找对象那么难?python s3cmd 帮你解决
文章目录
- 安装
- 配置
- 使用
- 常用方法
- 创建桶
- 列举桶
- 上传对象
- 下载对象
- 列举对象
- Python 代码封装
- 调试
- pdb 调试
- s3cmd --debug
s3cmd 是一个 python 实现的知名的 s3 客户端工具,能非常方便和人性化的手段让你使用 s3 对象存储。
官网链接:https://s3tools.org/s3cmd
github链接:https://github.com/s3tools/s3cmd
安装
在 centos 在可以直接安装:
yum install s3cmd
配置
调用 s3cmd --configure 进行配置,配置完成之后会在主目录生成一个 .s3cfg 文件,你 cat ~/.s3cfg 就能看到了。
s3cmd --configure
其中最关键的几个配置:
access_key = 你的 ak
secret_key = 你的 sk
host_base = localhost:20000 // 你的 S3 服务器 endpoint
host_bucket = localhost:20000/%(bucket) // path 模式
其他的自行斟酌配置,配置项还挺多的,s3cmd 的功能还挺多。
s3cmd ls # 列举所有的桶
输出例子:
hostname$ s3cmd ls
2020-04-10 10:47 s3://qiya-bucket-1
使用
使用非常简单,这个也是 s3cmd 相比 s3curl 这类原始工具更友好的地方:
常用方法
创建桶
s3cmd mb s3://mybucket
mb 就是 makebucket的意思;
示例:
root@ubuntu:~# s3cmd mb s3://qiya-bucket
Bucket 's3://qiya-bucket/' created
列举桶
列举所有桶
s3cmd ls
示例:
root@ubuntu:~# s3cmd ls
2020-04-12 03:26 s3://qiya-bucket
上传对象
把一个对象上传到桶里
s3cmd put some-file.xml s3://mybucket/somefile.xml
示例
root@ubuntu:~/temp# s3cmd put ./somefile.xml s3://qiya-bucket/somefile.xml
upload: './somefile.xml' -> 's3://qiya-bucket/somefile.xml' [1 of 1]
1967 of 1967 100% in 0s 6.85 kB/s done
root@ubuntu:~/temp# md5sum somefile.xml
610ba3d5d83b67a687f09f0968c6b2cb somefile.xml
下载对象
把一个对象下载下来
s3cmd get s3://mybucket/somefile.xml some-file-2.xml
示例:
root@ubuntu:~/temp# s3cmd get s3://qiya-bucket/somefile.xml somefile.xml.2
download: 's3://qiya-bucket/somefile.xml' -> 'somefile.xml.2' [1 of 1]
1967 of 1967 100% in 0s 21.87 kB/s done
root@ubuntu:~/temp# md5sum somefile.xml
610ba3d5d83b67a687f09f0968c6b2cb somefile.xml
列举对象
列举桶里的对象
s3cmd ls s3://mybucket
Python 代码封装
s3cmd 是一个纯 python 项目,实现了 s3 协议的封装,对外提供友好的命令行格式。下面以一个 s3cmd ls 列举桶的命令执行来梳理分析。
s3cmd 安装好之后(以下用 ubuntu 上分析举例),s3cmd 这个可执行文件会处于系统 PATH 目录下,s3cmd 本质上就是一个没有 py 后缀的 python 文件。
root@ubuntu:~/temp# which s3cmd
/usr/bin/s3cmd
root@ubuntu:~/temp# ll /usr/lib/python2.7/dist-packages/|grep -i s3
drwxr-xr-x 2 root root 4096 Feb 11 20:12 S3/
drwxr-xr-x 2 root root 4096 Feb 11 20:12 s3cmd-1.6.1.egg-info/
组件要素:
- 可执行 python 文件 s3cmd 在PATH路径下:主要是做命令行参数解析,业务逻辑的实现等,比如是
ls,put,get,等等 - S3 python 包在 python 的第三方库的安装目录:这个库实现 S3 协议的封装,解析,发包,收包等操作
命令的 map 表:
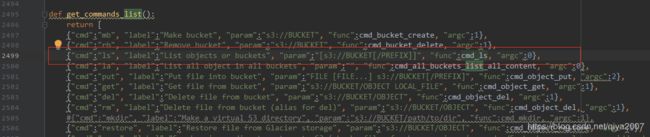
所以 s3cmd ls 这个映射到执行 cmd_ls 这个函数的逻辑。我们发送协议包给对象存储服务,有两个必须的要素:
- 身份标识(ak/sk)
- endpoint(你发给谁?)
