面试题整理stl库 zerocopy 与memery map相关知识整理
vector :底层数据结构为数组 ,支持快速随机访问,访问O(1),增加删除
优点:
(1) 不指定一块内存大小的数组的连续存储,即可以像数组一样操作,但可以对此数组进行动态操作。通常体现在push_back() pop_back()
(2) 随机访问方便,即支持[ ]操作符和vector.at()
(3) 节省空间。
缺点:
(1) 在内部进行插入删除操作效率低。
(2) 只能在vector的最后进行push和pop,不能在vector的头进行push和pop。
(3) 当动态添加的数据超过vector默认分配的大小时要进行整体的重新分配、拷贝与释放
list 双向链表
每一个结点都包括一个信息快Info、一个前驱指针Pre、一个后驱指针Post。可以不分配必须的内存大小方便的进行添加和删除操作。使用的是非连续的内存空间进行存储。
优点:(1) 不使用连续内存完成动态操作。
(2) 在内部方便的进行插入和删除操作
(3) 可在两端进行push、pop
缺点:(1) 不能进行内部的随机访问,即不支持[ ]操作符和vector.at()
(2) 相对于verctor占用内存多
3 deque
双端队列 double-end queue
deque是在功能上合并了vector和list。
优点:(1) 随机访问方便,即支持[ ]操作符和vector.at()
(2) 在内部方便的进行插入和删除操作
(3) 可在两端进行push、pop
缺点:(1) 占用内存多(2)中间删除时耗时长
deque实现:
deque采用一块所谓的map(注意,不是STL的map容器)作为主控。这里所谓map是一小块连续空间,其中每个元素(此处称为一个节点,node)都是指针,指向另一段(较大的)连续线性空间,称为缓冲区。缓冲区才是deque的储存空间主体。SGI STL 允许我们指定缓冲区大小,默认值0表示将使用512 bytes 缓冲区。
deque迭代器 首先,它必须能够指出分段连续空间(亦即缓冲区)在哪里,其次它必须能够判断自己是否已经处于其所在缓冲区的边缘,如果是,一旦前进或后退就必须跳跃至下一个或上一个缓冲区。为了能够正确跳跃,deque必须随时掌握管控中心(map)。所以在迭代器中需要定义:当前元素的指针,当前元素所在缓冲区的起始指针,当前元素所在缓冲区的尾指针,指向map中指向所在缓区地址的指针,分别为cur, first, last, node。
1 如果你需要高效的随即存取,而不在乎插入和删除的效率,使用vector
2 如果你需要大量的插入和删除,而不关心随即存取,则应使用list
3 如果你需要随即存取,而且关心两端数据的插入和删除,则应使用deque
map, set, multimap, and multiset底层是红黑树实现:
插入:O(logN)
访问:O(logN)
删除:O(logN)
hash_map, hash_set, hash_multimap, and hash_multiset
底层为hashmap实现:
插入:O(1),最坏O(N)
访问:O(1),最坏O(N)
删除:O(1),最坏O(N)
关于Zerocopy (https://www.jianshu.com/p/8c6b056f73ce)
传统的IO读写有两种方式:IO终端和DMA
IO终端:

整个流程如下:
1.用户进程调用read等系统调用向操作系统发出IO请求,请求读取数据到自己的内存缓冲区中。自己进入阻塞状态。
2.操作系统收到请求后,进一步将IO请求发送磁盘。
3.磁盘驱动器收到内核的IO请求,把数据从磁盘读取到驱动器的缓冲中。此时不占用CPU。当驱动器的缓冲区被读满后,向内核发起中断信号告知自己缓冲区已满。
4.内核收到中断,使用CPU时间将磁盘驱动器的缓存中的数据拷贝到内核缓冲区中。
5.如果内核缓冲区的数据少于用户申请的读的数据,重复步骤3跟步骤4,直到内核缓冲区的数据足够多为止。
6.将数据从内核缓冲区拷贝到用户缓冲区,同时从系统调用中返回。完成任务。
缺点:用户的每次IO请求,都需要CPU多次参与。
DMA(直接存储器访问)原理

1.用户进程调用read等系统调用向操作系统发出IO请求,请求读取数据到自己的内存缓冲区中。自己进入阻塞状态。
2.操作系统收到请求后,进一步将IO请求发送DMA。然后让CPU干别的活去。
3.DMA进一步将IO请求发送给磁盘。
4.磁盘驱动器收到DMA的IO请求,把数据从磁盘读取到驱动器的缓冲中。当驱动器的缓冲区被读满后,向DMA发起中断信号告知自己缓冲区已满。
4.DMA收到磁盘驱动器的信号,将磁盘驱动器的缓存中的数据拷贝到内核缓冲区中。此时不占用CPU。这个时候只要内核缓冲区的数据少于用户申请的读的数据,内核就会一直重复步骤3跟步骤4,直到内核缓冲区的数据足够多为止。
5.当DMA读取了足够多的数据,就会发送中断信号给CPU。
6.CPU手动DMA的信号,知道数据已经准备好,于是将数据从内核拷贝到用户空间,系统调用返回。
简单地说明就是将原来CPU的工作在数据传输过程中交给了DMA控制器
跟IO中断模式相比,DMA模式下,DMA就是CPU的一个代理,它负责了一部分的拷贝工作,从而减轻了CPU的负担。
DMA的优点就是:中断少,CPU负担低。
zero copy
零拷贝(Zero-copy)是一种高效的数据传输机制,在追求低延迟的传输场景中十分常用。
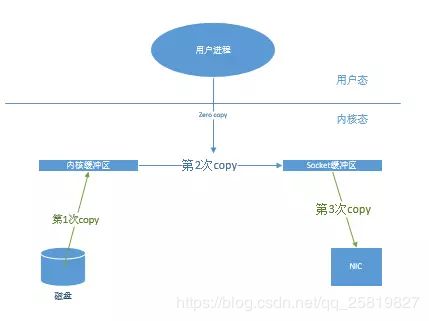
在网络传输过程中用传统的IO读写发生4次拷贝和用户态与内核态转换:
1,首先,调用read时,文件A拷贝到了kernel模式;
2,之后,CPU控制将kernel模式数据copy到user模式下;
3,调用write时,先将user模式下的内容copy到kernel模式下的socket的buffer中;
4,最后将kernel模式下的socket buffer的数据copy到网卡设备中传送;


