《TSM: Temporal Shift Module for Efficient Video Understanding》论文笔记
参考:https://blog.csdn.net/SIGAI_CSDN/article/details/84585363
前言
本文论共两篇,一篇为v1版此处,v2版此处,后者为主要在前者上加上了online版本。
论文采用时间位移模块,即移动相邻帧之间的部分通道信息使相邻帧之间信息交换,可以基本不增加计算量的情况下嵌入到任何2D CNN中。
TSM模块

2.1、Intuition
一个正常的卷积操作,例如kernel为3的1D卷积, w = ( w 1 , w 2 , w 3 ) w=(w_1, w_2, w_3) w=(w1,w2,w3), 输入X为一个无限长的1D矢量,则有 Y = c o n v ( W , X ) , 即 Y i = w 1 X i − 1 + w 2 X i + w 3 X i + 1 Y=conv(W,X),即Y_i=w_1X_{i-1}+w_2X_i+w_3X_{i+1} Y=conv(W,X),即Yi=w1Xi−1+w2Xi+w3Xi+1,可以分解为两步,
1 ) 位 移 : x i − 1 = X i − 1 , x i 0 = X i , x i + 1 = X i + 1 1)位移: x_i^{-1}=X_{i-1}, x_i^{0}=X_{i}, x_i^{+1}=X_{i+1} 1)位移:xi−1=Xi−1,xi0=Xi,xi+1=Xi+1
2 ) 累 加 : Y = w 1 X i − 1 + w 2 X i + w 3 X i + 1 2)累加: Y=w_1X_{i-1}+w_2X_i+w_3X_{i+1} 2)累加:Y=w1Xi−1+w2Xi+w3Xi+1
2.2、Navie Shift Dose Not Work
Navie Shift指的是论文《Shift: A Zero FLOP, Zero Parameter Alternative to Spatial Convolutions》,其在不同的空间方向上移动其输入张量的每个通道
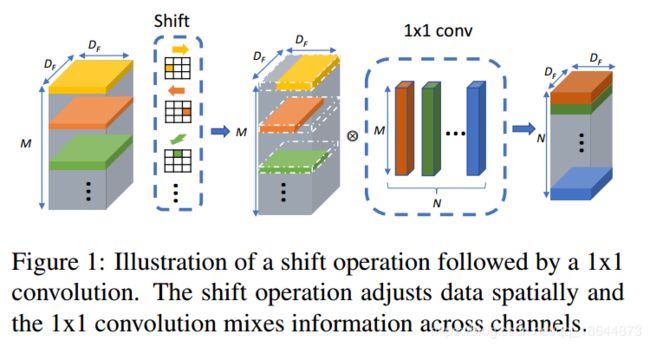
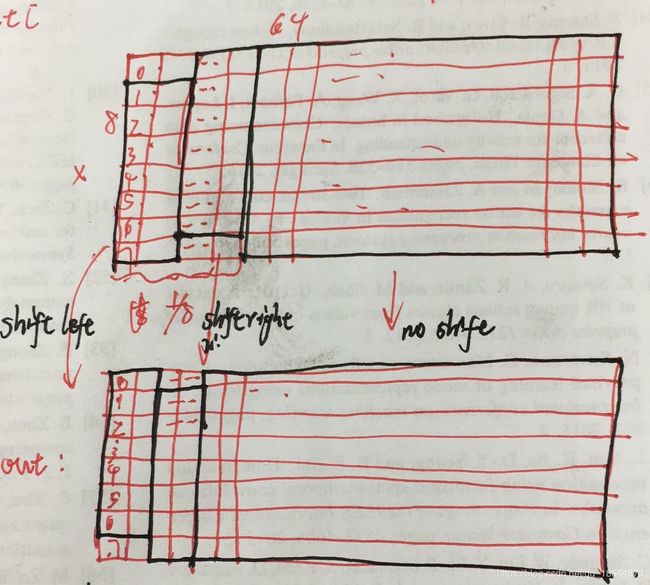
把空间位移策略直接应用到时间维度既不能提高性能也不能提高效率。如果我们移位全部或者大部分通道,会导致两个问题:(1)由于大量数据的移动导致效率更差,数据移动增加推理时间;(2)由于糟糕的空间建模能力导致效能降低,通过将部分通道移动到相邻帧,当前帧不在获得通道信息,损害2DCNN的空间建模能力。相比于TSN,当使用naive shift精度下降2.6%。
2.3、模块设计
(1)减少数据移动:移动部分通道的策略
(2)保持空间特征学习能力:在残差块中shift 1/4(每个方向1/8)的通道
3、TSM Video Network
3.1、Offline Models with Bi-directional TSM
3.2、Online Models with Uni-directional TSM
通过从以前帧转移到当前帧,实现在线识别。
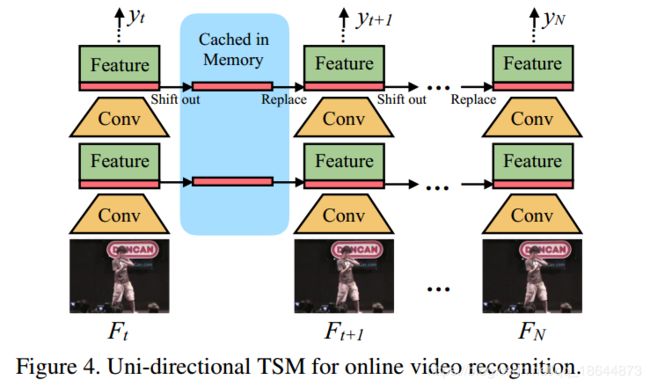 在inference阶段,对于每一帧,保存每个残差块的前1/8的特征图并缓存在寄存器中。对于下一帧,用缓存的特征图替换当前特征图的前1/8。即使用7/8的当前特征图和1/8的旧特征图组合来生成下一层并重复。使用单向TSM进行在线视频识别具有几个独特的优势:
在inference阶段,对于每一帧,保存每个残差块的前1/8的特征图并缓存在寄存器中。对于下一帧,用缓存的特征图替换当前特征图的前1/8。即使用7/8的当前特征图和1/8的旧特征图组合来生成下一层并重复。使用单向TSM进行在线视频识别具有几个独特的优势:
(1)低延迟推断。 对于每个帧,我们只需要替换和缓存1/8的特征,而不需要进行任何额外的计算。 因此,给出全帧预测的延迟几乎与2D CNN基线相同。 像ECO这样的现有方法使用多帧来给出一个预测,这可能在在线预测期间引入大的延迟
(2)内存消耗低。 由于我们只缓存了内存中的一小部分功能,因此内存消耗很低。 对于ResNet-50,我们只需要3.8MB内存缓存来存储中间功能