这两个东西我们命令行里面没有传,那么哪里来的?还记得配置文件 .s3cfg 把,就是写在这个里面。 每个命令进来第一件事,就是把这个配置捞出来:
def cmd_ls(args):
# 读取 .s3cfg 配置
cfg = Config()
# 构造一个 s3 请求的客户端对象
s3 = S3(cfg)
if len(args) > 0:
uri = S3Uri(args[0])
if uri.type == "s3" and uri.has_bucket():
# 发送 s3 请求到后端
subcmd_bucket_list(s3, uri, cfg.limit)
return EX_OK
# 发送 s3 请求到后端
subcmd_all_buckets_list(s3)
return EX_OK
subcmd_all_buckets_list 主要做两个逻辑:
- 构造一个 s3 请求对象
- 然后把 http 请求发出去
(Pdb) bt
-> rc = main()
-> rc = cmd_func(args)
-> subcmd_all_buckets_list(s3)
-> response = s3.list_all_buckets()
# 构造请求
-> request = self.create_request("LIST_ALL_BUCKETS")
# 发包走
-> response = self.send_request(request)
request 方法如下:
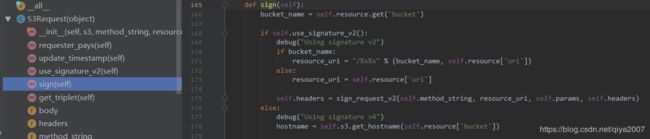
逻辑很简单,那么构造的 request 有什么特别的呢?最关键的是签名,当前 s3 支持两种签名:v2,v4 的签名。v4 签名较为严格,是 AWS 当前推荐的一种签名,甚至要对 body 进行签名,提供 content-md5 ,v2 签少许的一些头部即可。
调试
作为一个程序员,如果大家是第一次工具,那么会想要自己执行一把,最好能单步调试,这里推荐两个方法(后面我会梳理一篇关于 python 调试的分享 ):
- 使用 pdb 单步调试
- 使用 s3cmd --debug 功能调试
pdb 调试
pdb 调试是我最为推荐的一种调试方式,pdb 是 python 的标准库,能够让你单步调试。有两种方式:
- 代码侵入式:添加
pdb.set_trace(), 那么程序跑到这个地方的时候,就会被断点到 - 非侵入式:直接执行命令的时候,声明加载使用 pdb 库
执行命令:
python -m pdb /usr/bin/s3cmd ls
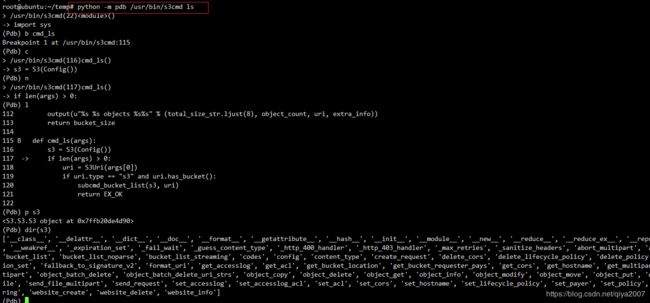
这样你就能愉快的单步调试了,看到每一个对象和执行步骤。这个是通用的调试方法,适用于任何 python 程序。
s3cmd --debug
这个是 s3cmd 提供的调试选项,执行的时候,加入了这个选项,那么就能知道 s3cmd 执行的每一个步骤了。
执行步骤:
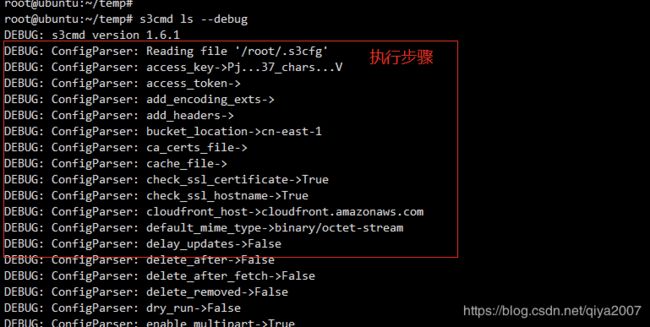
包头,响应也打印出来了:
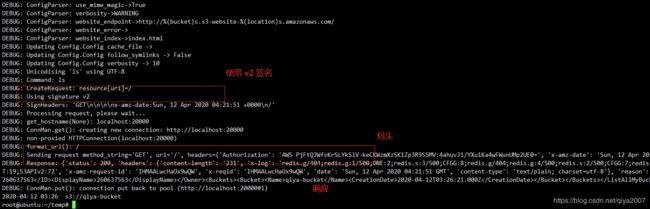
我们看到使用v2签名,头部签名字段为authorization。
坚持思考,方向比努力更重要。关注我:奇伢云存储