算法总结 & 归纳
文章目录
- 算法总结
- 第一章 链表
- 链表求环
- 复杂链表的复制
- 第二章 栈、队列、堆
- 使用队列实现栈
- 使用栈实现队列
- 包含min函数的栈
- 栈的压入、弹出序列
- 第三章 贪心算法
- 剪绳子
- 摇摆序列(贪心 & dp)
- 移除K个数字
- 跳跃问题2
- 射击气球
- 第四章 递归、回溯与分治
- (一)递归
- Fibonacci数列
- 矩形覆盖
- (二)回溯
- 全排列
- 求子集
- N皇后问题
- 机器人运动范围
- 火柴棍摆正方形
- (三)分治
- 归并排序
- 快速排序
- 求数组中的逆序对
- 第五章 二叉树 与 图
- 课程安排(有向图判断环)
- 重建二叉树
- 二叉树中和为某一值的路径
- 二叉树下一个节点
- 对称的二叉树
- 按之字形顺序打印二叉树
- 第六章 二分查找与二叉排序树
- 旋转数组的最小值
- 判断数组是否为二叉搜索树后续遍历序列
- 求二叉搜索树中第k小的节点
- 第七章 哈希表与字符串
- 无重复字符的最长子串
- 最小窗口子串
- 词语模式
- 无重复字符的最长子串(优化)
- 第八章 搜索
- 词语阶梯2
- 第九章 动态规划
- 求最多能赚多少钱
- 求是否存在所选数组求和 = 给定值
- 连续子数组的最大和
- 滑动窗口最大值
- 找零钱
- 第十章 复杂的数据结构
- 添加与查找单词
- 朋友圈
- 区域和查询
- 第十一章 其他
- 二维数组的查找
- 二进制中1的个数
- 调整数组顺序使奇数位于偶数前面
- 丑数
- 正则表达式匹配
- 表示数值的字符串
算法总结
第一章 链表
- 数据结构
public class ListNode {
int val; // 存储当前结点数据域
ListNode next; // 存储下一个结点指针域
ListNode(int x) { val = x; }
}
注:采用头插法/尾插法创建链表时,一般设定一个空节点作为首节点,避免对头结点的单独处理。
- 典型例题
链表求环
题目描述
给定一个链表,判断链表中是否有环。
算法思路
- 遍历链表,将链表中结点对应的指针(地址),插入set
- 在遍历时插入节点前,需要在set中查找,第一个在set中发现的结点地址,就是链表环的起点
程序代码
// 141.环形链表
// 给定一个链表,判断链表中是否有环。
// 为了表示给定链表中的环,我们使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。
// 如果 pos 是 -1,则在该链表中没有环。
public boolean hasCycle(ListNode head) {
// 1.遍历链表,将链表中结点对应的指针(地址),插入set
// 2.在遍历时插入节点前,需要在set中查找,第一个在set中发现的结点地址,就是链表环的起点
Set nodeList = new HashSet<>();
ListNode p = head;
if(head == null)return false;
while(p!=null) {
// set求环起始节点,该节点时遍历时,第一个在set中已经出现的结点,即环的开始
if(nodeList.contains(p))return true;
nodeList.add(p);
p = p.next;
}
return false;
}
复杂链表的复制
题目描述
给定一个链表,每个节点包含一个额外增加的随机指针,该指针可以指向链表中的任何节点或空节点。
要求返回这个链表的深拷贝。
算法思路
- 从 head 节点开始遍历链表。下图中,我们首先创造新的 head 拷贝节点。并将新建结点加入字典中。
- 如果当前节点 i 的 random 指针指向一个节点 j 且节点 j 已经被拷贝过,我们将直接使用已访问字典中该节点的引用而不会新建节点。
如果当前节点 i 的 random 指针指向的节点 j 还没有被拷贝过,我们就对 j 节点创建对应的新节点,并把它放入已访问节点字典中。 - 如果当前节点 i 的 next 指针指向一个节点 j 且节点 j 已经被拷贝过,我们将直接使用已访问字典中该节点的引用而不会新建节点。
如果当前节点 i 的 next 指针指向的节点 j 还没有被拷贝过,我们就对 j 节点创建对应的新节点,并把它放入已访问节点字典中。
程序代码
// 138. 复制带随机指针的链表
// 给定一个链表,每个节点包含一个额外增加的随机指针,该指针可以指向链表中的任何节点或空节点。
// 要求返回这个链表的深拷贝。
public Node copyRandomList(Node head) {
// 返回深度拷贝后的链表
// 深度拷贝:构造生成一个完全新的链表,即使将原链表毁坏,新链表可独立使用
// 算法步骤:
// 1. 从 head 节点开始遍历链表。下图中,我们首先创造新的 head 拷贝节点。并将新建结点加入字典中。
// 2. 如果当前节点 i 的 random 指针指向一个节点 j 且节点 j 已经被拷贝过,我们将直接使用已访问字典中该节点的引用而不会新建节点。
// 如果当前节点 i 的 random 指针指向的节点 j 还没有被拷贝过,我们就对 j 节点创建对应的新节点,并把它放入已访问节点字典中。
// 3. 如果当前节点 i 的 next 指针指向一个节点 j 且节点 j 已经被拷贝过,我们将直接使用已访问字典中该节点的引用而不会新建节点。
// 如果当前节点 i 的 next 指针指向的节点 j 还没有被拷贝过,我们就对 j 节点创建对应的新节点,并把它放入已访问节点字典中。
if(head == null)return head;
Node copy_head = new Node(head.val,null,null); // 拷贝结点的头结点
Map<Node,Node> node_map = new HashMap<Node,Node>(); // 结点字典,存储已拷贝<原链表结点,拷贝链表结点>键值对
node_map.put(head, copy_head); //将头结点插入字典
Node old_p = head; // p为原链表索引结点
Node copy_p = copy_head; // copy_p为拷贝链表的索引指针
while(old_p != null) {
copy_p.random = copyCloneNode(old_p.random,node_map); // 拷贝结点的random引用
copy_p.next = copyCloneNode(old_p.next,node_map); // 拷贝结点的next引用
old_p = old_p.next;
copy_p = copy_p.next;
}
return copy_head; // 拷贝链表头结点
}
public Node copyCloneNode(Node oldNode,Map<Node,Node> nodeMap) {
// 对原结点进行深度拷贝
if(oldNode == null )return null;
else if(nodeMap.containsKey(oldNode)) {
// 该结点已存在字典中
return nodeMap.get(oldNode);
}else {
// 该结点不存在,构造新结点并加入字典中
