selenium反爬问题(1)
网址:https://www.nst.com.my/actionline
python3 + selenium + mitmdump
页面分析:

直有两个文件:(原谅我一直在外部的js中找了好久)
后来发现反爬的js代码在html中!!!!(而且显而易见)
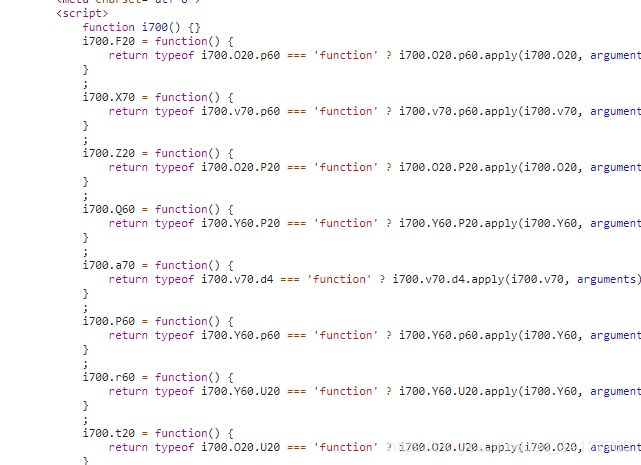
这是什么鬼!!!感觉像cpu型号诶,正常人谁会看这个!!!
这种情况最好的办法是设置断点,便可以查看变量原有的值,(特别注意:关照if 语句, webdriver , test等关键字)
这里面搜索test关键字(我觉得这是反爬大哥给我留的一条活路!!!)可以找到结果
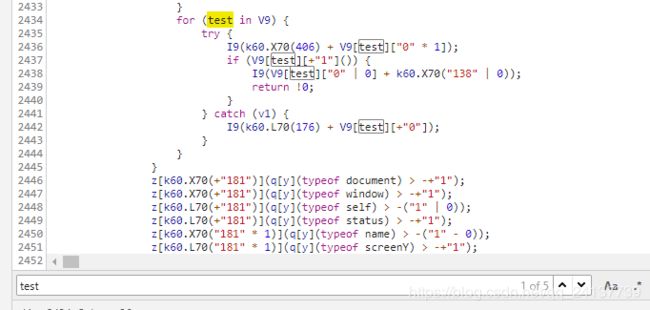
设置个断点,在console上看一下:

一看这么多策略:太厉害了。
接下来看webdirver
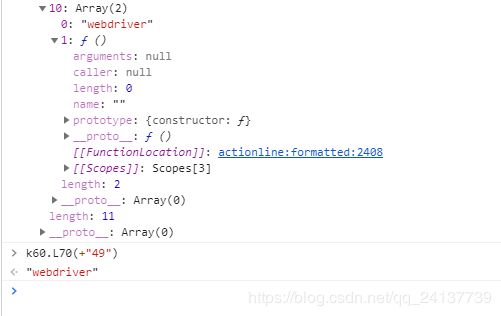
点击那个函数会跳转到函数的定义地方:

研究一下参数:

