小甲鱼python零基础入门 学习笔记 ——列表
列表
1 列表示例
列表中的元素可以包括整数,浮点数,字符串,对象
>>> example=['3.14','48','peter',[1,2,3],'小甲鱼']
>>> example
['3.14', '48', 'peter', [1, 2, 3], '小甲鱼']1,列表当中的元素以,分隔开
2,列表用[ ]表示(这里要与元组,字典相区别)
2 创建列表
2.1 创建一个普通列表
>>> example=['大白', '二黄', '三绿', '四红']
>>> example
['大白', '二黄', '三绿', '四红']2.2 创建一个混合列表
>>> example=['3.14','48','peter',[1,2,3],'小甲鱼']
>>> example
['3.14', '48', 'peter', [1, 2, 3], '小甲鱼']2.3 创建一个空列表
>>> example=[]
>>> example
[]3 在列表中加入元素
3.1 列表名.append
特点:(参数为元素) 加一个元素
具体示例:
>>> example=['3.14','48','peter',[1,2,3],'小甲鱼']
>>> example
['3.14', '48', 'peter', [1, 2, 3], '小甲鱼']
>>> example.append('柠檬精')
>>> example
['3.14', '48', 'peter', [1, 2, 3], '小甲鱼', '柠檬精']3.2 列表名.extend
特点:(参数为列表)
具体示例:
#错误示例
>>> example.extend('程序员')
>>> example
['3.14', '48', 'peter', [1, 2, 3], '小甲鱼', '柠檬精', '程', '序', '员']
# extend运行时加入为数组形式。
#extend正确使用方式
>>> example=[]
>>> example
[]
>>> example2=['大白','小黑']
>>> example.extend(example2)
>>> example
['大白', '小黑']
3.3 列表名.insert(0,‘’)
特点:(第一个参数,可以表示加入参数的位置)
具体示例:
example
['大白', '小黑']
>>> example.extend(example)
>>> example
['大白', '小黑', '大白', '小黑']
>>> example.insert(2,'无名氏')
>>> example
['大白', '小黑', '无名氏', '大白', '小黑']3.4 对于三种添加方式的总结:
append 与 insert每次运行都只能加入一个元素,
extend 可以加入多个元素,但是加入时需要以列表形式
4 在列表中删除元素
4.1 列表名.remove(‘名称’)
示例:
>>>example
['大白', '小黑', '无名氏', '大白', '小黑']
>>> example.remove('大白')
>>> example
['小黑', '无名氏', '大白', '小黑']
>>> example.remove('大白')
>>> example
['小黑', '无名氏', '小黑']由这个示例我们可以看出,remove是根据列表元素的名称对元素进行删除操作。且每次只删除一个元素,如果列表中存在有相同名称的多个元素,则从最前面的开始删除,每次只能删除一个。
4.2 del 列表名[位置值]
>>> example
['小黑', '无名氏', '小黑']
>>> del example[0]
>>> example
['无名氏', '小黑']>>> example
['大白', '三绿', '四红', '程序员', '柠檬精', '小甲鱼']
>>> del example[1:4]
>>> example
['大白', '柠檬精', '小甲鱼']以上两个示例,分别为del 删除单个元素,del删除列表中某个切片。
4.3 列表名.pop
>>> example=['大白','二黄','三绿','四红','小黑']
>>> name=example.pop()
>>> name
'小黑'
>>> example
['大白', '二黄', '三绿', '四红']
>>> name=example.pop(2)
>>> name
'三绿'
>>> example
['大白', '二黄', '四红']pop的删除方式类似于堆栈的弹出, 采用这种方式如果不改变参数,就是默认弹出列表最后面一个元素。
设置参数之后,可以删除列表中任意位置。且pop这种方式能够保留被删除的值。
注意:如果pop()中的索引index值超出列表范围或者remove()指定要删除的元素不在列表中,均会报错。
5 列表的切片
但我们需要一次获取列表中多个元素时,我们可以利用切片来完成。
>>> number_list=['1','2','3','5','7','11','13','17']
>>> number_list[1:3] #获取列表位置1到位置2(3-1)的值
['2', '3']
>>> number_list
['1', '2', '3', '5', '7', '11', '13', '17']
