基于helm快速部署k8s日志采集分析系统EFK(Elasticsearch+FileBeat+Kibana)
前言
首先,什么是日志? 日志就是程序产生的,遵循一定格式(通常包含时间戳)的文本数据
系统运维人员以及相关技术人员通过日志对系统应用进行监控运维管理,甚至基于日志进行一些数据分析工作,保障系统应用运行的稳定性,且帮助开发着快速定位错误.
当项目迁移到k8s进行部署管理之后,虽然在弹性伸缩以及服务器资源的利用率方面得到了优化,但是k8s在日志管理方面并没有提供相关的支持,由于应用服务会动态调节,即部署到不同的服务器上面,因此应用日志的管理单纯依赖挂载日志文件已经不能很好的解决应用日志管理的问题,迫切需要一个日志采集系统对k8s上面的应用日志进行统一采集管理,才能保证应用运行稳定性.
EFK介绍
经过一番了解,目前比较流行的k8s日志采集系统模式分别是ELK(ElasticSearch+Logstash 和+Kibana)以及EFK(Elasticsearch+FileBeat+Kibana)
Logstash:数据收集处理引擎。支持动态的从各种数据源搜集数据,并对数据进行过滤、分析、丰富、统一格式等操作,然后存储以供后续使用。
Kibana:可视化化平台。它能够搜索、展示存储在 Elasticsearch 中索引数据。使用它可以很方便的用图表、表格、地图展示和分析数据。
Elasticsearch :分布式搜索引擎。具有高可伸缩、高可靠、易管理等特点。可以用于全文检索、结构化检索和分析,并能将这三者结合起来。Elasticsearch 基于 Lucene 开发,现在使用最广的开源搜索引擎之一,Wikipedia 、StackOverflow、Github 等都基于它来构建自己的搜索引擎。
Filebeat:轻量级数据收集引擎。基于原先 Logstash-fowarder 的源码改造出来。换句话说:Filebeat就是新版的 Logstash-fowarder,也会是 ELK Stack 在 shipper 端的第一选择。
EFK实际上EFK是大名鼎鼎的日志系统ELK的一个变种,是一个轻量级的日志采集分析系统,基于资源的考虑的我们会选择EFK.
EFK优势
搭建EFK日志分析系统的目的就是将
日志聚合起来,达到快速查看快速分析的目的,使用EFK不仅可以快速的聚合出每天的日志,还能将不同项目的日志聚合起来,对于微服务和分布式架构来说,查询日志尤为方便,而且因为日志保存在Elasticsearch中,所以查询速度非常之快.
搭建架构说明
由于我们应用都是基于docker部署到k8s上面的,k8s的工作节点上面所部署的docker容器也就是pod,产生的容器日志文件会存放在节点的系统的目录/var/lib/docker/containers/*/*.log 我将FileBeat以DaemonSet的方式部署到k8s的每个节点上面,采集节点本地的所有容器日志,存储在Elasticsearch,由于Elasticsearch也是部署到k8s上面,会动态调节服务器,因此需要对数据持久化进行分布式管理,Elasticsearch的持久化基于nfs进行共享,每台k8s节点作为nfs客户端,与nfs服务端交互,通过Kibana可视化管理日志.
nfs共享原理:https://blog.csdn.net/qq_38265137/article/details/83146421
具体搭建架构图如下:

环境准备
服务器说明
| 服务器IP | 描述 | 系统 |
|---|---|---|
| 192.168.1.100 | k8s master节点 | Ubuntu 16.04 |
| 192.168.1.101 | k8s 工作节点1,nfs 客户端 | Ubuntu 16.04 |
| 192.168.1.102 | k8s 工作节点2,nfs 客户端 | Ubuntu 16.04 |
| 192.168.1.103 | nfs 服务端 | CentOS7 |
基础环境说明
| 基础环境 | 版本 |
|---|---|
| K8S | 1.16.0 |
| hlem | 3.0.1 |
EFK搭建说明
| 应用 | 版本 |
|---|---|
| Elasticsearch | 7.7.0 |
| FileBeat | 7.7.0 |
| Kibana | 7.7.0 |
