webmagic爬虫自学(三)爬取CSDN【列表+详情的基本页面组合】的页面,使用基于注解的方式
一、搭建项目开发环境
1、applicationContext-myBatis.xml
2、applicationContext.xml
3、log4j.xml
4、pom.xml
4.0.0
us.codecraft
jobhunter
1.0-SNAPSHOT
UTF-8
/
3.1.1.RELEASE
3.1.0.RELEASE
us.codecraft
webmagic-core
0.7.3
us.codecraft
webmagic-extension
0.7.3
us.codecraft
webmagic-selenium
0.7.3
org.seleniumhq.selenium
selenium-java
3.0.1
org.seleniumhq.selenium
selenium-chrome-driver
3.0.1
org.seleniumhq.selenium
selenium-server
2.18.0
org.springframework
spring-jdbc
${spring-version}
org.apache.commons
commons-lang3
3.1
javax.servlet
servlet-api
2.5
mysql
mysql-connector-java
5.1.18
commons-dbcp
commons-dbcp
1.3
junit
junit
4.7
test
org.mybatis
mybatis
3.1.1
org.mybatis
mybatis-spring
1.1.1
org.springframework
spring-test
${spring-version}
test
org.json
json
20160810
com.fasterxml.jackson.core
jackson-databind
2.5.2
org.codehaus.jackson
jackson-core-asl
1.9.13
org.codehaus.jackson
jackson-mapper-asl
1.9.13
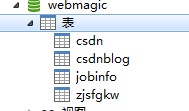
5、mysql数据库
/*
Navicat MySQL Data Transfer
Source Server : mclass
Source Server Version : 50523
Source Host : localhost:3306
Source Database : webmagic
Target Server Type : MYSQL
Target Server Version : 50523
File Encoding : 65001
Date: 2019-04-15 14:16:13
*/
SET FOREIGN_KEY_CHECKS=0;
-- ----------------------------
-- Table structure for csdn
-- ----------------------------
DROP TABLE IF EXISTS `csdn`;
CREATE TABLE `csdn` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`article` varchar(200) DEFAULT NULL,
`time` varchar(100) DEFAULT NULL,
`nick_name` varchar(200) DEFAULT NULL,
`read_count` int(11) DEFAULT NULL,
`label` varchar(200) DEFAULT NULL,
`category` varchar(200) DEFAULT NULL,
`content` longtext,
`url` varchar(500) DEFAULT NULL,
`collect_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Table structure for csdnblog
-- ----------------------------
DROP TABLE IF EXISTS `csdnblog`;
CREATE TABLE `csdnblog` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`blogId` int(11) NOT NULL,
`title` varchar(255) NOT NULL,
`blogDate` varchar(16) DEFAULT NULL,
`tags` varchar(255) DEFAULT NULL,
`category` varchar(255) DEFAULT NULL,
`view` int(11) DEFAULT NULL,
`comments` int(11) DEFAULT NULL,
`copyright` int(11) DEFAULT NULL,
`url` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Table structure for jobinfo
-- ----------------------------
DROP TABLE IF EXISTS `jobinfo`;
CREATE TABLE `jobinfo` (
`ID` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(200) NOT NULL DEFAULT '',
`salary` varchar(200) NOT NULL DEFAULT '',
`company` varchar(200) NOT NULL DEFAULT '',
`description` varchar(6000) NOT NULL DEFAULT '',
`source` varchar(200) NOT NULL DEFAULT '',
`url` varchar(5000) NOT NULL DEFAULT '',
`urlMd5` varchar(100) NOT NULL DEFAULT '',
`collect_time` datetime DEFAULT NULL,
PRIMARY KEY (`ID`),
UNIQUE KEY `un_ix_url_md5` (`urlMd5`),
KEY `ix_source` (`source`)
) ENGINE=InnoDB AUTO_INCREMENT=17869 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Table structure for zjsfgkw
-- ----------------------------
DROP TABLE IF EXISTS `zjsfgkw`;
CREATE TABLE `zjsfgkw` (
`id` int(11) NOT NULL,
`title` varchar(500) DEFAULT NULL,
`content` longtext,
`court` varchar(500) DEFAULT NULL,
`time` varchar(200) DEFAULT NULL,
`url` varchar(300) DEFAULT NULL,
`collect_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
6、JdbcUtil 连接数据库工具类
package util;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Statement;
public class JdbcUtil {
private static final String URL="jdbc:mysql://localhost:3306/webmagic";
private static final String USER="root";
private static final String PASSWORD="123456";
private static Connection conn = null;
static {
try{
//1.加载驱动
Class.forName("com.mysql.jdbc.Driver");
//2.获得数据库的连接
conn = DriverManager.getConnection(URL, USER, PASSWORD);
} catch(ClassNotFoundException e){