>>> number_list[:3] #获取列表位置0到位置2(3-1)的值
['1', '2', '3']
>>> number_list[1:] #获取列表位置1到末尾的值
['2', '3', '5', '7', '11', '13', '17']
>>> number_list[:]
['1', '2', '3', '5', '7', '11', '13', '17'] #当两个参数都不设置的时候,也称为列表的拷贝。6 列表的数值运算
6.1 列表比大小
1,从列表中分别取第一个元素开始比较,如果相等,则继续,返回第一个不相等元素比较的结果。
2,如果所有元素比较均相等,则长的列表大,一样长则两列表相等
示例如下:
>>> list1=[123]
>>> list2=[456]
>>> list2>list1
True
>>> list3=[456,789]
>>> list3>list1
True
>>> list3>list2
True
>>> list3>list3
False
>>> list4=[123,789]
>>> list2>list4
True
>>> list5=[5,1000]
>>> list3>list5
True6.2 列表相加
>>> list1
[123]
>>> list2
[456]
>>> list3=[5,1000]
>>> list1+list2
[123, 456]
>>> list1+list2+list3
[123, 456, 5, 1000]>>> list1+'程序员'
Traceback (most recent call last):
File "", line 1, in
list1+'程序员'
TypeError: can only concatenate list (not "str") to list
#这种情况会报错,是因为这里‘程序员’是字符串(str)类型,不是列表(list)类型,不能相加。我们可以将其用[]转化为list类型
>>> list1=[123]
>>> list1+['程序员']
[123, '程序员']6.3 列表的数乘
>>> list1
[123]
>>> list1*=8
>>> list1
[123, 123, 123, 123, 123, 123, 123, 123]
6.4 判断元素是否在列表中
我们可以直接用 <元素值 in/not in 列表名> 这种形式去判断元素是否在列表中。。
>>> name_list=['peter','william','jack','tom','alice','jim']
>>> 'peter' in name_list
True
>>> 'William'in name_list
False
>>> 'mary' not in name_list
True由上述编译结果2,我们可以看出在判断元素是否在列表内时,对于元素的判断是区分大小写的。
另外对于列表嵌套的情况,如果想要查询内置列表中的元素,需要多给定一个参数。
>>> names=['peter',['小甲鱼','牡丹'],'tom','jack']
>>> '小甲鱼' in names
False
>>> '小甲鱼' in names[1]
True
>>> names[1][0]
'小甲鱼'6.5 确定列表的长度
>>> name_list
['peter', 'william', 'jack', 'tom', 'alice', 'jim']
>>> len(name_list)
67.一些重要的操作
7.1 计数
count() 方法用于统计某个元素在列表中出现的次数。
>>> name_list
['peter', 'william', 'jack', 'tom', 'alice', 'jim', 'peter', ['小甲鱼', '牡丹'], 'tom', 'jack']
>>> name_list.count('peter')
27.2 找寻元素位置
index() 函数用于从列表中找出某个值第一个匹配项的索引位置。
>>> name_list
['peter', 'william', 'jack', 'tom', 'alice', 'jim', 'peter', ['小甲鱼', '牡丹'], 'tom', 'jack']
>>> name_list.index('peter')
0
>>> name_list.index('小甲鱼')
Traceback (most recent call last):
File "", line 1, in
name_list.index('小甲鱼')
ValueError: '小甲鱼' is not in list
>>> name_list[7].index('小甲鱼')
0 注意点:与count一致,如果需要找寻内置列表中元素的位置,先要确定内置列表在列表中的位置,即加一个参数。
同时index函数还能够切片使用,能够确定在某个范围内,第一个匹配项的索引值。
>>> name_list
['peter', 'william', 'jack', 'tom', 'alice', 'jim', 'peter', ['小甲鱼', '牡丹'], 'tom', 'jack']
>>> name_list.index('peter',3,10)