搭建NFS
NFS Server
在nfs服务端所在服务器进行如下操作:
1.下载nfs
yum -y install nfs-utils
2.创建nfs数据存储目录并赋予权限
mkdir -p nfs/data/
chmod -R 777 /home/nfs/data/
3.设置挂载目录权限
vim /etc/exports
输入以下内容:
/home/nfs/data *(rw,no_root_squash,sync)
4.进行保存并启动服务
exportfs -r
systemctl restart rpcbind && systemctl enable rpcbind
systemctl restart nfs && systemctl enable nfs
5.查看是否成功挂载数据目录
showmount -e 192.168.1.103
控制台可以看到挂载目录
Export list for 192.168.1.103:
/home/nfs/data *
NFS Client
我们将利用nfs-client-provisioner搭建nfs-client
nfs-client-provisioner 是一个Kubernetes的简易NFS的外部provisioner,本身不提供NFS,需要现有的NFS服务器提供存储
PV以 n a m e s p a c e − {namespace}- namespace−{pvcName}- p v N a m e 的 命 名 格 式 提 供 ( 在 N F S 服 务 器 上 ) P V 回 收 的 时 候 以 a r c h i e v e d − {pvName}的命名格式提供(在NFS服务器上) PV回收的时候以 archieved- pvName的命名格式提供(在NFS服务器上)PV回收的时候以archieved−{namespace}- p v c N a m e − {pvcName}- pvcName−{pvName} 的命名格式(在NFS服务器上)
部署只需要在master节点执行以下命令
helm install nfs-client --set nfs.server=192.168.1.103,nfs.path=/home/nfs/data azure/nfs-client-provisioner --namespace logs
nfs.server: nfs服务端IP
nfs.path: nfs挂载数据目录
namespace: k8s命名空间
效果
打开k8s面板,点击storage Classes可以看到新建的nfs-client,也可以输入命令 kubectl get sc

搭建Elasticsearch
下载charts文件
在master节点输入以下命令:
helm repo add azure http://mirror.azure.cn/kubernetes/charts/
helm repo update
helm pull elastic/elasticsearch
tar -zvf elasticsearch
修改配置
根据实际情况修改配置vi elasticsearch/values.yml
1.修改最小master节点数量(单机需要)
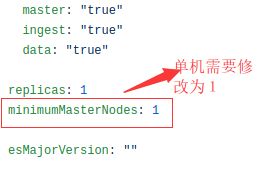
2.设置Storage Class

完整配置代码:https://github.com/llzz9595/k8s/blob/master/log/elasticsearch/values.yaml
部署
进入master节点,elasticsearch父目录输入以下命令:
helm install elasticsearch elasticsearch --namespace logs
在k8s监控面板可以看到elasticsearch部署情况以及挂载情况,也可以通过kubectl get pv,pvc -n logs命令查看
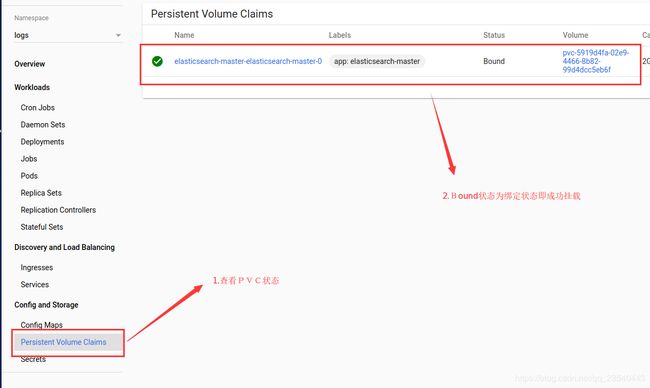
搭建FileBeat
下载charts文件
helm pull elastic/filebeat
tar -zvf filebeat
修改配置
根据实际情况修改配置vi filebeat/values.yml