Node copyNode = new Node(oldNode.val,null,null);
nodeMap.put(oldNode, copyNode);
return copyNode;
}
}
第二章 栈、队列、堆
- Stack(栈)
| 方法 | 功能 |
|---|---|
| Stack stack = new Stack() | 创建栈 |
| empty() | 测试堆栈是否为空 |
| peek() | 查看堆栈顶部的对象,但不从堆栈中移除它 |
| pop() | 移除堆栈顶部的对象,并作为此函数的值返回该对象 |
| push(item) | 把项压入堆栈顶部 |
- Queue(队列)
| 方法 | 功能 |
|---|---|
| Queue queue=new LinkedList() | 创建队列 |
| peek() | 获取但不移除此队列的头;如果此队列为空,则返回 null |
| poll() | 获取并移除此队列的头,如果此队列为空,则返回 null |
| offer(item) | 将指定的元素插入此队列(如果立即可行且不会违反容量限制),当使用有容量限制的队列时,无法插入元素 |
- Heap(堆)
优先队列PriorityQueue——二叉堆,最小(大)值先出
- 优先级队列(priority queue)中的元素可以按照任意的顺序输入,却总是按照排序的顺序进行检索。也就是说,无论何时调用 poll 方法,总会获得当前优先级队列中最小的元素。
- 优先级队列可实现堆 (heap)数据结构 。执行 offer 和 poll 操作,可以让最小的元素移动到队首,而不必花费时间对元素进行排序。
- 一个优先级队列既可以保存实现了 Comparable 接口的类对象,也可以保存在构造器中提供的 Comparator 对象。
Queue<int> priorityQueue = new PriorityQueue<int>();//默认的队列 int按照从大至小
// 根据Comparator方法,按照人口大小排序
Comparator<Person> cmp = new Comparator<Person>() {
public int compare(Person arg0, Person arg1) {
// TODO Auto-generated method stub
int num_a = arg0.getPopulation();
int num_b = arg1.getPopulation();
if(num_a < num_b) return 1;
else if(num_a > num_b) return -1;
else return 0;
}
};
Queue<Person> priorityQueue = new PriorityQueue<Person>(11,cmp);
-
Deque(双端队列)
官方推荐Deques实现堆栈,Deque的12种方法总结如下:
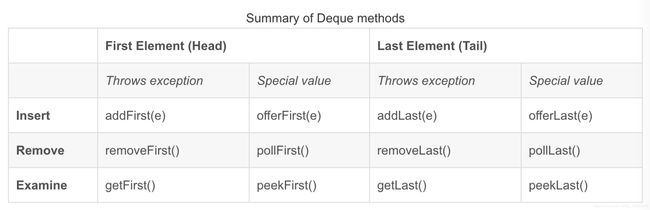
-
Deque接口用作队列时,将得到 FIFO(先进先出)行为。将元素添加到双端队列的末尾,从双端队列的开头移除元素。从Queue 接口继承的方法完全等效于 Deque 方法,如下表所示:
| Deque | Queue | |
|---|---|---|
| 获取队头元素 | peekFirst() | peek() |
| 移除队头 | pollFirst() | poll() |
| 插入队尾 | offerLast(item) | offer(item) |
- Deque也可以被用作LIFO的栈,此时的接口应该严格参照Stack类的实现。当deque被用作栈时,元素在deque的head端push/pop。栈的方法等价于Deque中的一些方法,如下表:
| Deque | Stack | |
|---|---|---|
| 获取队头元素 | peekFirst() | peek() |
| 移除栈首 | pollFirst() | pop() |
| 插入栈首 | offerFirst(item) | push(item) |
- 典型例题
使用队列实现栈
题目描述
使用队列实现栈的下列操作:
push(x) – 元素 x 入栈
pop() – 移除栈顶元素
top() – 获取栈顶元素
empty() – 返回栈是否为空
算法思路
使用队列实现栈
在STACK push元素时,利用临时队列调换元素次序
方法:
- 将新元素 push 进入临时队列 temp_queue
- 将原队列内容 push 进入临时队列 temp_queue
- 将临时队列元素 push 进入数据队列 data_queue
- 得到数据队列结果
程序代码
public static class MyStack {
// 使用队列实现栈
// 在STACK push元素时,利用临时队列调换元素次序
// 方法:
// 1. 将新元素 push 进入临时队列 temp_queue
// 2. 将原队列内容 push 进入临时队列 temp_queue
// 3. 将临时队列元素 push 进入数据队列 data_queue
// 4. 得到数据队列结果
Queue<Integer> data_queue; // 数据队列
Queue<Integer> temp_queue; // 临时队列
/** Initialize your data structure here. */
public MyStack() {
data_queue = new LinkedList<Integer>();
temp_queue = new LinkedList<Integer>();
}
public void push(int x) {
temp_queue.offer(x);
while(!data_queue.isEmpty()) {temp_queue.offer(data_queue.poll());}
while(!temp_queue.isEmpty())data_queue.offer(temp_queue.poll());
}
public int pop() {
return data_queue.poll();
}
public int top() {
return data_queue.peek();
}
/** Returns whether the stack is empty. */
public boolean empty() {
return data_queue.isEmpty();
}
public void print() {
for(Iterator<Integer> iter=data_queue.iterator();iter.hasNext();)
{
Integer temp = iter.next();
System.out.println(temp+" ");
}
System.out.print("\n");
}
}
使用栈实现队列
题目描述
使用栈实现队列的下列操作:
push(x) – 将一个元素放入队列的尾部。
pop() – 从队列首部移除元素。
peek() – 返回队列首部的元素。
empty() – 返回队列是否为空。
算法思路
用栈实现队列
在队列 push 元素时,利用 临时栈 调换元素次序