6拓展版(转载自:runoob.com)
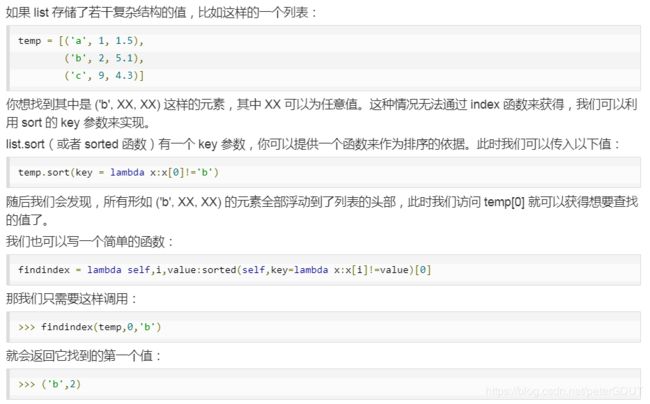
7.3 对列表进行顺序调整
7.3.1 调转列表
>>> name_list
['peter', 'william', 'jack', 'tom', 'alice', 'jim', 'peter', ['小甲鱼', '牡丹'], 'tom', 'jack']
>>> name_list.reverse()
>>> name_list
['jack', 'tom', ['小甲鱼', '牡丹'], 'peter', 'jim', 'alice', 'tom', 'jack', 'william', 'peter']7.3.2 对列表进行排序
使用list.sort对列表进行永久性排序。注意这里的排序只针对同种类型元素,混合列表会报错。
list.sort( key=None, reverse=False)1,这里的key是关键字, 默认是首字符的首字母排序。
2,reverse=False是升序,reverse=True是降序
>>> name_list
['jack', 'tom', ['小甲鱼', '牡丹'], 'peter', 'jim', 'alice', 'tom', 'jack', 'william', 'peter']
>>> name_list.sort()
Traceback (most recent call last):
File "", line 1, in
name_list.sort()
TypeError: '<' not supported between instances of 'list' and 'str'
#对于混合列表的情况,无法排序。 我们尝试将内部的列表先弹出,再对单元素进行排序,可以实现。
>>> name_list
['jack', 'tom', ['小甲鱼', '牡丹'], 'peter', 'jim', 'alice', 'tom', 'jack', 'william', 'peter']
>>> name_list.sort()
Traceback (most recent call last):
File "", line 1, in
name_list.sort()
TypeError: '<' not supported between instances of 'list' and 'str'
>>> name_list.pop(2)
['小甲鱼', '牡丹']
>>> name_list
['jack', 'tom', 'peter', 'jim', 'alice', 'tom', 'jack', 'william', 'peter']
>>> name_list.sort()
>>> name_list
['alice', 'jack', 'jack', 'jim', 'peter', 'peter', 'tom', 'tom', 'william']
>>> 对于嵌套列表,排序会按照内部列表的第一个元素的首字母进行排序。
>>> double_lists=[['jack', 'jim','peter'],['alice', 'jack'],['tom']]
>>> double_lists.sort()
>>> double_lists
[['alice', 'jack'], ['jack', 'jim', 'peter'], ['tom']]当然这里是顺序,如果想要逆序的话,可以用加入reverse参数
>>> double_lists
[['alice', 'jack'], ['jack', 'jim', 'peter'], ['tom']]
>>> double_lists.sort(reverse=True)
>>> double_lists
[['tom'], ['jack', 'jim', 'peter'], ['alice', 'jack']]另外如果想要对嵌套列表中第二个元素进行排序的话,可以加入关键字参数
def takeSecond(elem):
return elem[1]# 获取列表的第二个元素
double_lists=[['tom','baby'], ['jack', 'jim', 'peter'], ['alice', 'jack']]
double_lists.sort(key=takeSecond)# 指定第二个元素排序
print('排序列表:',double_lists)# 输出类别结果为:
排序列表: [['tom', 'baby'], ['alice', 'jack'], ['jack', 'jim', 'peter']]注意:这里sort给出的是永久性排序,更改后无法复原,如果希望能够保留原始数据,可以先拷贝,或者用sorted函数。
>>> name_list=['peter', 'william', 'jack', 'tom', 'alice', 'jim']
>>> sorted(name_list)
['alice', 'jack', 'jim', 'peter', 'tom', 'william']
>>> name_list
['peter', 'william', 'jack', 'tom', 'alice', 'jim']