文本匹配论文及pytorch版复现(一):DRCN
一、模型
1、模型总图
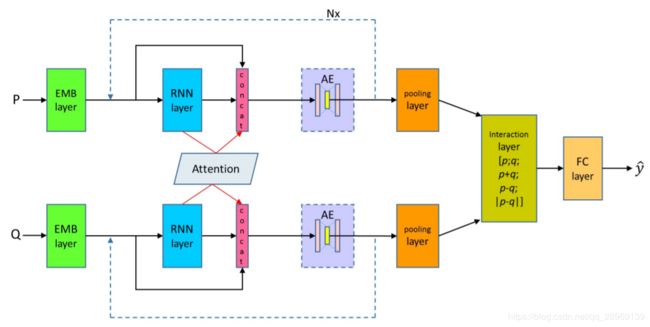
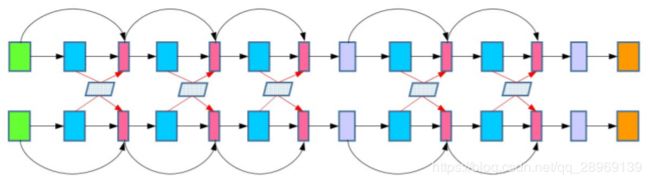
2、实施细则
二、相关公式
1、词表示层:字符卷积cp,静态预训练词嵌入ep(fix),可训练预训练词嵌入ep(tr)
fp代表,两句中字是否在另一句中出现,若是为1,若否为0
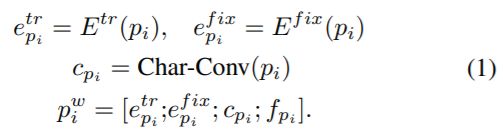
2、层次RNN和互注意力机制

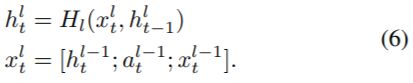
原始输入x,通过RNN获取隐层表示h,将两句的隐层表示hi,hj通过互注意力机制,获取注意力表示ai,aj
3、自动编码器auto-encoder
全连接层,将高维度表示转化为低维度表示
4、交互层和分类层
More specifically, if the output of the final RNN layer is a 100d vector for a sentence with 30 words, a 30 × 100 matrix is obtained which is max-pooled column-wise such that the size of the resultant vector p or q is 100.
将p,q向量通过maxpooling获取特征。再进入如下融合
最终表示
![]()
最终通过线性变换和激活函数,得到输出结果。
三、代码实现
1、模型model.py
from torch import nn, tensor
import numpy as np
import torch
import joblib
# 总体模型
class DRCN(nn.Module):
def __init__(self, word2vec=None):
super(DRCN, self).__init__()
num_embeddings = 14206
num_classes = 2
embedding_dim = 300
lstm_dim = 100
ae_dim = 200
fc_dim = 1000
embed_dp = 0.5
ae_dp = 0.2
lc_dp = 0.2
self.embed = WordEmbedding(num_embeddings, embedding_dim, word2vec, dropout=embed_dp)
input_size = embedding_dim * 2 + 1
self.rnn1 = RNNCoAttention(input_size, lstm_dim)
input_size += 4 * lstm_dim
self.rnn2 = RNNCoAttention(input_size, lstm_dim)
input_size += 4 * lstm_dim
self.rnn3 = RNNCoAttention(input_size, lstm_dim)
input_size += 4 * lstm_dim
self.ae1 = AutoEncoder(input_size, ae_dim, dropout=ae_dp)
input_size = ae_dim
self.rnn4 = RNNCoAttention(input_size, lstm_dim)
input_size += 4 * lstm_dim
self.rnn5 = RNNCoAttention(input_size, lstm_dim)
input_size += 4 * lstm_dim
self.ae2 = AutoEncoder(input_size, ae_dim, dropout=ae_dp)
self.fc = InteractPredict(5 * ae_dim + 1, fc_dim, num_classes, lc_dp)
def forward(self, p, q, fp, fq):
loss = 0
p, q = self.embed(p, q, fp, fq)
p, q = self.rnn1(p, q)
p, q = self.rnn2(p, q)
p, q = self.rnn3(p, q)
p, q, ae_loss = self.ae1(p, q)
loss += ae_loss
p, q = self.rnn4(p, q)
p, q = self.rnn5(p, q)
p, q, ae_loss = self.ae2(p, q)
loss += ae_loss
y = self.fc(p, q)
return y, loss
# 词嵌入层
class WordEmbedding(nn.Module):
# word2vec. gloVe 300dim
def __init__(self, num_embeddings, embedding_dim, word2vec=None, dropout=0.5):
super(WordEmbedding, self).__init__()
# 设置 no trainable
self.static_embed = nn.Embedding(num_embeddings, embedding_dim, 0)
if word2vec is not None:
self.static_embed.weight.data.copy_(torch.from_numpy(word2vec))
self.static_embed.weight.requires_grad = False
else:
self.static_embed.weight.requires_grad = True
# 设置 trainable
self.train_embed = nn.Embedding(num_embeddings, embedding_dim, 0)
if word2vec is not None:
self.train_embed.weight.data.copy_(torch.from_numpy(word2vec))
self.train_embed.weight.requires_grad = True
self.dropout = nn.Dropout(dropout)
def forward(self, xp, xq, fp, fq):
xp = self.singleForword(xp, fp)
xq = self.singleForword(xq, fq)
return xp, xq
def singleForword(self, x, f):
