘」。Memorization 通过一系列人工的特征叉乘(cross-product)来构造这些非线性特征,捕捉sparse特征之间的高阶相关性,即“记忆” 历史数据中曾共同出现过的特征对。
典型代表是LR模型,使用大量的原始sparse特征和叉乘特征作为输入,很多原始的dense特征通常也会被分桶离散化构造为sparse特征。这种做法的优点是模型可解释高,实现快速高效,特征重要度易于分析,在工业界已被证明是很有效的。Memorization的缺点是:
- 需要更多的人工设计;
- 可能出现过拟合。可以这样理解:如果将所有特征叉乘起来,那么几乎相当于纯粹记住每个训练样本,这个极端情况是最细粒度的叉乘,我们可以通过构造更粗粒度的特征叉乘来增强泛化性;
- 无法捕捉训练数据中未曾出现过的特征对。例如上面的例子中,如果每个专业的人都没有下载过《消愁》,那么这两个特征共同出现的频次是0,模型训练后的对应权重也将是0;
- Generalization--- 可能推荐出跟user爱好不那么相关的
Generalization 为sparse特征学习低维的dense embeddings 来捕获特征相关性,学习到的embeddings 本身带有一定的语义信息。可以联想到NLP中的词向量,不同词的词向量有相关性,因此文中也称Generalization是基于相关性之间的传递。这类模型的代表是DNN和FM。
Generalization的优点是更少的人工参与,对历史上没有出现的特征组合有更好的泛化性 。但在推荐系统中,当user-item matrix非常稀疏时,例如有和独特爱好的users以及很小众的items,NN很难为users和items学习到有效的embedding。这种情况下,大部分user-item应该是没有关联的,但dense embedding 的方法还是可以得到对所有 user-item pair 的非零预测,因此导致 over-generalize并推荐不怎么相关的物品。此时Memorization就展示了优势,它可以“记住”这些特殊的特征组合。
Memorization根据历史行为数据,产生的推荐通常和用户已有行为的物品直接相关的物品。而Generalization会学习新的特征组合,提高推荐物品的多样性。 论文作者结合两者的优点,提出了一个新的学习算法——Wide & Deep Learning,其中Wide & Deep分别对应Memorization & Generalization。
网络结构
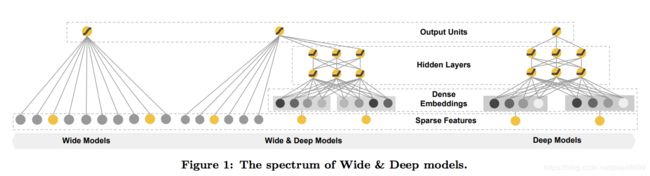
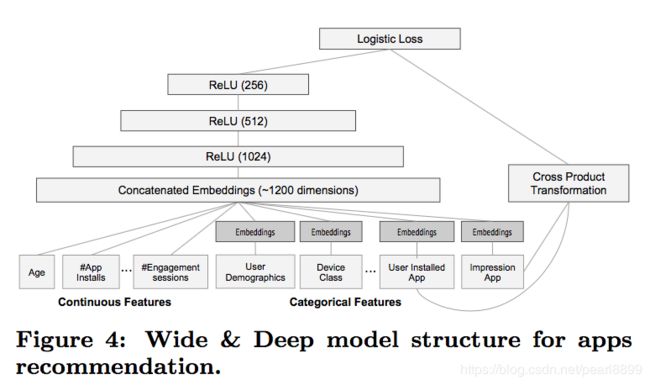
Wide 该部分是广义线性模型,即y=wTx+b,x=[x1,x2,…,xd]x=[x1,x2,…,xd] 是包含了 d 个特征的向量,w=[w1,w2,…,wd]w=[w1,w2,…,wd] 是模型参数,b 是偏置。特征包括了原始的输入特征以及 cross-product transformation 特征,给线性模型增加点非线性。
Deep 该部分是前馈神经网络,网络会对一些sparse特征(如ID类特征)学习一个低维的dense embeddings(维度量级通常在O(10)到O(100)之间),然后和一些原始dense特征一起作为网络的输入。
一开始嵌入向量(embedding vectors)被随机初始化,然后训练过程中通过最小化损失函数来优化模型。每一个隐层(hidden-layer)做这样的计算:
a(l+1)=f(W(l)a(l)+b(l))a(l+1)=f(W(l)a(l)+b(l)),f 是激活函数(通常用 ReLU),l 是层数。
总结一下,基于 embedding 的深度模型的输入是 类别特征(产生embedding)+连续特征。

联合训练:wide和deep部分输出的log odds进行加权求和,作为预测的结果,然后再送入到一个共同的logloss方程中,去联合训练。
联合训练(Joint Training)和集成(Ensemble)是不同的,集成是每个模型单独训练,在输出层面,将模型的结果汇合,而不是训练的时候,进行结果融合。联合训练是同时优化wide和deep的参数包括两部分加权求和时候的权重,都同时进行学习。相比联合训练,集成的每个独立模型都得学得足够好才有利于随后的汇合,因此每个模型的model size也相对更大。而联合训练的wide部分只需要作一小部分的特征叉乘来弥补deep部分的不足,不需要 一个full-size 的wide 模型。(Wide部分设置很有意思,作者为什么这么做呢?结合业务思考,在Google Play商店的app下载中,不断有新的app推出,并且有很多“非常冷门、小众”的app,而现在的智能手机user几乎全部会安装一系列必要的app。联想前面对Memorization和Generalization的介绍,此时的Deep部分无法很好的为这些app学到有效的embeddding,而这时Wide可以发挥了它“记忆”的优势,作者在这里选择了“记忆”user下载的app与被推荐的app之间的相关性,有点类似“装个这个app后还可能会装什么”。对于Wide来说,它现在的任务是弥补Deep的缺陷,其他大部分的活就交给Deep了,所以这时的Wide相比单独Wide也显得非常“轻量级”,这也是Join相对于Ensemble的优势。)