- 将 原数据栈 data_stack 内容 push 进入 临时栈 temp_stack
- 将新数据 push 进入临时栈 temp_stack
- 将临时栈 temp_stack 中的元素 push 进入数据栈 data_stack
- 得到数据栈 data_stack
程序代码
public static class MyQueue {
// 用栈实现队列
// 在队列 push 元素时,利用 临时栈 调换元素次序
// 1. 将 原数据栈 data_stack 内容 push 进入 临时栈 temp_stack
// 2. 将新数据 push 进入临时栈 temp_stack
// 3. 将临时栈 temp_stack 中的元素 push 进入数据栈 data_stack
// 4. 得到数据栈 data_stack
Stack<Integer> data_stack; // 数据栈
Stack<Integer> temp_stack; // 临时栈
public MyQueue() {
data_stack = new Stack<Integer>();
temp_stack = new Stack<Integer>();
}
public void push(int x) {
while(!data_stack.isEmpty()) temp_stack.push(data_stack.pop());
temp_stack.push(x);
while(!temp_stack.isEmpty())data_stack.push(temp_stack.pop());
}
public int pop() {
return data_stack.pop();
}
public int peek() {
return data_stack.peek();
}
public boolean empty() {
return data_stack.isEmpty();
}
}
包含min函数的栈
题目描述
设计一个支持 push,pop,top 操作,并能在常数时间内检索到最小元素的栈。
push(x) – 将元素 x 推入栈中。
pop() – 删除栈顶的元素。
top() – 获取栈顶元素。
getMin() – 检索栈中的最小元素。
算法思路
定义一个最小值栈,存储各个状态下的最小值
程序代码
class MinStack {
// 155.最小栈
// 设计一个支持 push,pop,top 操作,并能在常数时间内检索到最小元素的栈。
// 定义一个最小值栈,存储各个状态下的最小值
Stack<Integer> data_stack;
Stack<Integer> min_stack;
public MinStack() {
data_stack = new Stack<Integer>();
min_stack = new Stack<Integer>(); // 最小值栈,存储各个状态下最小值
}
public void push(int x) {
data_stack.push(x);
if(min_stack.isEmpty()) {min_stack.push(x);}
else if( x < min_stack.peek())
min_stack.push(x);
else min_stack.push(min_stack.peek());
}
public void pop() {
data_stack.pop();
min_stack.pop();
}
public int top() {
return data_stack.peek();
}
public int getMin() {
return min_stack.peek();
}
}
栈的压入、弹出序列
题目描述
输入两个整数序列,第一个序列表示栈的压入顺序,请判断第二个序列是否可能为该栈的弹出顺序。假设压入栈的所有数字均不相等例如序列1,2,3,4,5是某栈的压入顺序,序列4,5,3,2,1是该压栈序列对应的一个弹出序列,但4,3,5,1,2就不可能是该压栈序列的弹出序列。(注意:这两个序列的长度是相等的)
算法思路
采用队列 & 栈 模拟
- 出栈结果存储在队列order中
- 按元素顺序,将元素push进入栈
- 每push一个元素,即检查是否与队列首部元素相同,若相同则弹出队首元素,弹出栈顶元素,直到两个元素不同结束
- 若最终栈为空,说明序列合法,否则不合法
程序代码
public boolean validateStackSequences(int[] pushed, int[] popped) {
// 采用队列 & 栈 模拟
// 1. 出栈结果存储在队列order中
// 2. 按元素顺序,将元素push进入栈
// 3. 每push一个元素,即检查是否与队列首部元素相同,若相同则弹出队首元素,弹出栈顶元素,直到两个元素不同结束
// 4. 若最终栈为空,说明序列合法,否则不合法
if (pushed.length != popped.length)
return false;
Stack<Integer> stack = new Stack<Integer>(); // stack为模拟栈
Queue<Integer> queue = new LinkedList<Integer>(); // queue为存储结果队列
// 将出栈结果存入队列
for(int i=0;i<popped.length;i++)queue.offer(popped[i]);
for(int i=0;i<pushed.length;i++) {
stack.push(pushed[i]); // 将入栈队列顺序入栈
while(!stack.isEmpty() && stack.peek() == queue.peek()) {
stack.pop();
queue.poll();
}
}
if(!stack.isEmpty())return false;
return true;
}
第三章 贪心算法
所谓贪心算法是指,在对问题求解时,总是做出在当前看来是最好的选择。也就是说,不从整体最优上加以考虑,他所做出的仅是在某种意义上的局部最优解。
- 基本思路
- 建立数学模型来描述问题。
- 把求解的问题分成若干个子问题。
- 对每一子问题求解,得到子问题的局部最优解。
- 把子问题的局部最优解合成原来解问题的一个解。
- 解题格式
从问题的某一初始解出发;
while (能朝给定总目标前进一步)
{
利用可行的决策,求出可行解的一个解元素;
}
由所有解元素组合成问题的一个可行解;
- 典型例题
剪绳子
题目描述
给你一根长度为n的绳子,请把绳子剪成m段(m、n都是整数,n>1并且m>1),每段绳子的长度记为k[0],k[1],…,k[m]。请问k[0]xk[1]x…xk[m]可能的最大乘积是多少?例如,当绳子的长度是8时,我们把它剪成长度分别为2、3、3的三段,此时得到的最大乘积是18。
输入描述:
输入一个数n,意义见题面。(2 <= n <= 60)
输出描述:
输出答案。
程序代码
// 66. 剪绳子
// 给你一根长度为n的绳子,请把绳子剪成m段(m、n都是整数,n>1并且m>1),
// 每段绳子的长度记为k[0],k[1],...,k[m]。请问k[0]xk[1]x...xk[m]可能的最大乘积是多少?