x = torch.cat([self.train_embed(x), self.static_embed(x), f.unsqueeze(2)], dim=2)
x = self.dropout(x)
return x
# RNN互注意力层
class RNNCoAttention(nn.Module):
# out_size = in_size + 4 * hi_size
def __init__(self, input_size, hidden_size):
super(RNNCoAttention, self).__init__()
self.lstm = nn.LSTM(input_size, hidden_size, bidirectional=True)
def forward(self, xp, xq):
hp, _ = self.lstm(xp)
hq, _ = self.lstm(xq)
ap, aq = self.co_attention(hp, hq)
xp = torch.cat([hp, ap, xp], dim=2)
xq = torch.cat([hq, aq, xq], dim=2)
return xp, xq
def co_attention(self, hp, hq):
batch_size, seq_len, embedding_dim = hp.size()
mul_p = torch.cat([hp.unsqueeze(1) for i in range(seq_len)], dim=1)
mul_p = mul_p.transpose(1, 2).contiguous().view(batch_size, -1, embedding_dim)
mul_q = torch.cat([hq for i in range(seq_len)], dim=1)
p2q = torch.cosine_similarity(mul_p, mul_q, dim=2)
p2q = p2q.view(batch_size, seq_len, seq_len)
q2p = p2q.transpose(1, 2)
p2q_soft = torch.softmax(p2q, dim=2)
ap = torch.matmul(p2q_soft, hq)
q2p_soft = torch.softmax(q2p, dim=2)
aq = torch.matmul(q2p_soft, hp)
return ap, aq
#自动编码器层
class AutoEncoder(nn.Module):
def __init__(self, input_size, hidden_size, dropout=0.2):
super(AutoEncoder, self).__init__()
self.fc1 = nn.Sequential(
nn.Linear(input_size, hidden_size),
nn.Dropout(dropout)
)
self.fc2 = nn.Linear(hidden_size, input_size)
self.loss_func = nn.MSELoss()
def forward(self, xp, xq):
hp, lp = self.singleForword(xp)
hq, lq = self.singleForword(xq)
loss = lp + lq
return hp, hq, loss
def singleForword(self, x):
h = self.fc1(x)
y = self.fc2(h)
l = self.loss_func(x, y)
return h, l
#信息交互与预测层
class InteractPredict(nn.Module):
def __init__(self, input_size, hidden_size, num_classes, dropout=0.2):
super(InteractPredict, self).__init__()
self.dropout = nn.Dropout(dropout)
self.fc1 = nn.Sequential(
nn.Linear(input_size, hidden_size),
nn.BatchNorm1d(hidden_size),
nn.LeakyReLU(),
nn.Linear(hidden_size, hidden_size),
nn.BatchNorm1d(hidden_size),
nn.LeakyReLU(),
)
self.fc2 = nn.Sequential(
nn.Linear(hidden_size, num_classes),
)
def forward(self, p, q):
v = self.interaction(p, q)
v = self.dropout(v)
v = self.fc1(v)
v = self.fc2(v)
return v
def interaction(self, p, q):
p, _ = p.max(dim=1)
q, _ = q.max(dim=1)
asymmetric = p - q # asymmetric
asy_mod = ((asymmetric ** 2).sum(dim=1) ** 0.5).unsqueeze(1)
v = torch.cat([p, q, p + q, p * q, asymmetric, asy_mod], dim=1)
return v
#模拟数据
if __name__ == '__main__':
batch_size = 32
seq_len = 20
embedding_dim = 300
num_embeddings = 14205 + 1
lstm_dim = 100
ae_dim = 200
fc_dim = 1000
num_classes = 2
p = tensor(np.random.randint(0, num_embeddings, (batch_size, seq_len)), dtype=torch.long)
q = tensor(np.random.randint(0, num_embeddings, (batch_size, seq_len)), dtype=torch.long)
pf = tensor(np.random.random((batch_size, seq_len)), dtype=torch.float)
qf = tensor(np.random.random((batch_size, seq_len)), dtype=torch.float)
model = DRCN()
y, l = model(p, q, pf, qf)
print(y.size())