e.printStackTrace();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
public static Connection getConnection(){
return conn;
}
}
7、JsonUtils解析工具类
package util;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import com.alibaba.fastjson.JSONObject;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.codehaus.jackson.map.ObjectMapper;
import org.codehaus.jackson.map.SerializationConfig;
import org.codehaus.jackson.type.TypeReference;
/**
* 所属类别:核心工具类
* 用途:提供JSON格式数据操作方法
* @author yl
* version:1.0
*/
public abstract class JsonUtils {
private static Log log = LogFactory.getLog(JsonUtils.class);
private static ObjectMapper mapper = new ObjectMapper();
static{
mapper.configure(SerializationConfig.Feature.FAIL_ON_EMPTY_BEANS, false);
}
/**
* 将Json转为String
* @param object
* @return
*/
public static String objectToString(Object object) {
try {
String string = mapper.writeValueAsString(object);
return string;
} catch (Exception er) {
log.error("转换为JsonString出错:", er);
return null;
}
}
/**
* 将String转为Json
* @param object
* @return
*/
public static T stringToObject(String jsonString,
TypeReference typeReference) {
try {
return mapper.readValue(jsonString, typeReference);
} catch (Exception er) {
log.error("转换为Object出错:", er);
return null;
}
}
/**
* json字符串转换为对象
* @param jsonString
* @param clazz
* @return
*/
public static T stringToObject(String jsonString,Class clazz){
try {
return mapper.readValue(jsonString, clazz);
} catch (Exception er) {
log.error("转换为Object出错:", er);
return null;
}
}
/**
* 把JsonObject的字符串转换成Map
* @param jsonObjectStr
* @return
*/
public static Map parseJsonObjectStrToMap(String jsonObjectStr) {
Map map = new HashMap();
try {
if(jsonObjectStr != null) {
org.json.JSONObject jsonObject = new org.json.JSONObject(jsonObjectStr);
for(int j=0;j iterator = jsonObject.keys();
while(iterator.hasNext()) {
String key = iterator.next();
Object value = jsonObject.get(key);
map.put(key, value);
}
}
}
} catch(Exception e) {
e.printStackTrace();
}
if(map.size() == 0) {
return null;
}
return map;
}
/**
* 把JsonArray的字符串转换成List>
* @param jsonArrayStr
* @return
*/
public static List> parseJsonArrayStrToListForMaps(String jsonArrayStr) {
List> list = new ArrayList>();
try {
if(jsonArrayStr != null) {
org.json.JSONArray jsonArray = new org.json.JSONArray(jsonArrayStr);
Map map = null;
for(int j=0;j map) {
return JSONObject.toJSONString(map);
}
public static void main(String[] args) {
String s="[{\"206bcae8e434408e9aa026ac5dbe0b3a\":\"3\",\"f192a9d80a0b4f6aaf801957a8b1866e\":\"1\",\"61fafdf6433147bc936765f7f26db00b\":\"2\"},{\"206bcae8e434408e9aa026ac5dbe0b3a\":\"3\",\"f192a9d80a0b4f6aaf801957a8b1866e\":\"1\",\"61fafdf6433147bc936765f7f26db00b\":\"2\"}]";
System.out.println(JsonUtils.stringToObject(s, new TypeReference>>(){}));
String s1="{\"206bcae8e434408e9aa026ac5dbe0b3a\":\"3\",\"f192a9d80a0b4f6aaf801957a8b1866e\":\"1\",\"61fafdf6433147bc936765f7f26db00b\":\"2\"},{\"206bcae8e434408e9aa026ac5dbe0b3a\":\"3\",\"f192a9d80a0b4f6aaf801957a8b1866e\":\"1\",\"61fafdf6433147bc936765f7f26db00b\":\"2\"}";
System.out.println(JsonUtils.parseJsonObjectStrToMap(s1));
Map map = new HashMap<>();
map.put("a", 123);
System.out.println(JsonUtils.parseMapToJsonObject(map));
}
}
二、爬取CSDN【列表+详情的基本页面组合】的页面
1、目录结构

2、创建CsdnModel.java 文件,爬取模型类,基于注解的模式是webmagic提供的一个快捷开发模式,只需要 对@HelpUrl 和@TargetUrl进行配置即可,详细参考官方文档。
package demo.blog.csdn.net.model;
import java.util.Date;
import java.util.List;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.model.AfterExtractor;
import us.codecraft.webmagic.model.annotation.ExtractBy;
import us.codecraft.webmagic.model.annotation.ExtractByUrl;
import us.codecraft.webmagic.model.annotation.HelpUrl;
import us.codecraft.webmagic.model.annotation.TargetUrl;
@TargetUrl("https://blog.csdn.net/qq_29914837/article/details/[0-9]*")
@HelpUrl("https://blog.csdn.net/qq_29914837/article/list/[0-9]*?")
