字符串匹配2:多模式匹配(Trie树 AC自动机)
前言
紧接着上一篇文章字符串匹配1,在上一篇文章里,我们主要总结归纳的是一个字符串和另一个字符串相比较。这篇文章,总结归纳的是两种常见的多模式匹配算法Trie树和AC自动机。
多模式匹配:一个主串和多个模式串之间的匹配问题。
当然,聪明的你一定会问难道之前所学的单模式匹配的算法就不能解决问题吗? 答案是当然可以,但是用单模式的字符串算法解决这类问题总体的时间开销就会大很多,对于这类问题 我们更多的是采用以下的方法来进行解决。
话不多说,开始我们这篇文章的正文~
Trie树
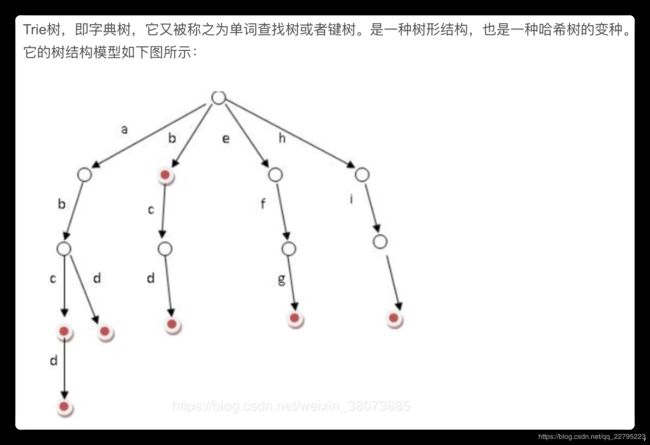
1. 基本性质

2. 代码实现
Trie树结构的实现代码同时也是leetcode上的208题
具体见代码,很好理解。
class Trie:
def __init__(self):
"""
Initialize your data structure here.
"""
self.lookup = {}
def insert(self, word):
"""
Inserts a word into the trie.
"""
tree = self.lookup
for a in word:
if a not in tree:
tree[a] = {}
tree = tree[a]
# 单词结束标志
tree["#"] = "#"
def search(self, word):
"""
Returns if the word is in the trie.
"""
tree = self.lookup
for a in word:
if a not in tree:
return False
tree = tree[a]
if "#" in tree:
return True
return False
def startsWith(self, prefix):
"""
Returns if there is any word in the trie that starts with the given prefix.
"""
tree = self.lookup
for a in prefix:
if a not in tree:
return False
tree = tree[a]
return True
3. 优点
利用字符串的公共前缀来减少查询时间,最大限度的减少无谓的字符串比较,查询效率比哈希树高。
实际上,字符串的匹配问题,笼统上讲其实就是数据的查找的问题。对于支持动态数据高效操作的数据结构,还有散列表,红黑树,跳表等等。在实际应用中,针对一组模式串在主串中的查找问题,我们更加倾向于使用散列表或者红黑树来进行解决,因为这两种数据结构成熟的编程语言都已经实现为成熟的类库,我们直接拿来运用就行了。
Trie树并不适合精确匹配查找,他更加倾向于前缀匹配的字符串。
4. 性能分析
构建Trie树的过程,需要扫描所有的字符串,时间复杂度是O(n)(n表示所有字符串的长度和)。在构建成功之后,后续的查询操作会非常高效。每次查询时,如果查询的字符串长度是k,那我们只需要比对k个节点后,就嫩那个完成查询操作。所以在构建好Trie树之后,在其中查找字符串的时间复杂度是O(k),k表示要查找的字符串的长度。
所以我们可以说Trie树是一种典型的空间换时间的思路。
AC自动机
AC自动机:Aho-Corasick automation,是著名的多模匹配算法之一。
一个常见的例子就是给出n个单词,再给出一段包含m个字符的文章,让你找出有多少个单词在文章里出现过。
要搞懂AC自动机,先得有模式树(字典树)Trie和KMP模式匹配算法的基础知识,前面的文章已经对这两种算法进行了总结归纳,读者可以查看之前的知识点。
AC自动机实际上就是在Trie树之上进行优化,加了类似KMP算法的next数组,只不过此处的next数组是构建在树结构上。
1. AC自动机的节点构造(大概知道有什么东西即可)
AC自动机实现时树结构中每个节点的类型表示如下:
class AcNode{
public char data;
public AcNode[] children=new AcNode[26]; //这里只考虑原始字符集中只包括a-z26个小写字母
public boolean isEndingChar=false; //结尾字符位true
public int length=-1; //当isEndingChar位true时,记录模式串的长度