// 例如,当绳子的长度是8时,我们把它剪成长度分别为2、3、3的三段,此时得到的最大乘积是18。
List<Integer> maxMultiList = new ArrayList<Integer>(); // 最大乘积列表
public int cutRope(int target) {
// 1. 长度为target的绳子可分为1...n段
// 2. 分别对1...n段绳子求能得到最大乘积的结果
// 根据数学计算,可知,当a+b+c+..和相等(=target)的情况下,最大乘积即a,b,c..间差值最小的情况
// 3. 比较所有分段方式的最大乘积,得到绳子减法的最大乘积
for(int i=1;i<target;i++)
getMaxMultiOfMPart(target,i+1);
Collections.sort(maxMultiList);
if(maxMultiList!=null && maxMultiList.size()>0)return maxMultiList.get(maxMultiList.size()-1);
return 0;
}
public void getMaxMultiOfMPart(int n,int m) {
// 求长度为n,分成m段的绳子的最大乘积
int[] ropePart = new int[m];
int multiResult = 1;
int i = 0; // i表示第i+1段绳子的长度
while(i != m) {
ropePart[i] = n/(m-i);
n -= n/(m-i);
i++;
}
for(i=0;i<m;i++)multiResult *= ropePart[i];
maxMultiList.add(multiResult);
}
public static void main(String[] args) {
Greedy greedy = new Greedy();
System.out.println(greedy.cutRope(2));
}
摇摆序列(贪心 & dp)
题目描述
如果连续数字之间的差严格地在正数和负数之间交替,则数字序列称为摆动序列。第一个差(如果存在的话)可能是正数或负数。少于两个元素的序列也是摆动序列。
例如, [1,7,4,9,2,5] 是一个摆动序列,因为差值 (6,-3,5,-7,3) 是正负交替出现的。相反, [1,4,7,2,5] 和 [1,7,4,5,5] 不是摆动序列,第一个序列是因为它的前两个差值都是正数,第二个序列是因为它的最后一个差值为零。
给定一个整数序列,返回作为摆动序列的最长子序列的长度。 通过从原始序列中删除一些(也可以不删除)元素来获得子序列,剩下的元素保持其原始顺序。
示例 1:
输入: [1,7,4,9,2,5]
输出: 6
解释: 整个序列均为摆动序列。
示例 2:
输入: [1,17,5,10,13,15,10,5,16,8]
输出: 7
解释: 这个序列包含几个长度为 7 摆动序列,其中一个可为[1,17,10,13,10,16,8]。
示例 3:
输入: [1,2,3,4,5,6,7,8,9]
输出: 2
解题思路
贪心思想:当序列有一段连续的 递增(递减)时,为了形成摇摆子序列,只需要保留这段连续的递增(递减)的首位元素,这样更可能使尾部的后一个元素成为摇摆子序列下一个元素。
选择贪心元素目标:成为摇摆子序列的下一个元素的概率更大,摇摆子序列长度++。
程序代码
public int wiggleMaxLength(int[] nums) {
//贪心规律
//当序列有一段连续的递增(或递减)时,为形成摇摆子序列,我们只需要保留这段连续的递增(或者递减)的首尾元素
//这样更可能使尾部后一个元素成为摇摆子序列的下一个元素
if(nums == null || nums.length == 0)return 0;//序列为空
if(nums.length < 2)return nums.length;//序列个数小于2时直接为摇摆序列
int maxLength = 1;//摆动子序列长度至少为1
//采用状态机的设计思想,扫描。扫描序列共有3种状态。
int state = 0;//state表示当前状态,初始状态为BEGIN
final int BEGIN = 0;//初始状态
final int UP = 1;//上升状态
final int DOWN = 2;//下降状态
for(int i=1;i<nums.length;i++) {//从第2个元素开始扫描
switch(state) {
//state表示当前状态,switch表示进行状态转换
case BEGIN:
if(nums[i-1]<nums[i]) {
state = UP;
maxLength++;
}
else if(nums[i-1]>nums[i]) {
state = DOWN;
maxLength++;
}
break;
case UP:
//由于保留递增区间的末端元素,故只需要在状态转换时加入摇摆子序列。
if(nums[i-1]>nums[i]) {
state = DOWN;
maxLength++;
}
break;
case DOWN:
//由于保留递减区间的末端元素,故只需要在状态转换时加入摇摆子序列。
if(nums[i-1]<nums[i]) {
state = UP;
maxLength++;
}
break;
}
}
return maxLength;
}
移除K个数字
题目描述
给定一个以字符串表示的非负整数 num,移除这个数中的 k 位数字,使得剩下的数字最小。
注意:
num 的长度小于 10002 且 ≥ k。
num 不会包含任何前导零。
示例 1 :
输入: num = "1432219", k = 3
输出: "1219"
解释: 移除掉三个数字 4, 3, 和 2 形成一个新的最小的数字 1219。
示例 2 :
输入: num = "10200", k = 1
输出: "200"
解释: 移掉首位的 1 剩下的数字为 200. 注意输出不能有任何前导零。
示例 3 :
输入: num = "10", k = 2
输出: "0"
解释: 从原数字移除所有的数字,剩余为空就是0。
解题思路
贪心思想:
若去掉某一位数字,为了使得到的新数字最小,需尽可能地让得到的新数字优先最高位最小,其次次高位最小,再其次第三位最小
故应从高位向低位遍历。如果对应的数字大于下一个数字,则把该位数字去掉,得到的数字最小。若去掉K个数字,可从最高位开始遍历,选择最小的数字;共需遍历K次。
可使用栈存储最终结果或删除工作。从高位向低位遍历nums,如果遍历的数字大于栈顶元素,则将数字push入栈;如果小于栈顶元素,则进行弹栈操作,直到
- 栈为空
- 不能再删除数字(k=0)
- 栈顶小于当前元素
程序代码
public String removeKdigits(String num, int k) {
//贪心思想:
//若去掉某一位数字,为了使得到的新数字最小,需尽可能地让得到的新数字优先最高位最小,其次次高位最小,再其次第三位最小
//故应从高位向低位遍历。如果对应的数字大于下一个数字,则把该位数字去掉,得到的数字最小。
//若去掉K个数字,可从最高位开始遍历,选择最小的数字;共需遍历K次
//可使用栈存储最终结果或删除工作。从高位向低位遍历nums
//如果遍历的数字大于栈顶元素,则将数字push入栈;如果小于栈顶元素,则进行弹栈操作,直到
//(1)栈为空(2)不能再删除数字(k=0)(3)栈顶小于当前元素
//注意两种特殊情况(1)原数组中含有0(2)遍历完后仍可删除
