关系型数据库到文档型数据库的跨越
1. 简介
在文档型NoSQL数据库出现之前,许多开发者一直绞尽脑汁思考,希望能想出更好的处理关系型数据库技术的方法,如今他们可能要跳出那种思维而另辟蹊径。本文将介绍关系型数据库和分布式文档型数据库的区别以及在应用开发上的一些建议。
2. 转变的原因
人们通常都不愿意改变,因为改变总是痛苦的,除非它能显著解决一些问题。随着大数据的发展,我们越来越有必要开始对数据模型做出转变了。换句话说,这种转变的需求愈发的强烈,因为大数据时代不管是对于数据库的 扩展模型 还是 数据模型 都要求极高的灵活性。
2.1 扩展模型
关系型数据库是一种“纵向扩展”的技术,想要扩展容量(无论数据存储还是I/O),都需要更换更大的服务器。现代应用结构的解决却是使用“横向扩展”—-无需新购买更大的服务器,只需要在负载均衡器下增加一般的服务器、虚拟机或是云服务器就可以实现扩展。此外,容量在不再需要的时候还可以轻易的缩减。事实上,“横向扩展”在应用逻辑层的使用已经很广泛了,只是数据库技术上刚刚赶上而已。
2.2 数据模型
NoSQL“横向扩展”部署方案的优点已经受到了业界的注意,但是同时很多人忽略的是NoSQL数据管理的简洁,不需要很复杂的操作模式构建,这一点对于数据库的提升也和扩展模型一样重要。在使用传统关系数据库时,添加数据前,需要定义操作模式。之后每一条记录的加入都需要严格的按照定义的操作模式进行,比如固定的列数和数据类型。因此,改变那些分区关系型数据库的操作模式,会非常的麻烦。如果你的数据获取和数据管理需求经常变化,那这种严格的模式限制将会成为制约表现的屏障。NoSQL(无论文档型、列式、K-V等等)都是水平扩展的,它们都不需要预先定义操作模式、所以也不需要在需求改变时改变操作模式。接下来我就将使用SequoiaDB来介绍文档型NoSQL数据库技术。
3. 数据模型: 关系型vs文档型
下图就对比了四条记录在关系型和文档型数据模型下的存储情况:

3.1 关系型数据模型
如上所示,关系型数据库中的每一条记录存储都需要遵守一个固定的模式—-固定的列数,每一列都是有特定的意义而且规定了数据类型。如果要获取不同的数据,数据库的模式就需要重新修改。
此外,关系型模型还有一个特点就是“数据库标准化”,也就是大的表会被压缩成小的、整合的表,如下图所示:
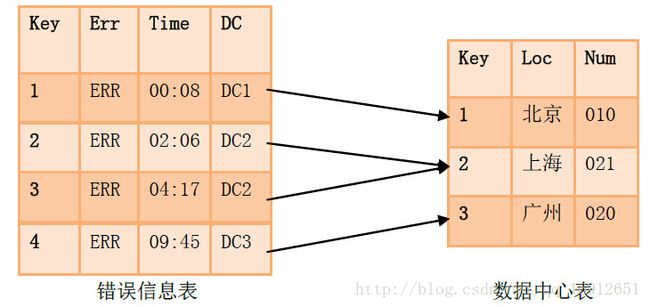
在上面的例子中,数据库用来存储错误日志信息。每个错误记录(左表中的一行)由3部分组成:错误号ERR,错误发生的时间TIME,和错误发生的数据中心DC。为了避免重复记录数据中心信息,现在每条错误记录将都指向右表(数据中心信息)中的对应的地点那一条记录。这样就不需要实际存储具体的DC信息在左表中,符合传统的数据库范式。
在关系模型当中,多个表中的不同记录经常“交错连接”,一些数据会被多条记录共享。这样的好处就是减少了重复数据的出现,但是这样不好的地方就是一旦其中某一条链接的记录发生改变,那么与其相关的记录和表都会被锁住以防止非一致性的出现。 ACID事务在关系型数据库中是很复杂的,因为数据会扩散。即便是单一条记录,这复杂的共享数据内部关系网的存在,也使得关系型数据在多个服务器之间的传递变得复杂而缓慢,同时让读和写操作的性能变差,不利于分布式。
当存储空间昂贵又稀少时,折中的权衡方案是很必要的。然而,如今存储空间的价格跟40年前相比已经大大的下降了,很多时候计算折中方案已经完全没有必要。使用更多的存储空间来换取更好的操作性能,或者是将工作负载分配到多台机器上,这才是如今应用上更好的解决方案。
3.2 文档型数据模型
使用“文档”这个词似乎让人觉得奇怪,但是其实 “文档型数据模型”真的和传统意义的文字“文档”没有什么关系。他不是书、信或者文章,这里说的“文档”其实是一个数据记录,这个记录能够对包含的数据类型和内容进行“自我描述”。XML文档、HTML文档和JSON 文档就属于这一类。SequoiaDB就是使用JSON格式的文档型的数据库,它的存储的数据是这样的:
{
"_id": {
"$oid": "57b44b2b2b57085321000001"
},
"items": [
{
"shopid": 8224,
"picture": "http://avatar.csdn.net/B/1/9/1_qq_16912651.jpg",
"amount": 1,
"price": "117.59",
"itemname": "Coffee",
"itemid": 194987
},
{
"shopid": 9291,
"attribute": [
{
"color": "Blue",
"size": "M"
},
{
"color": "Pink",
"size": "M"
}
],
"picture": "http://avatar.csdn.net/B/1/9/1_qq_16912651.jpg",
"price": "17.63",
"itemname": "T-shirt",
"itemid": 543514
}
],
"isactive": true,
"uid": 123456
}可以看到,数据是不规则的,每一条记录包含了所有的有关“SequoiaDB”的信息而没有任何外部的引用,这条记录就是“自包含”的。这就使得记录很容易完全移动到其他服务器,因为这条记录的所有信息都包含在里面了,不需要考虑还有信息在别的表没有一起迁移走。同时,因为在移动过程中,只有被移动的那一条记录(文档)需要操作而不像关系型中每个有联系的表都需要锁住来保证一致性,这样一来ACID的保证就会变得更快速,读写的速度也会有很大的提升。
4. 文档型数据模型的应用
你可能需要一段时间去忘记以前的习惯,不过不要害怕,了解其他方面的知识可以让你更充分的利用你已经学会的知识,不管怎么样最能解决问题的才是最好的。了解了不同的方法,你才可以选择最适合的!
