Spark初体验(配置超详细)
一乡二里共三夫子不识四书五经六义竟敢教七八九子十分大胆!
十室九贫 凑得八两七钱六分五毫四厘 尚且三心二意 一等下流

前言
这里,不谈spark原理,作用,使用场景等,只是一个spark与java打通的一个过程。看似简单,整整花了哥两天的时间,版本号的坑,服务器的坑等等,头胀的能飘起来~!按照我下面说的环境和步骤去做,保证你99%能一次跑过,因为我是一边写此篇一边在新的虚拟机配置。一切都ok~
环境
| 名称 | 版本号 |
|---|---|
| Linux | CentOS Linux release 7.0.1406 (Core) |
| jdk | 1.8.0_121 OpenJDK 64-Bit Server VM (build 25.121-b13, mixed mode) |
| scala | Scala code runner version 2.10.4 – Copyright 2002-2013, LAMP/EPFL |
| spark | spark-1.6.2-bin-hadoop2.6 |
环境部署(超详细)
最好把当前Linux的镜像库文件更换掉,这里我用的是163的 传送门 讲解得很详细
卸掉默认的jdk版本
[root@localhost ~]# rpm -qa|grep jdk
java-1.7.0-openjdk-headless-1.7.0.51-2.4.5.5.el7.x86_64
java-1.7.0-openjdk-1.7.0.51-2.4.5.5.el7.x86_64得到目前jdk的版本,然后删除
yum -y remove java java-1.7.0-openjdk-headless-1.7.0.51-2.4.5.5.el7.x86_64然后安装下载好的jdk,用到的软件都放在了文末,或者自己去下载或者去各自的官网下载
tar -xvzf jdk-8u121-linux-x64.tar.gz 解压好之后,创建个软连接,方便以后更改版本
ls -sf /usr/local/software/jdk1.8.0_121/ /usr/local/jdk按照此方法分别对scala和spark操作,配置后结果如下
.
├── bin
├── etc
├── games
├── include
├── jdk -> /usr/local/software/jdk1.8.0_121
├── lib
├── lib64
├── libexec
├── sbin
├── scala -> /usr/local/software/scala-2.10.4
├── share
├── software
├── spark -> /usr/local/software/spark-1.6.2-bin-hadoop2.6
└── src然后将其分别添加到系统的全局变量
vi /etc/profile在文件的最末端添加下面代码,注意格式
export JAVA_HOME=/usr/local/jdk
export SCALA_HOME=/usr/local/scala
export SPARK_HOME=/usr/local/spark
export PATH=.:${JAVA_HOME}/bin:${SCALA_HOME}/bin:${SPARK_HOME}/bin:$PATH最后一定要执行下面命令,作用就是即时生效
source /etc/profile然后就可以查看版本号了
java -version
scala -version到此,spark的环境就部署好了,我这边代码依赖管理用的是maven,还需要配置下maven环境,
这里我直接用的yum安装了
yum install maven等待安装完毕,在改一下maven的中央仓库镜像地址,否咋,spark需要的几个jar包会下载到你怕为止.
这里maven的地址可以通过mvn -version去查看
Maven home: /usr/share/maven
Java version: 1.8.0_121, vendor: Oracle Corporation
Java home: /usr/local/software/jdk1.8.0_121/jre
Default locale: en_US, platform encoding: UTF-8
OS name: "linux", version: "3.10.0-123.el7.x86_64", arch: "amd64", family: "unix"都给你列出来了233333
然后修改mirrors
vi /usr/share/maven/conf/settings.xml找到节点
添加阿里云的镜像地址
<mirror>
<id>alimavenid>
<name>aliyun mavenname>
<url>http://maven.aliyun.com/nexus/content/groups/public/url>
<mirrorOf>centralmirrorOf>
mirror>保存一下,ok
启动spark服务
在启动之前,还需要做些处理
在spark的conf中,修改下配置文件
cp spark-env.sh.template spark-env.sh
vi spark-env.sh.template再开头添加环境
export JAVA_HOME=/usr/local/jdk
export SCALA_HOME=/usr/local/scala我也不知道这里为什么也要配置。。。
回到spark根目录
sbin/start-master.sh 在主机网页输入地址http://yourip:8080/ 访问,如果访问不到,说明虚拟机的防火墙打开了,这里要关掉
···bash
service firewalld stop
再次刷新页面,ok,如下

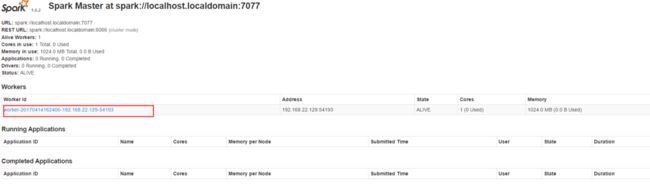
这里还要继续启动worker
```bash
bin/spark-class org.apache.spark.deploy.worker.Worker spark://localhost.localdomain:7077
<div class="se-preview-section-delimiter">div>
再刷新下页面,ok,如下
编写Java代码
这里说一下,spark支持java、scala和python,无论用什么都只是对业务的封装,当然了原配是scala,我这里使用的java去实现一个计数程序,(目前网上有关spark的教程的第一个demo都是计数程序,我简称spark为“hello wordcount”),我用maven来管理依赖关系,这个版本号一定要 注意!注意!注意!