修改采集配置,java的异常堆栈进行合并行处理
由于我们应用大部分是java应用,因此我们需要把java的异常堆栈进行合并行处理
具体配置如下:
filebeatConfig:
filebeat.yml: |
filebeat.config:
modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: true
filebeat.autodiscover:
providers:
- type: kubernetes
hints.enabled: true
templates:
- condition:
equals:
# java堆栈对行日志出现的名称空间为baas
kubernetes.namespace: baas
config:
- type: docker
containers.ids:
- "${data.kubernetes.container.id}"
# 配置java堆栈多行匹配规则
multiline:
pattern: '^[[:space:]]+(at|\.{3})\b|^Caused by:'
negate: false
match: after
- condition:
equals:
kubernetes.namespace: kube-system
config:
- type: docker
containers.ids:
- "${data.kubernetes.container.id}"
output.elasticsearch:
host: '${NODE_NAME}'
hosts: '${ELASTICSEARCH_HOSTS:elasticsearch-master:9200}'
完整配置代码:https://github.com/llzz9595/k8s/blob/master/log/filebeat/values.yaml
部署
进入master节点,filebeat父目录输入以下命令:
helm install filebeat filebeat --namespace logs
搭建Kibana
下载charts文件
helm pull elastic/kibana
tar -zvf kibana
修改配置
根据实际情况修改配置vi kibana/values.yml
1.配置ingress,没有ingress可以不配置,可以通过NodePort开放访问
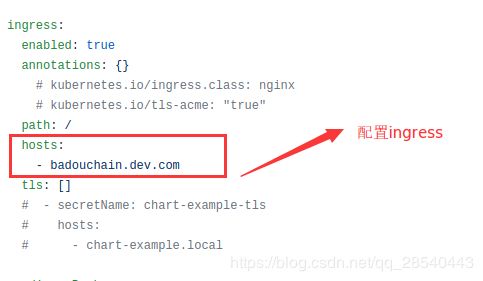
2.配置中文显示
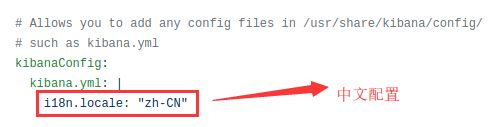
完整配置:https://github.com/llzz9595/k8s/blob/master/log/kibana/values.yaml
部署
进入master节点,kibana父目录输入以下命令:
helm install kibana kibana --namespace logs
配置索引
访问ingress里面的配置路径或者kibana服务nodeIP:Port
搜索filebeat,添加索引
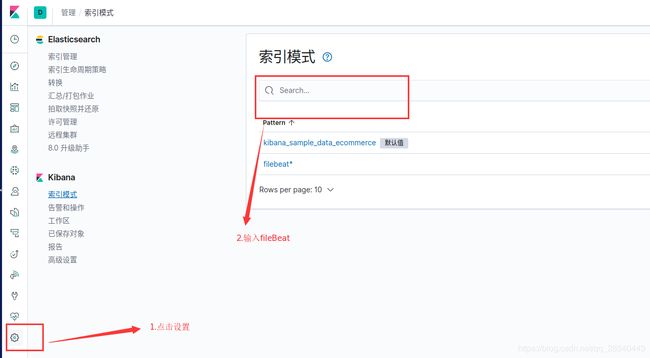
查看日志
配置完成后,可以在日志管理看到采集到所有日志
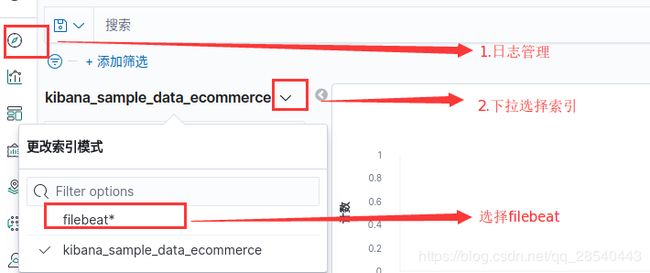
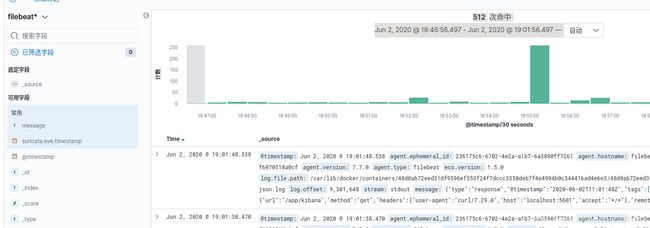
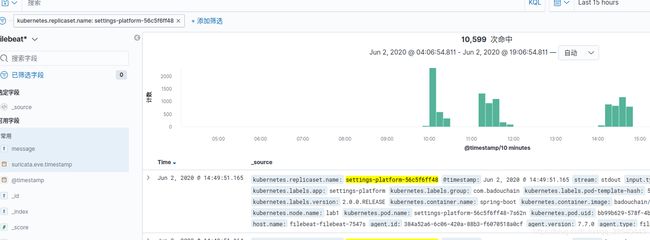
筛选k8s日志
由于在上面filebeat的采集配置中我们配置k8s相关的信息,因此在保存日志的时候会自定采集应用的k8s信息,包括namespace,pod-name,pod-id等.
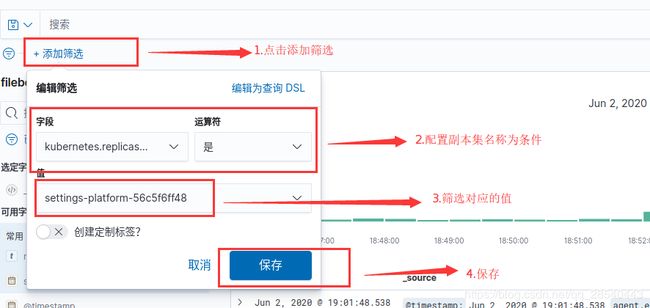
筛选结果:
总结
上面的流程实现了k8s日志采集分析系统EFK的快速搭建,相关的代码在https://github.com/llzz9595/k8s可以直接下载部署即可.
通过EFK实现k8s的日志采集分析,保证了系统的稳定,但是由于Kibana默认不支持用户权限控制的,也就是登录认证之类的,因此对于生产来说还是不太安全,一般可以通过nginx配置密码文件的方式实Kibana登录认证.