kafka 中如何保证数据消息不丢失
背景
前几天,去两家公司面试,面试的过程中, 两家公司的面试官都给我提了如标题这样的一个问题。因为之前对kafka有一些了解,但是没有对这个的问题做过总结,现场就凭着记忆的进行了回答,面试官也表示这个问题基本可以通过。
回到家以后,重新回看了《kafka 权威指南》里的相关知识点,回想了一下自己在现场的回答,最多只是60分及格,但距离满分还相差甚远。
问题分析:
今天我们来分析一下这个问题。
先来回忆一下kafka 中消息传输的整个过程
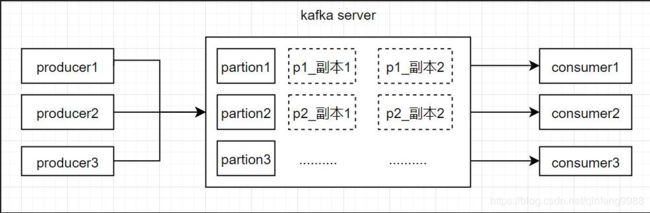
1、kafka 在producer 端产生消息,调用kafka producer client send方法发送消息
2、kafka producer client 使用一个单独的线程,异步的将消息发送给kafka server
3、kafka server收到消息以后,保存数据,并同步至副本
4、消息保存完成以后,返回给kafka producer client 端 【消息发送成功】
5、kafka consumer client 调用poll 方法,循环 从kafka server 端获取消息列表
6、kafka consumer 端 从kafka server获取到消息以后,开始消费消息
7、kafka consumer 消费消息完毕以后,向kafka server(topic为 _offset_consumer的消息队列) 发送偏移量
在上述的整个流程中,消息丢失的情况分为以几种可能性:
1、producer 端 发送消息给kafka server 端,中间网络出现问题,消息无法送达
2、kafka server端 在收到消息以后,保存消息时发生异常,异常分为三种
(1)可重试错误,通过重试来解决
(2) 网络连接错误
(3)无主(no leader)错误
3、consumer 在消费消息时发生异常,导致consumer端消费失败
注:当然这里还可能发生另一种错误,就是在producer发送消息到kafka server端时,消息体过大,producer client 直接抛出异常,导致发送失败
如何解决
1、producer 端的发送方式优化
我们先来了解一下,producer端发送消息的方式:
1.1 简单发送,无需关心结果
ProducerRecord record = new ProducerRecord<>(
"topicName","key","value"
);
try{
//这里只是把消息放进了一个缓冲区中,然后使用单独的线程将消息发送到服务端
producer.send(record);
}
catch(Exception){
e.printStackTrace();
} 1.2 同步发送
ProducerRecord record = new ProducerRecord<>(
"topicName","key","value"
);
try{
//send方法返回的是Future 对象,然后我们可以调用get()方法等待响应
Future future = producer.send(record);
future.get();
}
catch(Exception){
e.printStackTrace();
} 1.3 异步发送
private class DemoProducerCallback implements Callback{
@override
public void onCompletion(RecordMetadata recordMetadata,Exception e){
//发生错误的回调方法,可以写入日志,或写入DB通过其它线程重重试,保证最终的数据送达
}
}
ProducerRecord record = new ProducerRecord<>(
"topicName","key","value"
);
producer.send(record,new DemoProducerCallback())) 总结:从以上的三种发送方式中,我们可以知道,采用第一种方式发送时,消息丢失时我们的应用程序是无感知的,如果需要保证消息的不丢失,那么必须要选择第二种或者第三种(需要配合下一节中讲到的acks 参数),当然这里更推荐第三方种方式。
2、producer端的配置优化
在producer 端的配置项中有很多的配置项,我们摘出几种比较重要的来一一解读:
acks:该参数指定了,kafka server的多少个副本收到消息以后才算真的正消息发送成功。取值范围:
- acks = 0 表示producer 在将消息成功写入到 kafka server 之前不会收任消息
- acks = 1 表示只要kafka server 集群中的leader节点收到消息,producer 端就会收到kafka server的成功响应
- acks = all 表示只有当消息到leader节点,并且这条数据也同步到了所有副本中,producer 才会收到kafka server的成功响应。
buffer.memory:生产端 缓冲区的大小设置
compression type:生产端采用的数据压缩方式,取值 snappy,gzip,lz4,默认不会压缩。(启用压缩意味着,需要producer 和kafka server要占用更多的cpu资源)
retries:生产端发送消息到kafka server时,发生临时性错误以后,生产者发送消息到kafka server端重试的次数。如果重试超过该次数,则发生异常
batch.size: 当多个消息被发送至同一分区时,生产者会把它们发送到同一批。该参数指定了同一批次可以使用的内存大小,按字节数计算(而不是消息条数)。
linger.ms:该参数指定了生产者在发送批次之前等待更多消息加入批次的时间,producer client 会在批次填满(batch.size) 或linger.ms 到上限时,将消息发送至kafka server.