public AcNode fail; //失败指针 功能类似于kmp算法的next数组
AcNode(){}
public AcNode(char data){
this.data=data;
}
}
2. Fail指针
在KMP算法中,当我们比较到一个字符发现失配的时候我们会通过next数组,找到下一个开始匹配的位置,然后进行字符串匹配,当然KMP算法适用于单模式匹配,所谓单模式匹配,就是给出一个模式串,给出一个文本串,然后看模式串在文本串中是否存在。
在AC自动机中,我们也有类似next数组的东西就是fail指针,当发现失配的字符失配的时候,跳转到fail指针指向的位置,然后再次进行匹配操作,AC自动机之所以能实现多模式匹配,就归功于Fail指针的建立。
当前节点t有fail指针,其fail指针所指向的节点和t所代表的字符是相同的。
因为t匹配成功后,我们需要去匹配t->child,发现失配,那么就从t->fail这个节点开始再次去进行匹配。
Fail指针的求法
当然,我们要先根据模式串构建字典树,然后再把Fail指针构建完成,这里描述Fail指针的构建。
Fail指针用BFS来求得,
对于直接与根节点相连的节点来说,如果这些节点失配,他们的Fail指针直接指向root即可,
其他节点其Fail指针求法如下:
假设当前节点为father,其孩子节点记为child。求child的Fail指针时,首先我们要找到其father的Fail指针所指向的节点,假如是t的话,我们就要看t的孩子中有没有和child节点所表示的字母相同的节点,如果有的话,这个节点就是child的fail指针,如果发现没有,则需要找father->fail->fail这个节点,然后重复上面过程,如果一直找都找不到,则child的Fail指针就要指向root。
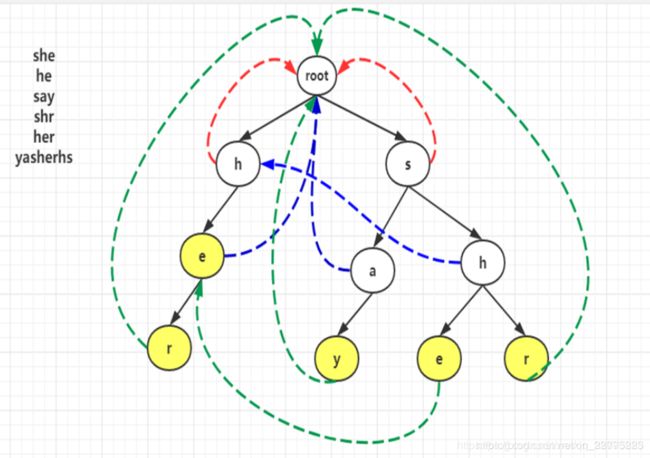
具体过程为:
如图所示,首先root最初会进队,然后root出队,我们把root的孩子的失败指针都指向root。因此图中h,s的失败指针都指向root,如红色线条所示,同时h,s进队。
接下来该h出队,我们就找h的孩子的fail指针,首先我们发现h这个节点其fail指针指向root,而root又没有字符为e的孩子,则e的fail指针是空的,如果为空,则也要指向root,如图中蓝色线所示。并且e进队,此时s要出队,我们再找s的孩子a,h的fail指针,
我们发现s的fail指针指向root,而root没有字符为a的孩子,故a的fail指针指向root,a入队,然后找h的fail指针,同样的先看s的fail指针是root,发现root又字符为h的孩子,所以h的fail指针就指向了第二层的h节点。e,a , h 的fail指针的指向如图蓝色线所示。
此时队列中有e,a,h,e先出队,找e的孩子r的失败指针,我们先看e的失败指针,发现找到了root,root没有字符为r的孩子,则r的失败指针指向了root,并且r进队,然后a出队,我们也是先看a的失败指针,发现是root,则y的fail指针就会指向root.并且y进队。然后h出队,考虑h的孩子e,则我们看h的失败指针,指向第二层的h节点,看这个节点发现有字符值为e的节点,最后一行的节点e的失败指针就指向第三层的e。最后找r的指针,同样看第二层的h节点,其孩子节点不含有字符r,则会继续往前找h的失败指针找到了根,根下面的孩子节点也不存在有字符r,则最后r就指向根节点,最后一行节点的fail指针如绿色虚线所示。
3. 总结
AC自动机算法分为3步:构造一棵Trie树,构造失配指针 和 模式匹配过程。
如果你对KMP算法和了解的话,应该知道KMP算法中的next函数(shift函数或者fail函数)是干什么用的。KMP中我们用两个指针i和j分别表示,A[i-j+ 1…i]与B[1…j]完全相等。也就是说,i是不断增加的,随着i的增加j相应地变化,且j满足以A[i]结尾的长度为j的字符串正好匹配B串的前 j个字符,当A[i+1]≠B[j+1],KMP的策略是调整j的位置(减小j值)使得A[i-j+1…i]与B[1…j]保持匹配且新的B[j+1]恰好与A[i+1]匹配,而next函数恰恰记录了这个j应该调整到的位置。
同样AC自动机的失败指针具有同样的功能,也就是说当我们的模式串在Tire上进行匹配时,如果与当前节点的关键字不能继续匹配的时候,就应该去当前节点的失败指针所指向的节点继续进行匹配。