PdfBox解析pdf乱码
PdfBox解析
使用PdfBox解析pdf,出现了某些pdf无法解析的问题,折腾了几天终于解决,今天记录一下。
找到问题
将正常的pdf和不能解析的pdf对比,发现正常的pdf和非正常的pdf的样式不同,但是具体不知道两种文件各自的区别,于是使用pdf转化器,分别将两种pdf转化成word,正常的pdf转化出的pdf内容文字格式是SEACRC+Times-Roman,而不正常的文字格式是Calibri,初步判断是目前的PdfBox(使用的是2.0.4)版本不支持解析Calibri这种文字格式,所以解析内容全部乱码。
解决问题
于是去https://pdfbox.apache.org/2.0/commandline.html官网搜寻解决方案,发现官网提供了一种使用命令行工具的方式直接在服务器下执行的方式,于是下载pdfbox-app-2.0.2.jar包,然后根据规则编写执行命令:
java -jar pdfbox-app-2.0.2.jar ExtractText -startPage 1 -endPage 2 -encoding UTF-8 /home/data/rtpacs/webserver_8002/95.pdf /home/data/rtpacs/webserver_8002/951.txt
执行结果过程有警告,如下图:

打开结果文本:
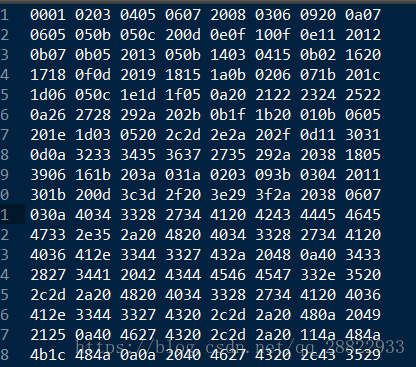
怀疑当前方法还是不行,于是用正常的pdf测试:
java -jar pdfbox-app-2.0.2.jar ExtractText -startPage 1 -endPage 2 -encoding UTF-8 /home/data/rtpacs/webserver_8002/6.pdf /home/data/rtpacs/webserver_8002/61.txt
结果文本打印出正确的内容,并且命令执行未报警告,发现这种命令行方式也不行,这下苦逼了,基本排除使用PdfBox来解决这个问题了,于是继续苦逼的找解决方案, 终于找到了一种解决方式,使用OCR技术解决。
思路:
1,将pdf转成png图片。
2,使用ocr图像文字识别技术识别图片中的文字,ocr的实现有两种方式:
1、调用百度、腾讯等ocr接口,
2、自建ocr库(主要使用 google 的库tesseract), java下可用tess4j
这里采用百度的ocr。
pdf转png
/*
* *
* 实现pdf文件转换为png
* 参数是第一个是要转的转换的是pdffile
* 第二个参数是是要存储的png图片的路径
*/
public static void pdfFileToImage(File pdffile, String targetPath) {
FileOutputStream fops = null;
try {
FileInputStream instream = null;
InputStream byteInputStream = null;
try {
instream = new FileInputStream(pdffile);
PDDocument doc = PDDocument.load(instream);
PDFRenderer renderer = new PDFRenderer(doc);
int pageCount = doc.getNumberOfPages();
if (pageCount > 0) {
BufferedImage image = renderer.renderImage(0, 2.0f);
image.flush();
ByteArrayOutputStream bs = new ByteArrayOutputStream();
ImageOutputStream imOut;
imOut = ImageIO.createImageOutputStream(bs);
ImageIO.write(image, "png", imOut);
byteInputStream = new ByteArrayInputStream(bs.toByteArray());
}
} catch (IOException e) {
e.printStackTrace();
} finally {
if (null != instream)
instream.close();
}
File uploadFile = new File(targetPath);
fops = new FileOutputStream(uploadFile);
fops.write(readInputStream(byteInputStream));
fops.flush();
} catch (Exception e) {
e.printStackTrace();
} finally {
if (null != fops) {
try {
fops.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
private static byte[] readInputStream(InputStream inStream) {
byte[] buffer = new byte[1024];
int len = 0;
try (ByteArrayOutputStream outStream = new ByteArrayOutputStream()) {
while ((len = inStream.read(buffer)) != -1) {
outStream.write(buffer, 0, len);
}
return outStream.toByteArray();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (null != inStream) {
try {
inStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return buffer;
}
public static void main(String[] args) {
File file =new File("e:\\95.pdf");
//上传的是png格式的图片结尾
String targetfile="e:\\95.png";
pdfFileToImage(file,targetfile);
}
ocr识别图片文字
1,登录百度云的后台,获取APP_ID,API_KEY,SECRET_KEY。
2,根据官方技术文档,编写代码。
导入依赖:
com.baidu.aip
java-sdk
4.7.0
识别文字:
public static void main(String[] args) throws IOException {
// 初始化一个AipOcr
AipOcr client = new AipOcr(APP_ID, API_KEY, SECRET_KEY);
// 可选:设置网络连接参数
client.setConnectionTimeoutInMillis(2000);
client.setSocketTimeoutInMillis(60000);
// 可选:设置代理服务器地址, http和socket二选一,或者均不设置
// client.setHttpProxy("proxy_host", proxy_port); // 设置http代理
// client.setSocketProxy("proxy_host", proxy_port); // 设置socket代理
// 可选:设置log4j日志输出格式,若不设置,则使用默认配置
// 也可以直接通过jvm启动参数设置此环境变量
// System.setProperty("aip.log4j.conf", "path/to/your/log4j.properties");
sample(client);
}
public static void sample(AipOcr client) throws IOException {
// 传入可选参数调用接口
HashMap options = new HashMap();
options.put("detect_direction", "true");
options.put("probability", "true");
// 参数为本地图片路径
String image = "e:\\95.png";
// 参数为本地图片二进制数组
byte[] file = fileToBinArray(new File(image));
JSONObject res = client.basicAccurateGeneral(file, options);
System.out.println(res.toString());
}
public static byte[] fileToBinArray(File file) {
try {
InputStream fis = new FileInputStream(file);
byte[] bytes = FileCopyUtils.copyToByteArray(fis);
return bytes;
} catch (Exception ex) {
throw new RuntimeException("transform file into bin Array 出错", ex);
}
}
到此,终于解决了乱码问题,获取到了pdf中的内容,剩下的只需正则匹配即可了!