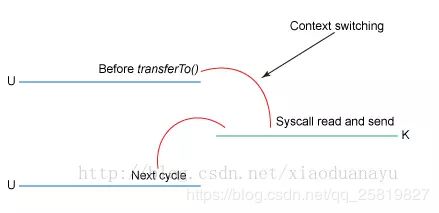
zero copy作用是减少了用户态与内核态的转换:
zero copy技术就是减少不必要的内核缓冲区跟用户缓冲区间的拷贝,从而减少CPU的开销和内核态切换开销,达到性能的提升。
zero copy下,同样的读取文件然后通过网络发送出去,只需要拷贝三次,只发生两次内核态和用户态的切换。
linux下的zero copy技术
linux下的用来实现zero copy的常见接口由如下几个:
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count)
long splice(int fdin, int fdout, size_t len, unsigned int flags);
这两个接口都可以用来在两个文件描述符之间传输数据,实现所谓的zero copy。
splice接口则要求两个文件描述符中至少要有一个是pipe。
mmap(内存映射)(https://www.cnblogs.com/linhaostudy/p/10632082.html):
Linux的虚拟内存管理是基于mmap来实现的。vm_area_struct是在mmap的时候创建的,vm_area_strcut代表了一段连续的虚拟地址,这些虚拟地址相应地映射到一个后备文件或者一个匿名文件的虚拟页。一个vm_area_struct映射到一组连续的页表项。页表项又指向物理内存page,这样就把一个文件和物理内存页相映射。
来理解一下虚拟地址映射的过程:拿到一个虚拟地址,根据已有的vm_area_struct看这个虚拟地址是否属于某个vm_area_struct
如果没有匹配到,就报段错误,访问了一个没有分配的虚拟地址。
如果匹配到了vm_area_struct,根据虚拟地址和页表的映射关系,找到对应的页表项PTE,如果PTE没有分配,就报一个缺页异常,去加载相应的文件数据到物理内存,如果PTE分配,就去相应的物理页的偏移位置读取数据
所以虚拟页的三种状态的实际含义如下:
未分配虚拟页,指的是没有使用mmap建立vm_area_struct,所以也就没有对应到具体的页表项
已分配虚拟页,未映射到物理页,指的是已经使用了mmap建立的vm_area_struct,可以映射到对应的页表项,但是页表项没有指向具体的物理页
已分配虚拟页,已映射到物理页,指的是已经使用了mmap建立的vm_area_struct,可以映射到对应的页表项,并且页表项指向具体的物理页
mmap要么映射到一个后备文件,要么映射到一个匿名文件。操作系统分配物理内存时实际用到了匿名文件的mmap。
mmap分为有后备文件的映射和匿名文件的映射,这两种映射又有私有映射和共享映射之分,所以mmap可以创建4种类型的映射
1.后备文件的共享映射,多个进程的vm_area_struct指向同一个物理内存区域,一个进程对文件内容的修改,会被其他进程可见。对文件内容的修改会被写回到后备文件。
2.后备文件的私有映射,多个进程的vm_area_struct指向同一个物理内存区域,采用写时拷贝的方式,当一个进程对文件内容做修改,不会被其他进程看到。另外对文件内的修改也不会被写回到后备文件。当内存不够需要进行页回收时,私有映射的页被交换到交换区。一般用在加载共享代码库
3.匿名文件的共享映射,内核创建一个初始都是0的物理内存区域,然后多个进程的vm_area_struct指向这个共享的物理内存区域,对该区域内容的修改对所有进程可见。匿名文件在页回收时被交换到交换区
4.匿名文件的私有映射,内核创建一个初始都是0的物理内存区域,对该区域内容的修改只对创建者进程可见。匿名文件在页回收时被交换到交换区。malloc()底层是用了匿名文件的私有映射来分配大块内存。
内存映射的用途很多,比如
1.后备文件的共享映射可以用作内存映射IO来对大文件进行操作,比普通IO减少一次复制。需要注意的是内存映射IO涉及到内核的很多操作,比如vm_area_struct的创建,页表的修改等等,比普通IO的操作更复杂。小文件的读写使用普通IO更合适
2.后备文件的私有映射可以用作共享库二进制文件代码段,数据段的加载
3.匿名文件的共享映射可以用作fork时让父子进程共享匿名映射分配的内存
4.匿名文件的私有映射可以用作进程的私有内存分配
看了这部分,看来linux 内核知识要准备找个时间好好学一下