一、得到的模型size更小
二、训练过程中,各自发挥作用,wide弥补deep的缺陷,大部分学习工作还是在deep。
在论文中,作者通过梯度的反向传播,使用 mini-batch stochastic optimization 训练参数,并对wide部分使用带L1正则的Follow- the-regularized-leader (FTRL) 算法,对deep部分使用 AdaGrad算法。
总结
- 详细解释了目前常用的 Wide 与 Deep 模型各自的优势:Memorization 与 Generalization。
- 结合 Wide 与 Deep 的优势,提出了联合训练的 Wide & Deep Learning。相比单独的 Wide / Deep模型,实验显示了Wide & Deep的有效性,并成功将之成功应用于Google Play的app推荐业务。
- 目前Wide 结合 Deep的思想已经非常流行,结构虽然简单,从业界的很多反馈来看,合理地结合自身业务借鉴该结构,实际效果确实是efficient,我们的feeds流主模型也借鉴了该思想。
2.代码
使用TensorFlow实现代码,github地址:wide &deep代码
新版本TensorFlow自带了DNNLinearCombinedClassifier实现了Wide&Deep模型,再使用Wide&Deep,只需要几行代码即可。而且,因为DNNLinearCombinedClassifier继承自Estimator,基类已经自动实现了如定时保存模型、重启后自动加载模型继续训练、自动保存metric供模型可视化、分布式训练等一系列的“小而重要”的功能,“一切都仿佛非常美好”。如有兴趣可以阅读源码。
shixiangfu大神的代码:
可以看到:
LR使用FTRL优化,DNN使用Adagrade进行优化,
import tensorflow as tf
from model_brain import BaseModel
import six
import math
from tensorflow.python.framework import ops
from tensorflow.python.ops import control_flow_ops
from tensorflow.python.ops import state_ops
from tensorflow.python.estimator.canned import head
from tensorflow.python.ops.losses import losses
class WD_Model(BaseModel):
'''wide and deep model'''
def __init__(self, features, labels, params, mode):
super(WD_Model,self).__init__(features, labels, params, mode)
self.Linear_Features,self.Deep_Features = self._get_feature_embedding
with tf.variable_scope('Embedding_Module'):
self.embedding_layer = self.get_input_layer(self.Deep_Features)
with tf.variable_scope('DNN_Module'):
self.logits,self.train_op_fn = self._model_fn
@property
def _model_fn(self):
'''wide and deep model'''
with tf.variable_scope('fc_net'):
with tf.variable_scope(
'deep_model',
values=tuple(six.itervalues(self.features)),
) as scope:
dnn_absolute_scope = scope.name
dnn_logits = self.fc_net(self.embedding_layer,1)
with tf.variable_scope(
'linear_model',
values=tuple(six.itervalues(self.features)),
) as scope:
linear_absolute_scope = scope.name
linear_logits = tf.feature_column.linear_model(self.features,self.Linear_Features)
if dnn_logits is not None and linear_logits is not None:
logits = dnn_logits + linear_logits
elif dnn_logits is not None:
logits = dnn_logits
else:
logits = linear_logits
dnn_optimizer = tf.train.AdagradOptimizer(learning_rate=self.params['LEARNING_RATE'])
def _linear_learning_rate(num_linear_feature_columns):
default_learning_rate = 1. / math.sqrt(num_linear_feature_columns)
return min(self.params['LINEAR_LEARNING_RATE'], default_learning_rate)
linear_optimizer = tf.train.FtrlOptimizer(_linear_learning_rate(len(self.Linear_Features)))
def _train_op_fn(loss):
train_ops = []
global_step = tf.train.get_global_step()
if dnn_logits is not None:
train_ops.append(
dnn_optimizer.minimize(
loss,
var_list=ops.get_collection(
ops.GraphKeys.TRAINABLE_VARIABLES,
scope=dnn_absolute_scope)))
if linear_logits is not None:
train_ops.append(
linear_optimizer.minimize(
loss,
var_list=ops.get_collection(
ops.GraphKeys.TRAINABLE_VARIABLES,
scope=linear_absolute_scope)))
train_op = control_flow_ops.group(*train_ops)
with ops.control_dependencies([train_op]):
return state_ops.assign_add(global_step, 1).op
return logits, _train_op_fn
@property
def build_estimator_spec(self):
'''Build EstimatorSpec'''
my_head = head._binary_logistic_head_with_sigmoid_cross_entropy_loss( # pylint: disable=protected-access
loss_reduction=losses.Reduction.SUM)
return my_head.create_estimator_spec(
features=self.features,
mode=self.mode,
labels=self.labels,
train_op_fn=self.train_op_fn,
logits=self.logits)
续集:
“记忆与扩展”、“类别特征”和“特征交叉”,来描绘推荐算法的发展脉络。沿着这一脉络,结出了Wide&Deep, FM/FFM/DeepFM, Product-based nural net,Deep Cross Network, Deep Interest Network等果实。
Wide&Deep全文围绕着“记忆”(Memorization)与“扩展(Generalization)”两个词展开。实际上,它们在推荐系统中有两个更响亮的名字,Exploitation & Exploration,即著名的EE问题。
稀疏的类别/ID类特征,才是推荐、搜索领域的“一等公民”,被研究得更多。即使有一些实数值特征,比如历史曝光次数、点击次数、CTR之类的,也往往通过bucket的方式,变成categorical特征,才喂进模型。这里说一句,工作中,会将连续特征按照分位数进行读取,也就是分段,存储、传输、运算,提升运算效率。
参考:
1.论文:https://arxiv.org/pdf/1606.07792.pdf
2.论文阅读笔记:http://www.shuang0420.com/2017/03/13
3.论文的翻译(近似):https://zhuanlan.zhihu.com/p/53361519
4.代码及其解说:https://blog.csdn.net/sxf1061926959/article/details/78440220
5.代码github:https://github.com/Shicoder/Deep_Rec/tree/master/Deep_Rank
6.Google实现wide&deep(非封装):https://zhuanlan.zhihu.com/p/47965313