prometheus+grafana+alertmanager搭建服务器告警监控平台
prometheus+grafana+alertmanager搭建服务器告警监控平台
前言
流程简单说一下,在各目标服务器上运行node-exporter及cadvisor服务,然后在服务端部署prometheus服务用以监控各目标服务器的硬件资源及服务的使用状态,部署grafana服务用以将监控数据可视化,图形界面展示更方便,alertmanager服务用以从prometheus那里获取告警信息,并将之以各种形式发送至管理员或者群内。整个就是一套prometheus+grafana+alertmanager的监控告警流程。
1、受监控端部署node-exporter及cadvisor
docker-compose部署
version: "3"
services:
node-exporter:
image: quay.io/prometheus/node-exporter
container_name: prometheus_node-exporter
restart: always
logging:
driver: "json-file"
options:
max-size: "10m"
max-file: "5"
ports:
- 9100:9100
volumes:
- /proc:/host/proc:ro
- /sys:/host/sys:ro
- /:/rootfs:ro
command:
- '--path.procfs=/host/proc'
- '--path.sysfs=/host/sys'
- '--collector.filesystem.ignored-mount-points=^/(sys|proc|dev|host|etc|rootfs/var/lib/docker/containers|rootfs/var/lib/docker/overlay2|rootfs/run/docker/netns|rootfs/var/lib/docker/devicemapper|rootfs/var/lib/docker/aufs)($$|/)'
cadvisor:
image: google/cadvisor:latest
restart: always
logging:
driver: "json-file"
options:
max-size: "10m"
max-file: "5"
ports:
- 9101:8080
volumes:
- /:/rootfs:ro
- /var/run:/var/run:rw
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
2、管理端部署prometheus
docker run -d -p 9090:9090 --name prometheus -v /root/data/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml -v /root/data/prometheus/rules.yml:/etc/prometheus/rules.yml prom/prometheus:v2.17.1
prometheus.yml配置文件
global:
scrape_interval: 15s
evaluation_interval: 15s
# Attach these labels to any time series or alerts when communicating with
# external systems (federation, remote storage, Alertmanager).
external_labels:
monitor: 'docker-host-alpha'
# Load and evaluate rules in this file every 'evaluation_interval' seconds.
rule_files:
- "rules.yml"
# A scrape configuration containing exactly one endpoint to scrape.
scrape_configs:
- job_name: 'nodeexporter'
scrape_interval: 5s
static_configs:
- targets: ['xxxx:9100'] //你的受监控端node-exporter的地址
- job_name: 'cadvisor'
scrape_interval: 5s
static_configs:
- targets: ['xxxx:9101'] //你的受监控端cadvisor的地址
alerting:
alertmanagers:
- scheme: http
static_configs:
- targets:
- '192.168.xxx.xxx:9093' //你的alertmanager服务地址
rules.yml配置文件
groups:
- name: rule
rules:
- alert: 磁盘使用率
expr: (node_filesystem_size_bytes{device="rootfs"} - node_filesystem_free_bytes{device="rootfs"}) / node_filesystem_size_bytes{device="rootfs"} * 100 > 80
for: 2m
labels:
team: node
severity: warning
annotations:
summary: "{{$labels.instance}}: High Filesystem usage detected"
message: "{{$labels.instance}}: 磁盘使用率>80% (当前使用率: {{ $value }})"
- alert: 内存使用率
expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes+node_memory_Buffers_bytes+node_memory_Cached_bytes )) / node_memory_MemTotal_bytes * 100 > 80
for: 2m
labels:
team: node
severity: warning
annotations:
summary: "{{$labels.instance}}: High Memory usage detected"
message: "{{$labels.instance}}: 内存使用率>80% (当前使用率: {{ $value }})"
- alert: cpu使用率
expr: (100 - (avg by (instance) (irate(node_cpu_seconds_total{job="kubernetes-node-exporter",mode="idle"}[5m])) * 100)) > 80
for: 2m
labels:
team: node
severity: warning
annotations:
summary: "{{$labels.instance}}: High CPU usage detected"
message: "{{$labels.instance}}: CPU使用率>80% (当前使用率: {{ $value }})"
注意:需要将prometheus.yml和rules.yml这2个配置文件映射到容器中,前者可以指定使用哪个alert告警规则文件,后者可以设定告警格式及内容。
部署成功之后打开web界面可以看到以下信息


3、管理端部署grafana
docker run -d -p 3000:3000 --name grafana grafana/grafana:6.7.2
容器运行之后打开web界面,初次登陆用户名密码为admin,admin。

现在我们的grafana暂时是没有dashboards的,我们可以自己编写或者选择上传别人的模板

上传之后的监控效果


以下链接是我上图中使用的主机硬件资源监控模板以及docker容器监控模板,需要的可以自行下载。
json模板网盘下载地址 提取码wdas
4、部署wxwork_wechat_robot
wxwork_wechat_robot是整合alertmanager告警信息的一个工具,可以收集信息并将之发送至企业微信机器人等各种工具上。
项目git地址:https://github.com/daozzg/work_wechat_robot.git
docker-composer up -d 运行wxwork_wechat_robot容器
![]()
5、部署alertmanager
docker run -d --name alertmanager -p 9093:9093 -v /root/data/alertmanager/:/etc/alertmanager/ prom/alertmanager:v0.20.0 --config.file=/etc/alertmanager/alertmanager.yml
alertmanager.yml配置文件
global:
resolve_timeout: 2m
route:
receiver: 'webhook'
group_wait: 30s
group_interval: 5m
repeat_interval: 60m
receivers:
- name: 'webhook'
webhook_configs:
- send_resolved: true
url: 'http://192.168.xx.xxx:8080/prometheus_webhook'
http_config:
bearer_token: 'xxxx-xxxx-xxxx-xxxx'
注意:将alertmanager整个目录映射进容器,并指定配置文件,配置文件中,url改成部署了work_wechat_robot服务的地址,如http://192.168.32.xxx:8080/prometheus_webhook,bearer_token值改成企业微信机器人webhook地址后面key的值。
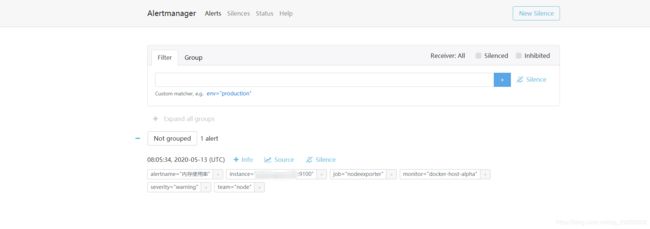
部署成功之后,打开web可以看到已经从prometheus那里获取了告警信息。
打开企业微信,可以看到企业微信机器人已经成功将告警信息发送至告警群。