Stack<Integer> s = new Stack<Integer>();
Stack<Integer> r = new Stack<Integer>();
String result = "";
for(int i=0;i<num.length();i++) {
//从最高位开始对字符串中数字遍历
Integer number = Integer.parseInt(num.charAt(i)+"");
while(s.isEmpty()==false && number<s.peek() && k>0) {
//当栈不为空 && 当前遍历元素<栈顶元素 && 仍然可移除元素
s.pop();//弹出栈顶元素
k--; //可删除元素减一
}
//否则则可将当前遍历元素入栈
//含有0的情况:注意当栈为空时不能将0元素入栈
if(!(s.size()==0 && number == 0)) {
s.push(number);
}
}
//如果遍历完所有元素,且仍存在可移除元素,则从栈顶开始一一移除
while(s.isEmpty()==false && k>0) {
s.pop();
k--;
}
//栈中元素转化为字符串,若移除所有元素(栈为空),则返回"0"
if(s.isEmpty())result = "0";
while(!s.isEmpty()) {
Integer ele = s.pop();
r.push(ele);
}
while(!r.isEmpty()) {
Integer ele = r.pop();
result+= ele + "";
}
return result;
}
跳跃问题2
题目描述
给定一个非负整数数组,你最初位于数组的第一个位置。数组中的每个元素代表你在该位置可以跳跃的最大长度。你的目标是使用最少的跳跃次数到达数组的最后一个位置。
示例:
输入: [2,3,1,1,4]
输出: 2
解释: 跳到最后一个位置的最小跳跃数是 2。
从下标为 0 跳到下标为 1 的位置,跳 1 步,然后跳 3 步到达数组的最后一个位置。
说明:
假设你总是可以到达数组的最后一个位置。
解题思路
贪心思想
在到达某点之前若一直不跳跃,发现从该点不能跳到更远的地方了,在这之前肯定有次必要的跳跃。因此,如果希望最少跳跃达到终点,则需要明确何时进行跳跃最合适。
因为假设总是可以到达数组的最后一个位置。因此如果无法达到更远的位置时,在此之前一定可以跳到一个到达更远位置的位置。
算法步骤
- 设置current_max_index为当前可到达最远位置
- 设置pre_max_index为在遍历各个位置的过程中,各个位置可到达的最远位置
- 设置jump_min为最少跳跃的次数
- 利用i遍历nums数组,若i超过current_max_index,jump_min加1,current_max_index = pre_max_index
- 遍历过程中,若nums[i]+i(index[i])更大,需更新pre_max_index = index[i]
程序代码
public int jump(int[] nums) {
//贪心思想:
//在到达某点之前若一直不跳跃,发现从该点不能跳到更远的地方了,在这之前肯定有次必要的跳跃。
//因此,如果希望最少跳跃达到终点,则需要明确何时进行跳跃最合适。
//因为假设总是可以到达数组的最后一个位置。因此如果无法达到更远的位置时,在此之前一定可以跳到一个到达更远位置的位置。
//因此,遍历nums中每一个元素(假设不跳跃),并记录所有遍历位置中可到达的最大位置,
//若遍历的位置i超过当前可以到达的最远位置,则将最少跳跃的次数++,并将当前可以到达位置更新为遍历过位置中最远位置
if(nums.length<2)return 0;//若数组长度<2,说明不用跳跃,返回0
int current_max_index = nums[0];//当前可到达最远距离,初始化为nums[0]
int pre_max_index = nums[0];//遍历过位置可到达最远距离,初始化为nums[0]
int jump_min = 1;//最少跳跃次数,初始化为1
int[] index = new int[nums.length];//最远距离数组,存储nums中每个位置最远可跳跃的位置
for(int i=0;i<nums.length;i++)
index[i] = nums[i]+i;
for(int i=0;i<nums.length;i++) {
//遍历nums数组
if(i>current_max_index) {
//如果遍历位置i超过可以到达最远位置,则在该位置之前一定可以到达一个更远的位置(基础:一定可以到达终点)
//故应该选择这个更远的位置开始跳跃,并更新可以到达最远位置
jump_min++;//需要进行一次跳跃
current_max_index = pre_max_index;//选择遍历位置中可跳跃的最远位置
}
//遍历过程中更新pre_max_index
if(pre_max_index<index[i])
pre_max_index = nums[i] + i;
}
return jump_min;
}
射击气球
题目描述
在二维空间中有许多球形的气球。对于每个气球,提供的输入是水平方向上,气球直径的开始和结束坐标。由于它是水平的,所以y坐标并不重要,因此只要知道开始和结束的x坐标就足够了。开始坐标总是小于结束坐标。平面内最多存在104个气球。
一支弓箭可以沿着x轴从不同点完全垂直地射出。在坐标x处射出一支箭,若有一个气球的直径的开始和结束坐标为 xstart,xend, 且满足 xstart ≤ x ≤ xend,则该气球会被引爆。可以射出的弓箭的数量没有限制。 弓箭一旦被射出之后,可以无限地前进。我们想找到使得所有气球全部被引爆,所需的弓箭的最小数量。
Example:
输入:
[[10,16], [2,8], [1,6], [7,12]]
输出:
2
解释:
对于该样例,我们可以在x = 6(射爆[2,8],[1,6]两个气球)和 x = 11(射爆另外两个气球)。
解题思路
贪心规律
- 对于某个气球,至少需要使用一只弓箭将它击穿
- 在这只气球将其击穿的同时,尽可能击穿其他更多的气球
算法思路
- 对各个气球进行排序,按照气球的左端点从小到大排序
- 遍历气球数组,同时维护一个射击区间,在满足可以将当前气球射穿的情况下,尽可能击穿更多的气球,每击穿一个新的气球,更新一次射击区间(保证射击可以将新气球也击穿)
- 如果新的气球没办法被击穿,则需要增加一名弓箭手,即维护一个新的射击区间(将该气球击穿),然后继续遍历气球数组。
程序代码
public int findMinArrowShots(int[][] points) {
//贪心规律:
//1.对于某个气球,至少需要使用一只弓箭将它击穿
//2.在这只气球将其击穿的同时,尽可能击穿其他更多的气球
//算法思路:
//1.对各个气球进行排序,按照气球的左端点从小到大排序
//2.遍历气球数组,同时维护一个射击区间,在满足可以将当前气球射穿的情况下,尽可能击穿更多的气球,每击穿一个新的气球,更新一次射击区间
//(保证射击可以将新气球也击穿)
//3.如果新的气球没办法被击穿,则需要增加一名弓箭手,即维护一个新的射击区间(将该气球击穿),然后继续遍历气球数组。
if(points.length == 0) return 0;//传入数据为空,直接返回0
//将传入数据列表化
List<Point> pointList = new ArrayList();