(3)多级时间融合。 大多数在线方法像TRN或中级时间融合ECO等特征提取后实现晚期时间融合,而我们的TSM能够实现所有级别的时间融合。 通过实验(表2),我们发现多级时间融合对于复杂的时间建模非常重要
4、实验
见论文
code
shift code
def shift(x, n_segment, fold_div=3):
nt, c, h, w = x.size()
n_batch = nt // n_segment
x = x.view(n_batch, n_segment, c, h, w)
out = torch.zeros_like(x)
fold = c // fold_div
out[:, :-1, :fold] = x[:, 1:, :fold] # shift left
out[:, 1:, fold: 2 * fold] = x[:, :-1, fold: 2 * fold] # shift right
out[:, :, 2 * fold:] = x[:, :, 2 * fold:] # not shift
return out.view(nt, c, h, w)
import torchvision
if isinstance(net, torchvision.models.ResNet):
if place == 'block':
def make_block_temporal(stage, this_segment):
blocks = list(stage.children())
print('=> Processing stage with {} blocks'.format(len(blocks)))
for i, b in enumerate(blocks):
blocks[i] = TemporalShift(b, n_segment=this_segment, n_div=n_div)
return nn.Sequential(*(blocks))
net.layer1 = make_block_temporal(net.layer1, n_segment_list[0])
net.layer2 = make_block_temporal(net.layer2, n_segment_list[1])
net.layer3 = make_block_temporal(net.layer3, n_segment_list[2])
net.layer4 = make_block_temporal(net.layer4, n_segment_list[3])
elif 'blockres' in place:
n_round = 1
if len(list(net.layer3.children())) >= 23:
print('=> Using n_round {} to insert temporal shift'.format(n_round))
def make_block_temporal(stage, this_segment):
blocks = list(stage.children())
print('=> Processing stage with {} blocks residual'.format(len(blocks)))
for i, b in enumerate(blocks):
if i % n_round == 0:
blocks[i].conv1 = TemporalShift(b.conv1, n_segment=this_segment, n_div=n_div)
return nn.Sequential(*blocks)
net.layer1 = make_block_temporal(net.layer1, n_segment_list[0])
net.layer2 = make_block_temporal(net.layer2, n_segment_list[1])
net.layer3 = make_block_temporal(net.layer3, n_segment_list[2])
net.layer4 = make_block_temporal(net.layer4, n_segment_list[3])