scrapy-redis案例(三)爬取中国红娘相亲网站
前言:本案例将分为三篇。
第一篇,使用scrapy框架来实现爬取中国红娘相亲网站。
第二篇,使用scrapy-redis 简单的方式爬取中国红娘相亲网站。(使用redis存储数据,请求具有持续性,但不具备分布式)
第三篇,使用scrapy-redis 分布式的方法爬取中国红娘相亲网站,并使用mysql将数据持久化。
(1)修改第二篇的代码为scrapy-redis 分布式的代码
废话不多说,从settings.py文件配置来说,没有什么变化。主要改写spider 即可。
【1】导入RedisCrawlSpider类,不使用CrawlSpider
from scrapy_redis.spiders import RedisCrawlSpider【2】修改继承的类为 RedisCrawlSpider
class HongniangspiderSpider(RedisCrawlSpider):【3】修改爬虫爬取的域(allowed_domains)和开始的url(start_urls)
# allowed_domains = ['hongniang.com']
# start_urls = ['http://www.hongniang.com/index/search?sort=0&wh=0&sex=2&starage=0&province=0&city=0&marriage=0&edu=0&income=0&height=0&pro=0&house=0&child=0&xz=0&sx=0&mz=0&hometownprovince=0']
# 增加redis_keys
redis_key = 'hongniang:start_urls'我们可以直接将 爬取的域和 开始的url 注释掉,添加上一个 redis_key ,通常这个reidskey 的写法就是: 爬虫名:start_urls
在reids 中,“:” 冒号将被生成像文件夹一样。
这个redis_key 设置的就是我们将来开始爬取的网址,即跟原来的 start_urls 一样。
其中allowed_domains 允许的域,如果不写方法设置,那么默认自动获取网址中的域。
修改基本就是这么多
整体代码:
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from hongniang.items import HongniangItem
# 1. 导入RedisCrawlSpider类,不使用CrawlSpider
from scrapy_redis.spiders import RedisCrawlSpider
class HongniangspiderSpider(RedisCrawlSpider):
name = 'hongniangSpider'
# allowed_domains = ['hongniang.com']
# start_urls = ['http://www.hongniang.com/index/search?sort=0&wh=0&sex=2&starage=0&province=0&city=0&marriage=0&edu=0&income=0&height=0&pro=0&house=0&child=0&xz=0&sx=0&mz=0&hometownprovince=0']
# 增加redis_keys
redis_key = 'hongniang:start_urls'
#中国红娘index页面的分页
page_lx = LinkExtractor(allow=('index/search\?.*&page=\d+'))
#个人详细的信息
self_lx = LinkExtractor(allow=('user/member/id/\d+'))
#规则
rules = (
Rule(page_lx,follow=True),
Rule(self_lx,callback='parse_item',follow=False)
)
def parse_item(self, response):
item = HongniangItem()
# 用户名称
item['nickname'] = self.get_nickname(response)
# 用户id
item['loveid'] = self.get_loveid(response)
# 用户的照片
item['photos'] = self.get_photos(response)
# 用户年龄
item['age'] = self.get_age(response)
# 用户的身高
item['height'] = self.get_height(response)
# 用户是否已婚
item['ismarried'] = self.get_ismarried(response)
# # 用户年收入
item['yearincome'] = self.get_yearincome(response)
# # 用户的学历
item['education'] = self.get_education(response)
# # 用户的地址
item['workaddress'] = self.get_workaddress(response)
# 用户的内心独白
item['soliloquy'] = self.get_soliloquy(response)
# 用户的性别
item['gender'] = self.get_gender(response)
print item
yield item
def get_nickname(self,response):
nickname = response.xpath('//div[@class="info1"]/div[@class="name nickname"]/text()').extract()[0]
if len(nickname)>0:
nickname = nickname.strip()
else:
nickname = "NULL"