本地的要和虚拟机里配置的要一毛一样!!!
代码很简单,怎么计数自己去实现
public class WorldCount {
private static final Pattern SPACE = Pattern.compile(" ");
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName("vector's first spark app");
JavaSparkContext sc = new JavaSparkContext(conf);
//C:\Users\bd2\Downloads
JavaRDD lines = sc.textFile("/opt/blsmy.txt").cache();;
JavaRDD words = lines.flatMap(new FlatMapFunction() {
public Iterable call(String s) throws Exception {
return Arrays.asList(SPACE.split(s));
}
private static final long serialVersionUID = 1L;
});
JavaPairRDD ones = words.mapToPair(new PairFunction() {
private static final long serialVersionUID = 1L;
public Tuple2 call(String s) {
return new Tuple2(s, 1);
}
});
JavaPairRDD counts = ones.reduceByKey(new Function2() {
private static final long serialVersionUID = 1L;
public Integer call(Integer i1, Integer i2) {
return i1 + i2;
}
});
List> output = counts.collect();
for (Tuple2 tuple : output) {
System.out.println(tuple._1() + ": " + tuple._2());
}
sc.close();
}
}
"se-preview-section-delimiter">
注意这里没有.setMaster(),这个参数在虚拟机执行的时候通过手动配置
再来就是依赖配置文件pom,我已经亲测,可以直接拿过去用
<properties>
<scala.version>2.10.4scala.version>
<spark.version>1.6.2spark.version>
properties>
<dependencies>
<dependency>
<groupId>org.scala-langgroupId>
<artifactId>scala-libraryartifactId>
<version>${scala.version}version>
dependency>
<dependency>
<groupId>com.googlecode.json-simplegroupId>
<artifactId>json-simpleartifactId>
<version>1.1.1version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_2.10artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-launcher_2.10artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-mllib_2.10artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-streaming_2.10artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>4.4version>
<scope>testscope>
dependency>
<dependency>
<groupId>org.specsgroupId>
<artifactId>specsartifactId>
<version>1.2.5version>
<scope>testscope>
dependency>
<dependency>
<groupId>org.ansjgroupId>
<artifactId>ansj_segartifactId>
<version>5.1.1version>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-assembly-pluginartifactId>
<version>2.3version>
<configuration>
<appendAssemblyId>falseappendAssemblyId>
<descriptorRefs>
<descriptorRef>jar-with-dependenciesdescriptorRef>
descriptorRefs>
<archive>
<manifest>
<mainClass>WorldCountmainClass>
manifest>
archive>
configuration>
<executions>
<execution>
<id>make-assemblyid>
<phase>packagephase>
<goals>
<goal>assemblygoal>
goals>
execution>
executions>
plugin>
plugins>
build>
<div class="se-preview-section-delimiter">div>
打jar包的时候,我建议将src和pom上传到虚拟机,在虚拟机里打包,因为打成jar包后大概有上百兆大小,我是在虚拟机打包的,如下
[root@localhost co]# ll
total 8
-rw-r--r--. 1 root root 3401 Apr 14 13:47 pom.xml
-rw-r--r--. 1 root root 2610 Apr 14 16:35 sparkjar.zip
drwxr-xr-x. 4 root root 28 Apr 14 09:00 src
[root@localhost co]# mvn package
"se-preview-section-delimiter">
第一次打包的时候可能会用到十几分钟的时间,因为需要用到的包太多了。打包成功之后,记住对应jar包地址
提交任务给spark
我这里下载了英文版的《巴黎圣母院》作为解析文本,并放在了/opt/目录下
bin/spark-submit --master spark://localhost.localdomain:7077 --class WorldCount /usr/local/co/target/spark.jar-1.0-SNAPSHOT.jar
"se-preview-section-delimiter">
没有特殊情况的话,结果会输出在屏幕上,部分如下
Djali!: 2
faintly: 7
bellow: 1
prejudice: 1
singing: 15
Pierre.��: 1
incalculable: 1
defensive,: 1
slices: 1
niggardly: 1
Watch: 2
silence,: 14
water.��: 1
inhumanly: 1
17/04/14 16:59:35 INFO SparkUI: Stopped Spark web UI at http://192.168.22.129:4040到此一个spark与java程序彻底打通了。。。
后续,我会使用spark对公司项目进行改造,将数据处理交给spark去做。我会一一记录分享出来
总结
- 环境部署的要正确,版本号要统一
- spark启动的顺序
sbin/start-master.sh# 启动服务bin/spark-class org.apache.spark.deploy.worker.Worker spark://localhost.localdomain:7077# 启动workerbin/spark-submit --master spark://localhost.localdomain:7077 --class WorldCount /usr/local/code/target/spark.jar-1.0-SNAPSHOT.jar# 提交任务
| 名称 | 地址 |
|---|---|
| 用到的软件 | http://pan.baidu.com/s/1skN5NS5 密码:ufhk |
| 《巴黎圣母院》 | 链接:http://pan.baidu.com/s/1qXZJedI 密码:vljg |