图半监督学习——标记传播
从书上301~304页的介绍可知,图半监督学习具有两个明显的缺点:
- 处理大规模数据时性能欠佳;
- 难以直接对新样本进行分类。
下面采用sklearn的半监督学习模块来验证上述特性。
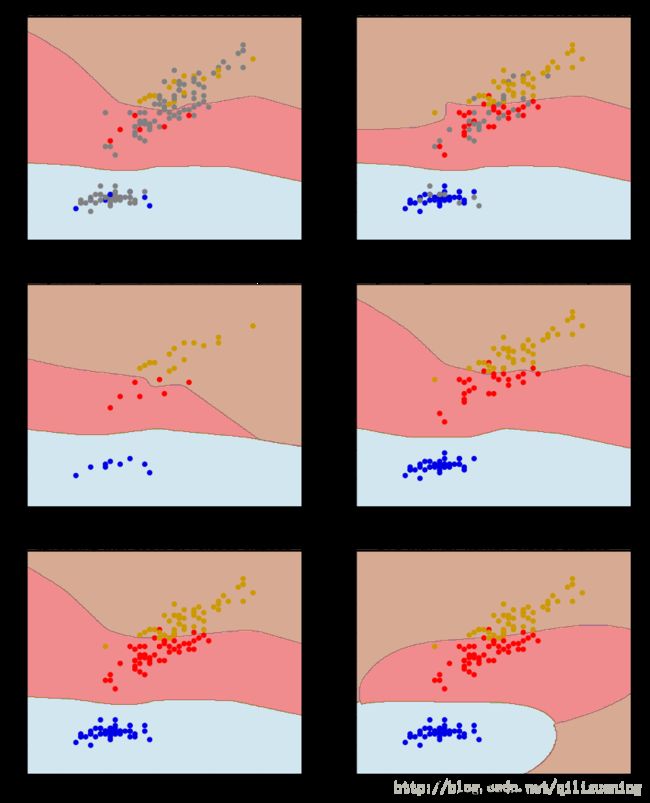
选用iris数据集的第1、3项属性开展测试,sklearn 的半监督学习算法是利用标记传播进行学习,具体又分为标记传播(Label Propagating)和标记扩散(Label Spreading),两者的差异在官方文档里已经说的很清楚,此处不再详述,此处采用的是标记传播,分别用不同比例的标记和未标记进行标记传播,并与SVM的结果进行对比(标记传播算法不能直接对新样本进行分类,sklearn中的label_propagating 采取的方法是对新样本重新进行一次学习来预测其标记),具体代码如下:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn import svm
from sklearn.semi_supervised import label_propagation
import time
rng = np.random.RandomState(0)
iris = datasets.load_iris()
X = iris.data[:, [0,2]]
y = iris.target
y_30 = np.copy(y)
y_30[rng.rand(len(y)) < 0.3] = -1
y_80 = np.copy(y)
y_80[rng.rand(len(y)) < 0.8] = -1
# create an instance of SVM and fit out data. We do not scale our
# data since we want to plot the support vectors
lu80 = (label_propagation.LabelSpreading().fit(X, y_80), X, y_80)
lu30 = (label_propagation.LabelSpreading().fit(X, y_30), X, y_30)
l20 = (label_propagation.LabelSpreading().fit(X[y_80 != -1], y_80[y_80 != -1]), X[y_80 != -1], y_80[y_80 != -1])
l70 = (label_propagation.LabelSpreading().fit(X[y_30 != -1], y_30[y_30 != -1]), X[y_30 != -1], y_30[y_30 != -1])
l100 = (label_propagation.LabelSpreading().fit(X, y), X, y)
rbf_svc = (svm.SVC().fit(X, y), X, y)
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, .02), np.arange(y_min, y_max, .02))
titles = [ 'spreading with 80% Du, 20% Dl', 'spreading with 30% Du, 70% Dl',
'spreading with 20% Dl', 'spreading with 70% Dl',
'spreading with 100% Dl', 'SVC with RBF kernel']
color_map = {-1: (.5, .5, .5), 0: (0, 0, .9), 1: (1, 0, 0), 2: (.8, .6, 0)}
fig = plt.figure(figsize=(14,18))
for i, (clf, x, y_train) in enumerate((lu80, lu30, l20, l70, l100, rbf_svc)):
start = time.time()
ax = fig.add_subplot(3, 2, i + 1)
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
ax.contourf(xx, yy, Z, cmap=plt.cm.Paired,alpha=.5)
colors = [color_map[y] for y in y_train]
ax.scatter(x[:, 0], x[:, 1], c=colors, cmap=plt.cm.Paired)
end = time.time()
ax.set_title('{0} : {1:.3f}s elapsed'.format(titles[i], end-start), fontsize=16)
ax.set_xlabel(iris.feature_names[0])
ax.set_ylabel(iris.feature_names[2])
plt.show()由下图可见,标记传播的性能相比于SVM下降了一倍(从运行时间来看),而从分类结果来看,采用20%有标记数据和80%未标记进行半监督学习就能达到大约使用70%~100%有标记数据的分类效果,且分类结果与SVM的结果接近,表明这种标记传播的半监督学习的效果还是比较好的。