return nickname
def get_loveid(self, response):
loveid = response.xpath('//div[@class="info1"]/div[@class="loveid"]/text()').extract()[0]
if len(loveid) > 0:
loveid = loveid.strip()
else:
loveid = "NULL"
return loveid
def get_photos(self, response):
photos = response.xpath('//div[@id="tFocus-btn"]/ul/li/img/@src').extract()
if len(photos) > 0:
pass
else:
photos = "NULL"
return photos
def get_age(self, response):
age = response.xpath('//div[@class="info2"]/div/ul/li/text()').extract()[0]
if len(age) > 0:
age = age.strip()
else:
age = "NULL"
return age
def get_height(self, response):
height = response.xpath('//div[@class="info2"]/div/ul/li/text()').extract()[2]
if len(height) > 0:
height = height.strip()
else:
height = "NULL"
return height
def get_ismarried(self, response):
ismarried = response.xpath('//div[@class="info2"]/div/ul/li/text()').extract()[1]
if len(ismarried) > 0:
ismarried = ismarried.strip()
else:
ismarried = "NULL"
return ismarried
def get_yearincome(self, response):
yearincome = response.xpath('//div[@class="info2"]/div/ul/li/text()').extract()[4]
if len(yearincome) > 0:
yearincome = yearincome.strip()
else:
yearincome = "NULL"
return yearincome
def get_education(self, response):
education = response.xpath('//div[@class="info2"]/div/ul/li/text()').extract()[3]
if len(education) > 0:
education = education.strip()
else:
education = "NULL"
return education
def get_workaddress(self, response):
workaddress = response.xpath('//div[@class="info2"]/div/ul/li/text()').extract()[5]
if len(workaddress) > 0:
workaddress = workaddress.strip()
else:
workaddress = "NULL"
return workaddress
def get_soliloquy(self, response):
soliloquy = response.xpath('//div[@class="info5"]/div[@class="text"]/text()').extract()[0]
if len(soliloquy) > 0:
soliloquy = soliloquy.strip()
else:
soliloquy = "NULL"
return soliloquy
def get_gender(self, response):
return "女"
(2)启动工程
在启动之前, 由于上一篇我们曾使用基础的redis 爬虫爬取过一次,我们先删除之前爬取的数据,在redis-manager 中删除即可。如果没有就没事。

启动该工程需要两步:
第一步,先启动我们的刚才写好的爬虫程序,跟原来的启动方式不一样。
scrapy runspider 爬虫文件名.py在我们这里就是 scrapy runspider hongniangSpider_redis2.py ,注意不是爬虫的类名,而是文件名
当我们的爬虫启动好之后,会出现等待。在等待开始的url 到来。
第二步,在redis 中设置开始的url
先进入redis 数据库
redis-cli -h 127.0.0.1 -p 6379
lpush 一下开始的url
lpush hongniang:start_urls http://xxx
当我们设置成功以后,爬虫程序就开始跑起来了。

我们也来看下,redis 数据库中的变化。
(3)将redis中的数据放入Mysql数据库中,保存一下
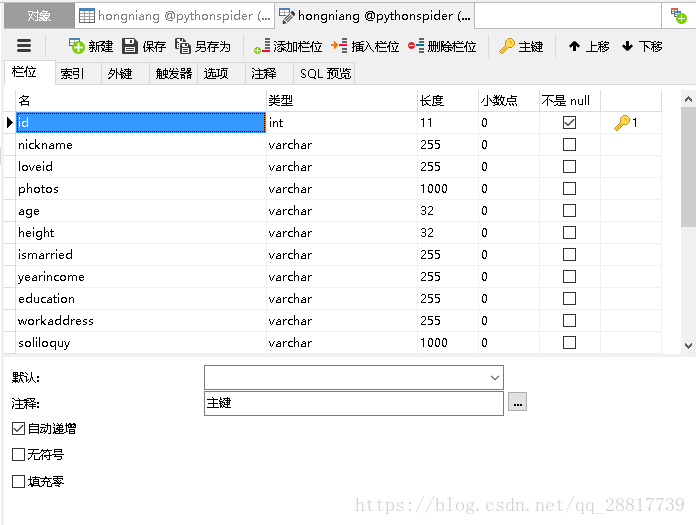
【1】先新建mysql数据库表,将我们item 中的字段设置到表中:
如果懒得创建,可以直接下载:https://github.com/gengzi/hongniang/blob/master/hongniang.sql
【2】编写代码,这一部分跟爬虫没有关系,可以直接写在爬虫外面运行即可。看代码吧。
一共两个文件:![]()
mysqlHelper.py 主要是一个工具,方便对mysql 操作。