这个k60.....这个就是webdriver。。。省略一万步错误尝试!!!
然后使用 mitmdump 进行拦截
from mitmproxy import ctx
def response(flow):
if '/www.nst.com.my/actionline' not in flow.request.url :
return
# for webdriver_key in ['webdriver', '__driver_evaluate', '__webdriver_evaluate', '__selenium_evaluate',
# '__fxdriver_evaluate', '__driver_unwrapped', '__webdriver_unwrapped', '__selenium_unwrapped',
# '__fxdriver_unwrapped', '_Selenium_IDE_Recorder', '_selenium', 'calledSelenium',
# '_WEBDRIVER_ELEM_CACHE', 'ChromeDriverw', 'driver-evaluate', 'webdriver-evaluate',
# 'selenium-evaluate', 'webdriverCommand', 'webdriver-evaluate-response', '__webdriverFunc',
# '__webdriver_script_fn', '__$webdriverAsyncExecutor', '__lastWatirAlert',
# '__lastWatirConfirm', '__lastWatirPrompt', '$chrome_asyncScriptInfo',
# '$cdc_asdjflasutopfhvcZLmcfl_']:
# ctx.log.info('Remove "{}" from {}.'.format(webdriver_key, flow.request.url))
# flow.respons e.text = flow.response.text.replace('"{}"'.format(webdriver_key), '"NO-SUCH-ATTR"')
flow.response.text = flow.response.text.replace('k60.L70(+"49")','false')
flow.response.text = flow.response.text.replace('k60.L70(+"232")', 'user-agent')
请求页面代码:
import requests
from selenium import webdriver
from lxml import etree
import time
class DiffSpider:
def __init__(self):
self.baseurl = 'https://www.nst.com.my/actionline'
# self.baseurl = 'https://v.youku.com/v_show/id_XNDE4MzQzOTA2NA==.html'
self.options = webdriver.ChromeOptions()
# self.options.add_argument('--headless')
# self.options.add_experimental_option('excludeSwitches', ['enable-automation'])
self.driver = webdriver.Chrome(options=self.options)
self.driver.maximize_window()
self.headers ={'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
'Accept-Language':'zh-CN,zh;q=0.9',
}
def gethtml(self):
self.driver.get(self.baseurl)
# self.driver.get(self.baseurl)
time.sleep(2)
chrome_html = self.driver.page_source
print(chrome_html)
self.writeto(chrome_html)
def writeto(self, chrome_html):
with open('chrome_sourse.html','w', encoding='utf-8')as f:
f.write(chrome_html)
if __name__ == '__main__':
spider = DiffSpider()
spider.gethtml()
from mitmproxy import ctx
def response(flow):
if '/www.nst.com.my/actionline' not in flow.request.url :
return
# for webdriver_key in ['webdriver', '__driver_evaluate', '__webdriver_evaluate', '__selenium_evaluate',
# '__fxdriver_evaluate', '__driver_unwrapped', '__webdriver_unwrapped', '__selenium_unwrapped',
# '__fxdriver_unwrapped', '_Selenium_IDE_Recorder', '_selenium', 'calledSelenium',
# '_WEBDRIVER_ELEM_CACHE', 'ChromeDriverw', 'driver-evaluate', 'webdriver-evaluate',
# 'selenium-evaluate', 'webdriverCommand', 'webdriver-evaluate-response', '__webdriverFunc',
# '__webdriver_script_fn', '__$webdriverAsyncExecutor', '__lastWatirAlert',
# '__lastWatirConfirm', '__lastWatirPrompt', '$chrome_asyncScriptInfo',
# '$cdc_asdjflasutopfhvcZLmcfl_']:
# ctx.log.info('Remove "{}" from {}.'.format(webdriver_key, flow.request.url))
# flow.response.text = flow.response.text.replace('"{}"'.format(webdriver_key), '"NO-SUCH-ATTR"')
flow.response.text = flow.response.text.replace('k60.L70(+"49")','false')
flow.response.text = flow.response.text.replace('k60.L70(+"232")', 'user-agent')
flow.response.text = flow.response.text.replace('k60.X70(+"489")', '{ "runtime": {}}')
flow.response.text = flow.response.text.replace('k60.X70("235" | 0)', '["zh-CN", "zh"]')
flow.response.text = flow.response.text.replace('k60.L70(28)', 'false')
flow.response.text = flow.response.text.replace('k60.L70("462" - 0)', 'Google Inc')
flow.response.text = flow.response.text.replace('U1[k60.L70("303" | 0)]', '100')
flow.response.text = flow.response.text.replace('U1[k60.X70("7" * 1)]', '40')
#
还有很多反爬措施,还在学习中!!!!
转发请注明原文地址:谢谢!!!