for(int i=0;i<points.length;i++) {
Point p = new Point(points[i][0],points[i][1]);
pointList.add(p);
}
//将气球按照左端点的大小进行排序
Collections.sort(pointList, new Comparator<Point>(){
@Override
public int compare(Point p1, Point p2) {
return p1.start - p2.start;
}
});
int shot_num = 1;//射击次数初始为1
int shot_begin = pointList.get(0).start;//射击区间起点初始为第一个气球数组的起点
int shot_end = pointList.get(0).end;//射击区间终点初始为第一个气球数组的终点
for(int i=0;i<pointList.size();i++) {
//遍历气球数组
if(pointList.get(i).start<=shot_end) {
//当前气球数组起点在射击区间终点内,则说明可以射击当前气球,则可更新射击区间(取可射击到当前气球的区间交集)
shot_begin = pointList.get(i).start;
if(shot_end>pointList.get(i).end)shot_end = pointList.get(i).end;
}else {
//当前气球数组起点在射击区间终点外,没有重合,则说明无法射击当前气球,则不能更新射击区间
//为了使当前气球被射穿,应该增加射击次数,增加一个新的射击区间
shot_num++;
shot_begin = pointList.get(i).start;
shot_end = pointList.get(i).end;
}
}
return shot_num;
}
//气球端点
public class Point{
public Integer start;
public Integer end;
Point(Integer start,Integer end){
this.start = start;
this.end = end;
}
}
第四章 递归、回溯与分治
(一)递归
当需要重复地多次计算相同的问题,通常可以采用递归或循环。递归是在一个函数内部调用这个函数自身。
- 算法特点
(1)核心:将一个问题拆分成等价的两个或多个小问题。(注意重叠部分)
(2)当需要重复地多次计算相同的问题。(循环可以写成递归形式)
(3)可利用高等数学中的递归函数求解。(n与n-k关系)
(4)模拟栈。(通过出栈入栈模拟递归数据变化) - 解题格式
递归一定包括两部分:(1)递归关系(2)递归出口
递归代码先写递归出口,再写递归关系。 - 典型例题
Fibonacci数列
题目描述
大家都知道斐波那契数列,现在要求输入一个整数n,请你输出斐波那契数列的第n项(从0开始,第0项为0)。n<=39
解题思路
(1)递归关系
f(n)=f(n-1)+f(n-2)
(2)递归出口
f(1)=1
f(2)=1
程序代码
public int Fibonacci(int n) {
//题目条件
if(n==0)return 0;
//递归出口
if(n==1)return 1;
else if(n==2)return 1;
//递归关系
else return Fibonacci(n-1)+Fibonacci(n-2);
}
矩形覆盖
题目描述
我们可以用2 * 1的小矩形横着或者竖着去覆盖更大的矩形。请问用n个2 * 1的小矩形无重叠地覆盖一个2 * n的大矩形,总共有多少种方法?
解题思路
- target <= 0 大矩形为<= 2 * 0,直接return 1;
- target = 1大矩形为2 * 1,只有一种摆放方法,return1;
- target = 2 大矩形为2 * 2,有两种摆放方法,return2;
- target = n 分为两步考虑:
第一次摆放一块2 * 1的小矩阵,则摆放方法总共为f(target - 1)
| √ | |||||||
|---|---|---|---|---|---|---|---|
| √ |
第一次摆放一块1 * 2的小矩阵,则摆放方法总共为f(target-2)
因为,摆放了一块1 * 2的小矩阵(用√√表示),对应下方的1 * 2(用××表示)摆放方法就确定了,所以为f(targte-2)
| √ | √ | ||||||
|---|---|---|---|---|---|---|---|
| × | × |
程序代码
public int RectCover(int target) {
//实际情况:矩形宽度为0,则没有覆盖方法
if(target == 0)return 0;
//初始摆放有2种,若第一次竖放,则有f(n-1)种放法,如第一次横放,则第二次必须横放,共有f(n-2)种放法
if(target == 1)return 1;
else if(target == 2)return 2;
else return RectCover(target-1)+RectCover(target-2);
}
(二)回溯
回溯法("回溯"字面意思为回到溯源/根部)是一种穷举的搜索尝试过程,主要是在搜索尝试过程中寻找问题的解,当探索到某一步时,发现原先选择达不到目标,就退回一步重新选择,尝试别的路径,这种走不通就退回再走的技术称为回溯法。是使用了递归思想的一种算法。
- 算法特点
(1)适用于走路径问题(所走路径是否满足要求) -> 路径中的每个位置可看做解空间的一个节点
(2)适用于数组排列问题(某种排列是否满足要求) -> 排列的每个位置可看做解空间的一个节点 - 算法思想
回溯法实际是一种搜索算法。它在包含问题的所有解的解空间树中,按照深度优先的策略,从根结点出发搜索解空间树。
算法搜索至解空间树的任一结点时,总是先判断该结点是否肯定不包含问题的解。
(1)如果肯定不包含,则跳过对以该结点为根的子树的系统搜索,逐层向其祖先结点回溯。
(2)否则,进入该子树,继续按深度优先的策略进行搜索。
回溯法在用来求问题的所有解时,要回溯到根,且根结点的所有子树都已被搜索遍才结束。 - 解题格式
List<> answer;//存放一个解
List<List<>> result;//返回值,存放所有解的结集
void backtrack(int i,int n,List<> answer,other parameters)
{
//i代表解空间的第i个位置,往往从0开始,而n则代表解空间的大小,一次递归表示对解空间第i个位置进行处理
if( i == n)
{
//处理解空间第n个位置,表示处理完解空间所有位置,为一个解。将解存入结果集。
result.add(new ArrayList(answer));
return;
}
//搜索解空间第i个位置上的所有解
for(next ans in position i of solution space)
{
//求解空间第i个位置上的下一个解
doSomething(answer,i);//修改解的位置i
backtrack(i+1,n,other parameters);//递归对解空间i+1位置进行处理
RevertSomething(answer,i);//恢复解的位置i
}
}
- 典型例题
全排列
题目描述
给定一个没有重复数字的序列,返回其所有可能的全排列。
解题思路
求一个数组的全排列,就是把这个数组中的每个位置的元素分别放在数组头部,然后求剩余元素的全排列.