max.in.flight.requests.per.connection:该参数指定了生产者在收到kafka server 的成功响应之前,可以发送多少消息。(可以利用该配置让kafka server中的消息变得有序)
max.request.size:该参数用来控制生产者发送单个请求的数据大小。对于消费端也有相同的配置(message.max.bytes),建议两边设置相同。
总结:我们的问题,可以通过设置配置项 acks 、retries 来保证数据的不丢失。acks=1时,lead节点只要收到消息就会告诉producer消息接收成功,假如此时lead 挂掉了开始重新选主,选主成功后之前lead收到的那条消息就会丢失,如果需要保证消息的绝对不丢失,建议设置 acks =all
3、kafka server
这里需要补充一个知识点,kafka的server端同一个topic下有多个分区,单个分区会有不同的副本。如果producer 发送消息么kafka server端,leader收到了消息以后,告诉producer 发送成功,此时再同步消息到多个副本,但由于某一个副本同步较慢,此时leader挂了,需要选主,选主的过程中,一旦那个较慢的副本成为新的leader,那么新的leader中就不包含了原leader收到的那条最新数据,导致消息丢失。
broker中的配置项,unclean.leader.election.enable = false,表示不允许非ISR中的副本被选举为首领,以免数据丢失。
ISR:是指与leader保持一定程度(这种范围是可通过参数进行配置的)同步的副本和 leader 共同被称为ISR
OSR:与leader同步时,滞后很多的副本(不包括leader)被称为OSR
AR,分区中所有的副本统称为AR。AR = ISR + OSR
4、kafka consumer端的优化
kafka consumer的配置中,默认的enable.auth.commit = true,表示在kafka consumer 通过poll方法 获取到消息以后,每过5秒(通过配置项可修改)会自动获取poll中得到的最大的offset, 提交给kafka server 中的_offset_consumer(存储 offset 的特定topic )
如果enable.auth.commit = false时,则关闭了自动提交,你可以手动的通过应用程序代码进行提交,这里我来梳理一下,consumer 消费消息的整个流程
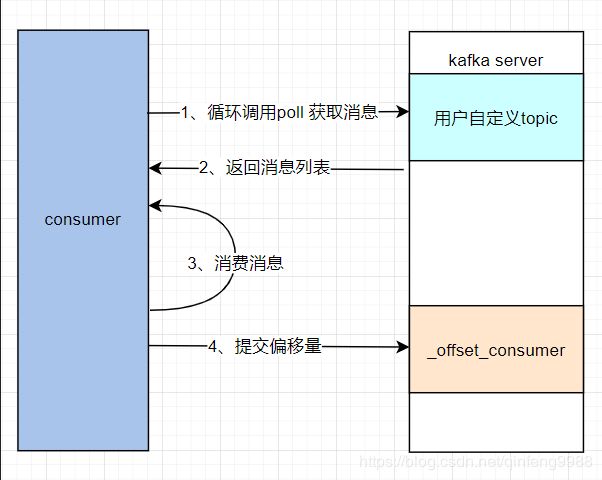
- consumer端循环向kafka server请求获取信息
- 如果kafka server中的分区中没有消息,则阻塞指定秒数(consumer端配置)后,返回给consumer端
- 如果 kafka server中有消息 或是在阻塞等待的过程中有消息写入,则立即返回给consumer端
- consumer开始消费消息
- consumer消费消息完毕以后,提交偏移量到topic为 _offset_consumer(kafka server端) 的消息队列
我们来看一下,enale.auto.commit = false时,如何手动提交的
public void consumerMsg(){
while(true){
//这里的poll(100)指的是kafka server端没有消息时,连接等待的时间,超过该时间立即返回空给consumer
ConsumerRecords records = consomer.poll(100);
for(ConsumerRecord record : records){
// 这里是消费消息的逻辑(简单逻辑输入到控制台)
System.out.printIn(record.value));
//提交偏移量
try{
consumer.commitSync(); //同步提交 如果异步的话,可以使用 consumer.commitAsync();
}
catch(CommitFailedException ex){
log.error("commit fail");
}
}
}
}
consumer端消息丢失的情况分为两种:
- consumer 端启用了 enable.auto.commit= true,在消费消息时发生了异常
- consumer 端 enable.auto.commit= false,但是在消息消费之前,提交了offset
针对这两种丢失的情况,我们做以下处理:
1、设置 enable.auto.commit = false
2、在consumer端消费消息操作完成以后 再提交 offset,类似于上文中的代码示例
写在最后:
以上的我们从producer 、 kafka server、 consumer 端出发,通过相关的优化手段保证消息的不丢失,当然业界还有一些其它的办法,比如在三种 send 的 调用方式中,callback时将消息写入到mysql 或日志中,当consumer 消费消息成功以后,我们从mysql 或 日志中删除消息,未成功消费的消息,可以启动一个线程,将消息重新入队让consumer收到消息以后重新消费(rabbit mq中 可以 利用死信队列和备用交换机来完成)
参考资料:《kafka 权威指南》第四章