public class CsdnModel implements AfterExtractor{
//标题
@ExtractBy(value="//h1[@class='title-article']/text()",notNull = true)
private String article="";
//发布日期
// @Formatter("yyyy-MM-dd HH:mm")@ExtractBy(value="//span[@class='time']/text()")
@ExtractBy("//span[@class='time']/text()")
private String time;
//作者
@ExtractBy(value="//a[@class='follow-nickName']/text()",notNull = true)
private String nick_name="";
//阅读数
@ExtractBy(value="//span[@class='read-count']/regex('\\d+')",notNull = true)
private int read_count;
//标签
@ExtractBy(value = "//span[@class='tags-box artic-tag-box']//a[@class='tag-link']/text()", multi = true)
private List labelList;
private String label="";
//分类
@ExtractBy(value="//div[@class='tags-box space']//a[@class='tag-link']/text()" , multi = true)
private List categoryList;
private String category="";
//内容
@ExtractBy(value="//div[@id='content_views']/html()")
private String content="";
//链接
@ExtractByUrl
private String url="";
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
//采集时间
private Date collect_time;
public Date getCollect_time() {
return collect_time;
}
public void setCollect_time(Date collect_time) {
this.collect_time = collect_time;
}
public String getArticle() {
return article;
}
public void setArticle(String article) {
this.article = article;
}
public String getTime() {
return time;
}
public void setTime(String time) {
this.time = time;
}
public String getNick_name() {
return nick_name;
}
public void setNick_name(String nick_name) {
this.nick_name = nick_name;
}
public int getRead_count() {
return read_count;
}
public void setRead_count(int read_count) {
this.read_count = read_count;
}
public List getLabelList() {
return labelList;
}
public void setLabelList(List labelList) {
this.labelList = labelList;
}
public List getCategoryList() {
return categoryList;
}
public void setCategoryList(List categoryList) {
this.categoryList = categoryList;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
public String getLabel() {
return label;
}
public void setLabel(String label) {
this.label = label;
}
public String getCategory() {
return category;
}
public void setCategory(String category) {
this.category = category;
}
@Override
public void afterProcess(Page page) {
this.collect_time = new Date();
this.label = setValue(labelList);
this.category = setValue(categoryList);
}
private String setValue(List labelList){
StringBuilder sb = new StringBuilder();
if(labelList.size()>0 && labelList!=null){
for (String string : labelList) {
sb.append(string).append("|");
}
return sb.substring(0,sb.lastIndexOf("|"));
}else{
return "";
}
}
}
package demo.blog.csdn.net.dao;
import org.apache.ibatis.annotations.Insert;
import demo.blog.csdn.net.model.CsdnModel;
public interface CsdnDAO {
@Insert("insert into csdn (`article`,`time`,`nick_name`,`read_count`,`label`,`category`,`content`,`url`,`collect_time`) values (#{article},#{time},#{nick_name},#{read_count},#{label},#{category},#{content},#{url},#{collect_time})")
public int add(CsdnModel csdnModel);
}
package demo.blog.csdn.net.pipeline;
import org.springframework.stereotype.Component;
import demo.blog.csdn.net.dao.CsdnDAO;
import demo.blog.csdn.net.model.CsdnModel;
import us.codecraft.webmagic.Task;
import us.codecraft.webmagic.pipeline.PageModelPipeline;
import javax.annotation.Resource;
@Component("CsdnDaoPipeline")
public class CsdnDaoPipeline implements PageModelPipeline {
@Resource
private CsdnDAO csdnDAO;
@Override
public void process(CsdnModel csdnModel, Task task) {
csdnDAO.add(csdnModel);
}
}
解析mvc模式的 【列表+详情的基本页面组合】的页面,使用基于注解的方式
package demo.blog.csdn.net;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
import org.springframework.stereotype.Component;
import demo.blog.csdn.net.model.CsdnModel;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.model.OOSpider;
import us.codecraft.webmagic.pipeline.PageModelPipeline;
/**
* 爬取网址:https://blog.csdn.net/qq_29914837/article/list/0?
* 解析mvc模式的 【列表+详情的基本页面组合】的页面,使用基于注解的方式
* @author yl
*/
@Component
public class CsdnCrawler {
private static String csdn_name = "qq_29914837";
@Qualifier("CsdnDaoPipeline")
@Autowired
private PageModelPipeline csdnDaoPipeline;
public void crawl() {
OOSpider.create(Site.me()
.setUserAgent("Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36")
, csdnDaoPipeline, CsdnModel.class)
.addUrl("https://blog.csdn.net/"+csdn_name+"/article/list/0?")
.thread(5)
.run();
}
public static void main(String[] args) {
ApplicationContext applicationContext = new ClassPathXmlApplicationContext("classpath:/spring/applicationContext*.xml");
final CsdnCrawler csdnCrawler = applicationContext.getBean(CsdnCrawler.class);
csdnCrawler.crawl();
}
}
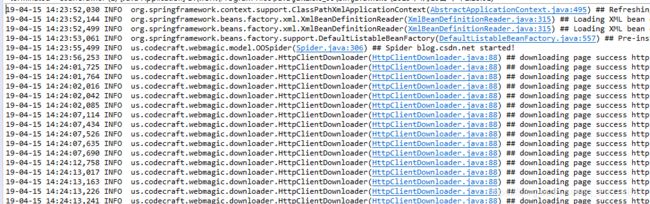
run as 运行 main 方法 ,控制台输出,代表爬虫成功,可以查看数据库是否有爬虫的文章信息。
如果你觉得本篇文章对你有所帮助的话,麻烦请点击头像右边的关注按钮,谢谢!
技术在交流中进步,知识在分享中传播