递归边界是剩余元素数量为1,也就是说当数组中只剩一个元素的时候,它的全排列就是它本身。
程序代码
// 46.全排列
//给定一个没有重复数字的序列,返回其所有可能的全排列。
// 理解全排列:找由根出发的所有路径
public List<List<Integer>> permute(int[] nums) {
List<List<Integer>> result = new ArrayList<>();//存储全排列的所有结果
List<Integer> answer = new ArrayList<Integer>(); // 存储全排列一个结果
int[] visit = new int[nums.length]; // 访问数组
for(int i=0;i<nums.length;i++) {
visit[i] = 0;
}
generatePermute(nums,visit,0,nums.length,answer,result);
return result;
}
void generatePermute(int[] nums,int[] visit,int i,int size,List<Integer> answer,List<List<Integer>> result) {
// 全排列集合中放置第 i 个位置元素
answer = new ArrayList<>(answer);
if(i==size) {
result.add(answer);//深度复制,为全排列的一个结果,存储一个对象而非引用(否则所有结果都指向同一地址,结果相同)
return;
}
// 遍历所有元素,若该元素未加入当前路径,则加入,并对下一个位置放置元素
// 回溯思想:结束该位置所有路径访问时,弹出元素,并恢复加入元素前状态(remove + visit[j]=0)
for(int j=0;j<size;j++)
if(visit[j] == 0) {
answer.add(nums[j]);
visit[j] = 1;
generatePermute(nums,visit,i+1,size,answer,result);
answer.remove(answer.size()-1);
visit[j] = 0;
}
}
求子集
题目描述
给定一个可能包含重复元素的整数数组 nums,返回该数组所有可能的子集(幂集)。
说明:解集不能包含重复的子集。
解题思路
解法与【求子集1】类似。解空间为一次递归表示放入|不放入第idx元素时的子集序列。先放入idx元素,表示包含idx元素的子集情况,再对后续元素处理;再拿出idx元素,表示不包含idx元素的子集情况,再对后续元素处理。
因为原数组包含重复元素,所以需要防止重复:不同位置,相同元素组成的集合为同一子集,因为集合中元素是无序的。解决方案是先对原nums进行排序,再使用set去重。
程序代码
public List<List<Integer>> subsetsWithDup(int[] nums) {
List<List<Integer>> result = new ArrayList<>();//结果数组,存储所有的子集序列
List<Integer> subset = new ArrayList<>();//子集,为某个子集数组
//防止重复:不同位置,相同元素组成的集合为同一子集。因为集合中的元素是无序的。
//解决方法:先对原nums数组排序,再使用set去重
Arrays.sort(nums);
List<Integer> numsList = new ArrayList<>();//集合化
for(int i=0;i<nums.length;i++)
numsList.add(nums[i]);
generateSubsetsWithDup(result,subset,numsList,0);
result.add(subset);//需要加入空集
return result;
}
public void generateSubsetsWithDup(List<List<Integer>> result,List<Integer> subset,List<Integer> numsList,int idx) {
//表示放入|不放入第idx元素时的子集序列
//先放入idx元素,再对后续元素(idx+1,...)进行处理;
//再拿出idx元素,并对后续元素(idx+1,...)进行处理;
if(idx==numsList.size())//处理完所有元素
return;
subset.add(numsList.get(idx));//放入idx元素
//剪枝:
//如果结果集中包含该子集,由于原数组是排好序的,所以之后所有的子集均为重复,不需继续执行
//对于没有意义的搜索,可采取剪枝。可大幅度提升搜索效率。
if(!result.contains(subset)) {
result.add(new ArrayList<>(subset));
generateSubsetsWithDup(result,subset,numsList,idx+1);//在放入第idx元素的基础上,对后续数组进行处理
}
subset.remove(subset.size()-1);//移除idx元素
generateSubsetsWithDup(result,subset,numsList,idx+1);//在不放入第idx元素的基础上,对后续数组进行处理
}
N皇后问题
题目描述
n 皇后问题研究的是如何将 n 个皇后放置在 n×n 的棋盘上,并且使皇后彼此之间不能相互攻击。
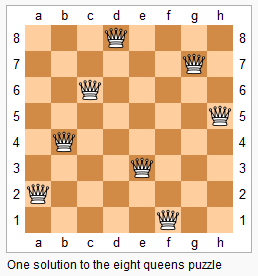
上图为 8 皇后问题的一种解法。
给定一个整数 n,返回所有不同的 n 皇后问题的解决方案。
每一种解法包含一个明确的 n 皇后问题的棋子放置方案,该方案中 ‘Q’ 和 ‘.’ 分别代表了皇后和空位。
示例:
输入: 4
输出: [
[".Q..", // 解法 1
"...Q",
"Q...",
"..Q."],
["..Q.", // 解法 2
"Q...",
"...Q",
".Q.."]
