Zookeeper技术内幕 (一)数据存储和同步
数据结构和存储
从存储介质来看,Zookeeper的存储主要分为两部分:一部分是内存存储,另外一部分是磁盘存储
内存存储
如下三个图是Zookeeper将数据存储字在内存中最重要的三个数据结构。
- DataNode.java

DataNode是zookeeper内存数据存储的最小单位,是持久化数据节点描述的最小单位,属性解释如下:
| parent | 父节点的引用 |
| data | 该节点存储数据 |
| acl | acl控制权限 |
| stat | 持久化节点状态 |
| children | 子节点列表 |
- DataTree.java

DataTree从数据结构上来看是存储了当前zookeeper内存中所有的数据信息。具体属性描述如下:
| nodes | 持久化节点数据列表,key是path |
| dataWatches | 数据变更通知管理服务 |
| childWatches | 节点变更通知管理服务 |
| rootZookeeper | Zookeeper的根节点 |
| procZookeeper | Zookeeper管理和状态节点path |
| procChildZookeeper | Zookeeper管理和状态子节点path |
| quotaZookeeper | zookeeper配额管理节点path |
| quotaZookeeper | zookeeper配额管理子节点path |
| pTrie | 存储path映射成树状结构的信息 |
| ephemerals | 临时节点信息 |
| aclCache | acl缓存 |
- DataTree中Nodes是Map,存储的是ZK所有的节点。Key是path。
- 而存储临时节点的ephemerals也是Map,临时节点的Key并不是path,而是和session绑定,使用sessionId作为Key的
- ZKDataBase.java

负责管理Zookeeper的所有会话信息,事务日志dump和初始化工作。
| dataTree | 内存中所有的数据 |
| sessionsWithTimeouts | 客户端会话连接管理 |
| snapLog | 事务日志 |
以上是Zookeeper内存数据存储的结构。
磁盘存储
- 事务日志
一、事务日志可视化
Zookeeper的启动需要配置一些参数,其中就有针对日志输出的配置项。可以通过这个配置文件路径找到日志的输出位置,每个日志文件的大小都是64M,这是因为,事务日志都是采用预分配的方式,如果文件没有填充有效数据,用零补齐。之所以采用预分配的方式是因为,磁盘的IO相比较内存而言肯定是慢的,为了减少磁盘Seek,提高性能,采用了预分配的方式实现。所以ZK的事务日志可以单独挂在一个磁盘下。
|
java -cp .\zookeeper-3.4.10\dist-maven\zookeeper-3.4.10.jar ;.\zookeeper-3.4.10\lib\slf4j-api-1.6.1.jar org.apache.zookeeper.server.LogFormatter log.1 > 1.txt
|

第一行:是日志文件的DBID和版本号
第二行:一次客户端会话创建日志的记录,包括时间,类别,会话ID,cxid 客户端操作序列号,zxid,操作类型,超时时间。
第三行:区别在于日志结尾处,日志类型为error,-110是错误掩码,具体可以看KeeperException.java说明
第四行和第五行:日志操作时间,客户端会话ID,CXID,ZXID,操作类型,path,节点内容(上边两个都没有内容),权限信息,节点类型(F:持久节点;T临时节点),父节点的子节点版本号。
zookeeper具体格式化方法可以参看LogFormatter.java类。
二、事务日志的读写
事务日志的读写全部都在FileFxnLog.java文件中
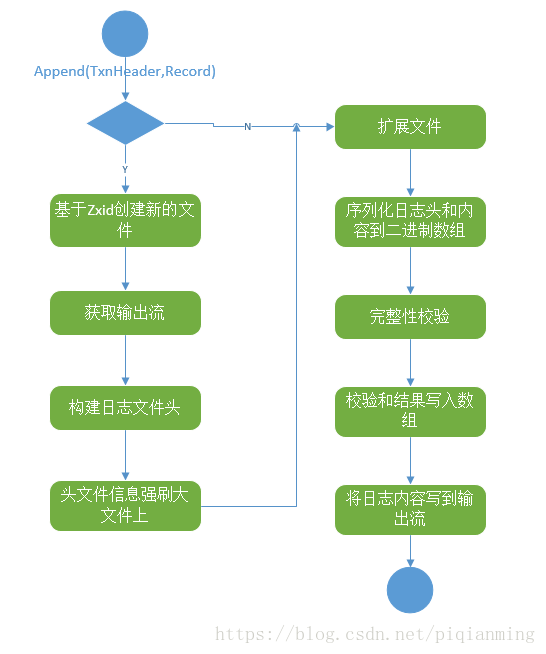
序列化日志到本地文件方法入口是public synchronized boolean append(TxnHeader hdr, Record txn)throws IOException,如下是主要流程图。
读取事务日志 方法:public TxnIterator read(long zxid) throws IOException,流程图如下:

读写事务日志时用到的配置参数解读:
| preAllocSize | 文件大小,默认是 65536 * 1024 byte ;zookeeper.preAllocSize |
| VERSION | 版本号,写死是2 |
| zookeeper.fsync.warningthresholdms | 调用fsync方法超时时间,默认是1000ms |
| fsync.warningthresholdms | 调用fsync方法超时时间,默认是1000ms |
| zookeeper.forceSync | 该参数确定了是否需要在事务日志提交的时候调用 FileChannel .force来保证数据完全同步到磁 盘 |
- 快照
一、日志可视化
zookeeper的数据在内存中是以树形结构进行存储的,而快照就是每隔一段时间就会把整个DataTree的数据序列化后存储在磁盘中,这就是zookeeper的快照文件。同样的,Zookeeper也为快照日志提供了可视化工具,具体使用方法如下:
![]()
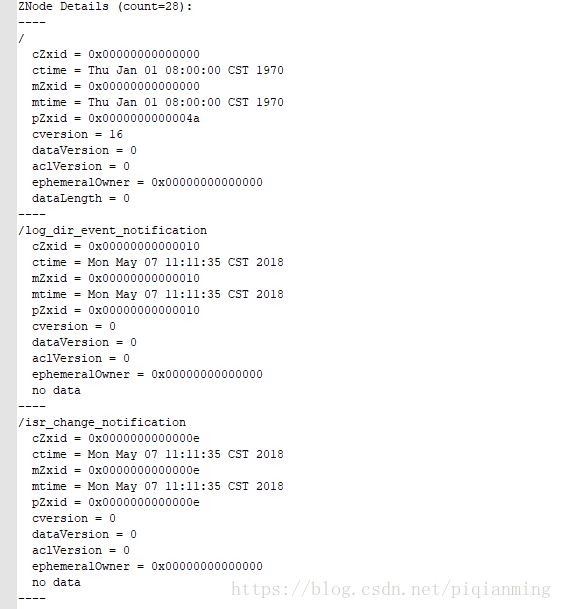
解释如下:
第一行:ZNode Details (count=11):ZNode节点数总共有11个
cZxid:创建节点时的ZXID
ctime:创建节点的时间
mZxid:节点最新一次更新发生时的zxid
mtime:最近一次节点更新的时间
pZxid:父节点的zxid
cversion:子节点更新次数
dataVersion:节点数据更新次数
aclVersion:节点acl更新次数
ephemeralOwner:如果节点为ephemeral节点则该值为sessionid,否则为0
dataLength:该节点数据的长度
二、快照日志的读写
org.apache.zookeeper.server.persistence.FileSnap是快照数据的读写接口。
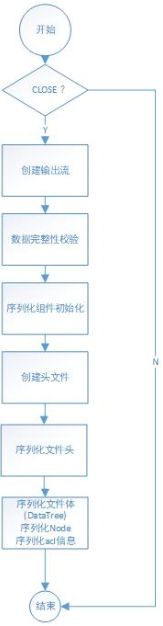