4.1 模型
在应用中,数据对象是核心的部分—–也是模型视图控制器(MVC)中的模型层。当分析一款应用时,现在你可以先把目光停在对象关系映射层(ORM)上。与其将不同的模型定制成为不同的表和行,不如都用JSON格式存储成文档形式吧,每个JSON文档都有唯一的id方便查找。
4.2 键
在文档型数据库中,每个JSON文档的ID就是它唯一的键,这也大致相当于关系型数据库中的主键。通常ID在一个数据库“集合”中是唯一的(NoSQL中,类似RDBMS的“表”的分类结构有很多种,如SequoiaDB的集合Collection或者是Couchbase的bucket)。一些NoSQL数据库会用ID排序,那么相近ID的数据自然更容易被检索到,经常需要一起调用的数据放在一起可以大大提升处理的速度。
4.3 灵活性
如今的社交网站越来越普及,而随着用户量不断壮大,每个用户的使用方式或者是发布的内容类型都不尽相同。有人会发布风景照片、有人发布对时事的评论还有人分享音乐表达心情。面对如此大量而多样性的数据,如果使用关系型模型,就需要不断你的修改数据操作模式,这样,可能会引起系统负载的大大提升,同时也会大大增加处理的时间。
这时,文档型模型存储就凸显其优点了,面对复杂多变的数据,使用文档型模型就直接保留了原有数据的样貌,不需要另外创建新的表新的操作模式来处理,这样不仅存储直接快速,再过后调用时,也可以做到“整存整取”,不需要关系型模型那样再到各种链接的表上取出需要显示的记录。在RDBMS中,需要尽可能的标准化数据。而在NoSQL中,则是可以尽可能的对数据“去标准化”。
4.4 并发性
接着上一个例子,在社交网络当中,用户的操作量很大,许多人每天会花很多的时间泡在社交网络之中。使用传统关系数据模型时,例如,两个用户的发布信息同时链接到了“地点”,那么其中一个人回头修改自己的发布时,因为链接到了“地点”表,系统为了保证一致性就会把“地点”表锁住不让其他用户同时提出修改,这时另外的用户暂时就没办法操作“地点”表了。
如果使用文档型模型,每个人的发布就是独立的一个“文档”,这一个文档文件就包含了这一条发布的所有信息。因为这种“自包含”的特性,不同的用户修改数据只需要修改自己的文档而不会影响别人的操作。这样就实现了高的并发性!
5. 结论
关系型数据模型的复杂查询操作,倚赖的是数据库模式的严格一致,数据的标准化以及数据的合并。在过去的40年中,关系型模型和查询技术已经发展成熟也被众多的开发者所熟悉。
但是,应用、用户和基础的特点的变化使得应用开发者和架构师开始选择“NoSQL”这种非关系型的数据库技术,许多观点认为分布式文档数据库技术在很多方面都要胜过RDBMS:
- 它可以轻松的通过普通机器、虚拟机或者云实例来实现近乎无上限的水平扩展。
- 添加数据是他不需要严格的数据库操作模式,因此在修改数据类型时自然也不需要修改数据库模式。
- 多样化的数据模型能更好的的支持复杂数据的建模、存储和查询。
- 虽然,数据的去结构化可能会使用到更多的空间,但随着存储空间价格的不断下降,存储空间和读写速度的比重势必将越来越像追求速度一方倾斜,而由此带来的高性能、可扩展性以及灵活的数据结构等优点又将大大提升应用的各方面性能表现。
SequoiaDB的数据模型就是以JSON格式存储的文档型模型,所以SequoiaDB具备了文档型和NoSQL数据库的数据灵活性和高可扩展性。SequoiaDB的文档型数据模型不仅简化了数据存取的过程,也大大的提升了数据的灵活性。在应用中不仅免去了设计模式这个麻烦的环节,还能很好的适应大数据时代高并发、实时性和分布式的要求。