Computer Vision Models, Learning, and Inference学习笔记(第一章)
(学习笔记包括原文大意的翻译,自己的理解和一些补充知识。)
计算机视觉的目标是从图像中提取有用的信息,这是一项艰巨的任务,现在还远不能做出一台“可视化”的计算机。
原因之一是视觉数据的复杂性:根据图1.1,这里面有许多的目标,并且几乎没有按照“典型姿势”摆放的,大多数都是被遮挡的,机器甚至不能够确定哪里是一个目标的开始的地方,哪里是一个目标结束的地方。举个例子:白色建筑和天空作为两个不同的物体,但是在连接处没有明显的变化;黑色汽车玻璃作为一个物体,却有明显的分界。
我们的视觉系统可以轻松的处理复杂的图像,比如统计图像中数目的个数或者画一幅街道布局图,甚至可以根据图像中人的肤色、汽车和树木的种类、天气等因素推理出图像发生的位置。
所以计算机视觉不是不可能的事情,但是绝对是有挑战的事情。肉眼看物体时,大脑会经过复杂的处理。比如:明亮环境下的煤炭和黑暗环境下的白纸。眼睛在明亮的环境下会获得更多的光子,但是大脑依然会认为煤炭是黑色的,白纸是白色的。这种复杂的处理,计算机很难完成。

图1.1
尽管如此,计算机视觉方面仍然取得一定进步。过去的十年,在消费者的计算机上开始大规模部署计算机视觉应用。例如:现在大多数的数码相机都嵌入了面部检测的算法;Microsoft Kinect(允许实时跟踪人体的外围设备)的畅销;这两者的原理本书后续都会解释。
近年来,计算机视觉的快速发展主要依靠处理能力、内存、存储容量的大幅增加,我们需要单独的保存单个高分辨率的图像。另一个原因:机器学习的使用越来越多,取得了长足的进步。机器学习不仅提供很多的工具,也能帮助我们理解现有的算法。
计算机视觉的未来令人兴奋。未来很可能普及。然而,这仍然是一门年轻的学科,试着让计算机去理解图1.1的场景仍然是不可想象的。可能需要很多年, 计算机才能以两岁孩子的思想去描述图像中的内容。但是这本书,提供了我们所取得的成就及这些背后的原则的“快照”。
本书的组织架构
本书结构如图1.2所示,分为六个部分。
本书的第一部分是概率相关的知识,概率模型是计算机视觉中非常有用的工具。
本书的第二部分讨论了机器视觉的机器学习,支撑我们所有方法的核心原则是“从图像中获取有用的信息”。我们建立相关的模型从图像数据获取有用的信息,学完这一章后,读者应该了解如何构建模型,来解决计算机视觉方面的问题。
本书的第三部分介绍计算机视觉的图形模型。图形模型提供一个框架,用来简化与之相关的模型。
本书的第四部分讨论了图像预处理。
本书的第四部分涉及几何计算机视觉,介绍了投影针孔摄像机。
最后,在本书的第六部分,我们介绍了几个视觉模型系列,这些模型涉及人脸识别、跟踪和对象识别。
附录中有本书中使用到的符号的介绍,以及线性代数的说明。
本书的更多详细信息(PPT 伪代码等)详见http://www.computervisionmodels.com
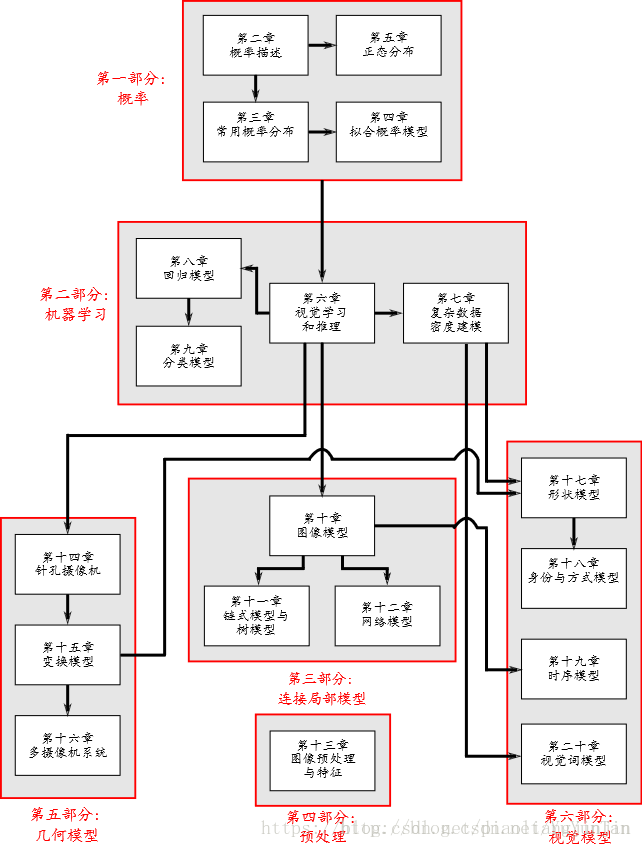
图1.2
关于计算机视觉的其他书籍
更多关于机器学习和图形模型我会推荐Bishop(2006)《模式识别和机器学习》Pattern Recognition and Machine Learning。
关于预处理的书籍Nixon & Aguado (2008)《特征提取与图像处理》Feature Extraction and Image Processing
几何计算机视觉的书籍:Hartley & Zisserman (2004).《多视图几何》Multiple View Geometry
一本综合概述计算机视觉的数Szeliski (2010). 《算法和应用》Algorithms and Applications