输出快照文件方法:public synchronized void serialize(DataTree dt, Map
读取快照文件方法:public void deserialize(DataTree dt, Map
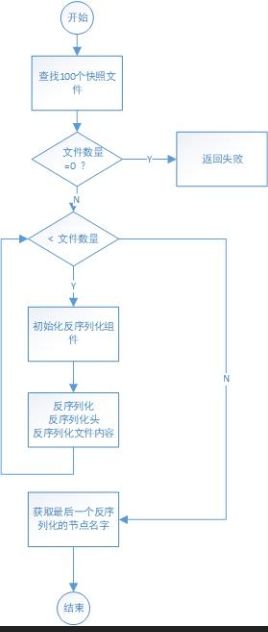
下图是反序列化的入口,默认读取100个快照文件,然后循环读取这100个文件,但问题是,循环一次之后就跳出了,代码贴出来了,可以看下,令人费解。
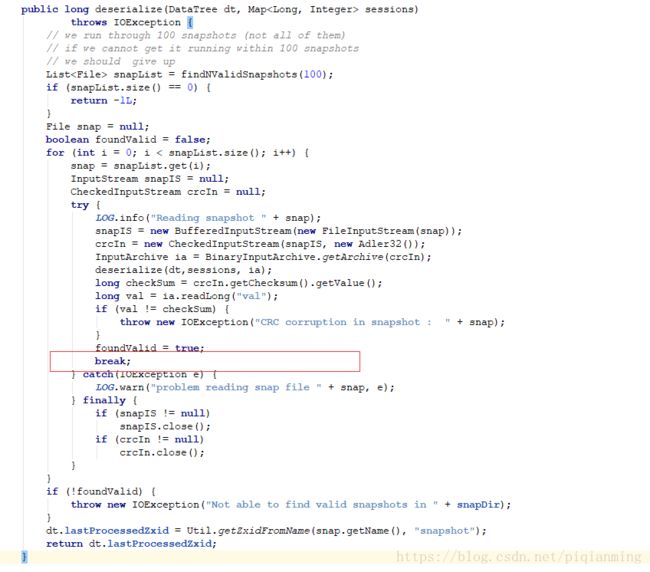
数据初始化和同步
- 数据初始化
如下是zookeeper启动过程分析(单例),loadDataBase是加载数据入口。
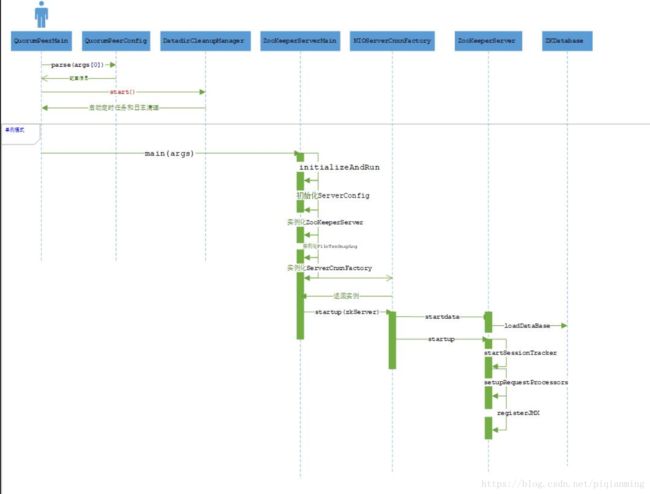
下面是基于loadDataBase进行的日志初始化过程。下图中关键环节比如读取快照和读取事务日志逻辑均在本文讲述。
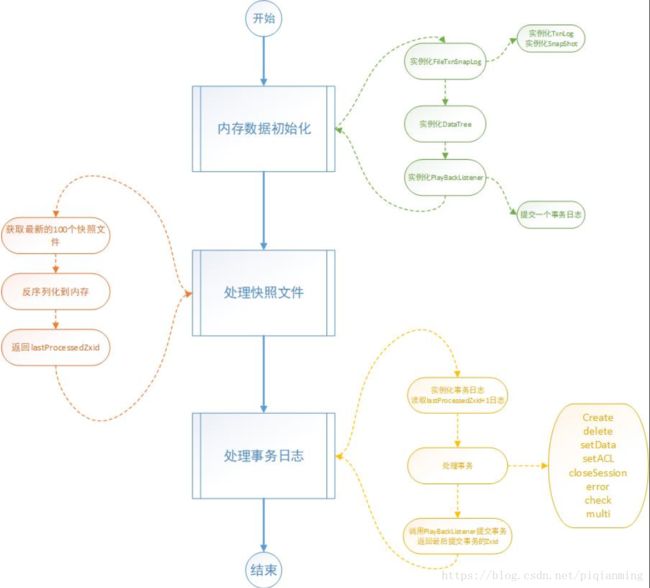
- 集群模式下的数据同步
数据和日志管理
Zookeeper将快照数据和事务日志分别存在dataDir和dataLogDir两个目录,正常运行过程中,Zookeeper会不断的把快照数据和事务日志输出到两个这两个目录中。如果没有人操作 的话,那么这个目录的内容会越累越多。因此,Zookeeper的日志需要运维人员及时进行清理。下面将几个比较常用的方案。
第一种:就是自己写一个脚本,定时清理两个目录下的日志文件
第二种:使用PurgeTxnLog进行清理。
第三种:使用自动化清理脚本zkCleanUp日志。
第四种:使用自动清理机制,配置autoPurge.snapRetainCount和autoPurge.purgeInterval两个参数进行自动化清理。这两个参数会在zookeeper启动后,读入,并单独起线程执行。详见DataDirCleanupManager类。