# -*- coding:utf-8 -*-
# Hello world - 西蒙.科泽斯 这是“向编程之神所称颂的传统咒语,愿他帮助并保佑你更好的学习这门语言
import MySQLdb
class MysqlHelper():
"""
mysql 工具类
2018年2月26日14:32:34
"""
def __init__(self,host,port,db,user,passwd,charset='utf8'):
self.host=host
self.port=port
self.db=db
self.user=user
self.passwd=passwd
self.charset=charset
def connect(self):
self.conn=MySQLdb.connect(host=self.host,port=self.port,db=self.db,user=self.user,passwd=self.passwd,charset=self.charset)
self.cursor=self.conn.cursor()
def close(self):
self.cursor.close()
self.conn.close()
def get_one(self,sql,params=()):
result=None
try:
self.connect()
self.cursor.execute(sql, params)
result = self.cursor.fetchone()
self.close()
except Exception, e:
print e.message
return result
def get_all(self,sql,params=()):
list=()
try:
self.connect()
self.cursor.execute(sql,params)
list=self.cursor.fetchall()
self.close()
except Exception,e:
print e.message
return list
def insert(self,sql,params=()):
return self.__edit(sql,params)
def update(self, sql, params=()):
return self.__edit(sql, params)
def delete(self, sql, params=()):
return self.__edit(sql, params)
def __edit(self,sql,params):
count=0
try:
self.connect()
count=self.cursor.execute(sql,params)
self.conn.commit()
self.close()
except Exception,e:
print e.message
return count
ReidsToMysql.py 就是将redis 数据 转存到 mysql 中
#!/usr/bin/env python2
# -*- coding:utf-8 -*-
import redis
import json
from MysqlHelper import MysqlHelper
import sys
reload(sys)
sys.setdefaultencoding('utf8')
#获取mysql 的连接
mysql = MysqlHelper(host='123.206.30.117',port=3306,db='pythonspider',user='root',passwd='111')
#获取redis 的连接
rediscli = redis.StrictRedis(host='127.0.0.1', port = 6379, db = 0)
def process_redisdata():
"""
将redis 的数据,存放到mysql中
:return:
"""
while True:
# FIFO模式为 blpop,LIFO模式为 brpop,获取键值
source, data = rediscli.blpop(["hongniangSpider:items"])
#data = unicode(str(data).encode('utf-8'), "utf-8")
item = json.loads(data)
photos = ','.join(item['photos'])
sql = 'insert into hongniang(nickname,loveid,photos,age,height,ismarried,yearincome,education,workaddress,soliloquy,gender) ' \
'values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)';
params = [str(item['nickname']),str(item['loveid']),str(photos),str(item['age'])
,str(item['height']),str(item['ismarried']),str(item['yearincome']),str(item['education'])
, str(item['workaddress']),str(item['soliloquy']),str(item['gender'])]
insertnum = mysql.insert(sql=sql,params=params)
if insertnum > 0:
print "成功"
if __name__ == '__main__':
process_redisdata()直接运行 redistomap 这个py 文件即可。
查看我们保存的数据:

(4)总结
到这里,这个爬取中国红娘相亲网站基本就结束了,写的可能不是很清楚,可以参考源码再看文章。感觉不错就点个赞吧。
有什么问题可以提出,不胜感激。
源码:https://github.com/gengzi/hongniang