]
解释: 4 皇后问题存在两个不同的解法。
解题思路
对于N*N的棋盘,每行都要放置一个且只能放置一个皇后。利用递归对棋盘每一行放置皇后,放置时按列顺序寻找可放置皇后的列。若可放置皇后则将皇后放置该位置,并更新mark标记数组,递归进行下一行皇后放置。当该次递归结束后,恢复mark数组,并尝试下一个可能放置皇后的列。当递归完成N行的N个皇后放置,则将结果保存并返回。
一次递归完成对第i行皇后的放置。
程序代码
public List<List<String>> solveNQueens2(int n) {
List<List<String>> result = new ArrayList<>();//结果数组,存储所有N皇后摆放结果的集合
List<List> nQueens = new ArrayList<>();//存放某种N皇后摆放的结果
int[][] mark = new int[n][n];//标记棋盘,标记位置是否能拜访皇后的二维数组
//初始化
for(int i=0;i<n;i++) {
List nQueensRow = new ArrayList<>();
for(int j=0;j<n;j++) {
nQueensRow.add(".");
mark[i][j] = 0;
}
nQueens.add(nQueensRow);
}
generateNQueens(0,n,nQueens,mark,result);
return result;
}
public void generateNQueens(int i,int n,List<List> nQueens,int[][] mark,List<List<String>> result){
//表示在第i行放置皇后
if(i==n) {
//将皇后填充完毕(n行皇后均摆放完毕),将N皇后摆放结果加入结果集
List<String> nQueensStr = new ArrayList<>();
for(int j=0;j<nQueens.size();j++) {
List nQueensRow = nQueens.get(j);
String nQueensRowStr = "";
for(int r=0;r<nQueensRow.size();r++)
nQueensRowStr += nQueensRow.get(r);
nQueensStr.add(nQueensRowStr);
}
result.add(nQueensStr);
return;
}
for(int j=0;j<n;j++) {
//标记棋盘第i行若有可放置皇后的位置(mark[i][j]==0),在该位置放置皇后
if(mark[i][j]==0) {
//记录当前的标记棋盘的镜像,用于回溯时恢复之前状态
//采用深复制,保存标记棋盘的数据而非引用(浅复制:保存标记棋盘的引用,同时发生改变)
int[][] tmp_mark = new int[n][n];
for(int r=0;r<n;r++)
for(int s=0;s<n;s++)
tmp_mark[r][s] = mark[r][s];
put_down_the_queen(i,j,mark);//改变标记棋盘
//记录第i行皇后放置位置
List nQueensRow = nQueens.get(i);
nQueensRow.set(j, "Q");
nQueens.set(i, nQueensRow);
generateNQueens(i+1,n,nQueens,mark,result);//在第i+1行放皇后
//回溯,将皇后拿出
mark = tmp_mark;//恢复标记棋盘
//恢复第i行皇后放置位置
nQueensRow.set(j, ".");
nQueens.set(i, nQueensRow);
}
}
}
public void put_down_the_queen(int x,int y,int[][] mark) {
final int dx[] = {-1,1,0,0,-1,-1,1,1};//纵轴方向数组
final int dy[] = {0,0,-1,1,-1,1,-1,1};//横轴方向数组
mark[x][y] = 1;//(x,y)放置皇后,进行标记
//新的位置向8个方向延伸,每个方向向外延伸1到N-1
for(int i=1;i<mark.length;i++) {
for(int j=0;j<8;j++) {
int new_x = x + i*dx[j];
int new_y = y + i*dy[j];
if(new_x >= 0 && new_x < mark.length && new_y >= 0 && new_y < mark.length) {
//检查新位置是否在棋盘内
mark[new_x][new_y] = 1;
}
}
}
}
机器人运动范围
题目描述
地上有一个m行和n列的方格。一个机器人从坐标0,0的格子开始移动,每一次只能向左,右,上,下四个方向移动一格,但是不能进入行坐标和列坐标的数位之和大于k的格子。 例如,当k为18时,机器人能够进入方格(35,37),因为3+5+3+7 = 18。但是,它不能进入方格(35,38),因为3+5+3+8 = 19。请问该机器人能够达到多少个格子?
解题思路
基础的路径问题,采用回溯法解决。对于每个位置,均有四个方向移动。从坐标(0,0)开始移动,因此共有2个选择:向下移动(x+1)或向右移动(y+1)。
若移动后仍位于矩阵内部且满足行坐标与列坐标数位和不大于threshold且该位置是第一次访问,则进行移动并记录坐标位置。并进行下一个位置的选择。
程序代码
public int movingCount(int threshold, int rows, int cols)
{
//根据题设实际要求,若阈值<0,则机器人无法到达任何格子
if(threshold<0)return 0;
//初始化
int[][] result = new int[rows][cols];//标记数组,记录机器人所能到达的所有格子
int sum = 0;
for(int i=0;i<rows;i++)
for(int j=0;j<cols;j++)
result[i][j] = 0;
result[0][0] = 1;
backTraceMovingCount(0,0,result,rows,cols,threshold);//从坐标(0,0)开始移动
for(int i=0;i<rows;i++)
for(int j=0;j<cols;j++)
if(result[i][j]==1)sum++;
return sum;
}
public void backTraceMovingCount(int x,int y,int[][] result,int rows,int cols,int threshold)
{
//从当前坐标(x,y)开始移动,只有2种选择,要么向下移动(y+1)要么向右移动(x+1)
int new_x = x + 1;
int new_y = y + 1;
//如果移动后的新位置
//1.位于矩阵内部
//2.没有走过
//3.数位和
//则进行移动,并记录。之后进行下一位置的选择
if(new_x>=0 && new_x<rows && result[new_x][y]==0 && sum_bit(new_x,y)<=threshold) {
//向下移动
result[new_x][y] = 1;
backTraceMovingCount(new_x,y,result,rows,cols,threshold);//从新坐标(new_x,y)开始移动
}
if(new_y>=0 && new_y<cols && result[x][new_y]==0 && sum_bit(x,new_y)<=threshold) {
//向右移动
result[x][new_y] = 1;
backTraceMovingCount(x,new_y,result,rows,cols,threshold);//从新坐标(x,new_y)开始移动
}
}
public int sum_bit(int x,int y) {
//返回x,y各个位的值的和
int sum = 0;
int _x = x;
int _y = y;
while(_x!=0) {
sum += _x%10;
_x = _x/10;
}
while(_y!=0) {
sum += _y%10;
_y = _y/10;
}
return sum;
}
火柴棍摆正方形
题目描述
还记得童话《卖火柴的小女孩》吗?现在,你知道小女孩有多少根火柴,请找出一种能使用所有火柴拼成一个正方形的方法。不能折断火柴,可以把火柴连接起来,并且每根火柴都要用到。
输入为小女孩拥有火柴的数目,每根火柴用其长度表示。输出即为是否能用所有的火柴拼成正方形。
示例 1:
输入: [1,1,2,2,2]
输出: true
解释: 能拼成一个边长为2的正方形,每边两根火柴。
示例 2:
输入: [3,3,3,3,4]
输出: false
解释: 不能用所有火柴拼成一个正方形。
算法思路
(1)回溯算法
想象正方形的4条边即为4个桶,将每个火柴杆回溯的放置在每个桶中,在放完n个火柴杆后,检查4个桶中的火柴杆长度和是否相同,相同返回真,否则返回假;在回溯过程中,如果当前所有可能向后的回溯,都无法满足条件,即递归函数最终返回假。
(2)回溯算法中优化/剪枝——超时限制
优化1:n个火柴杆的总和对4取余需要为0,否则返回假。
优化2:火柴杆按照从大到小的顺序排序,先尝试大的减少回溯可能。
优化3:每次放置时,每条边上不可放置超过总和的1/4长度的火柴杆
程序代码
public boolean makesquare(int[] nums) {
int[] square = {0,0,0,0}; // square存储各边的所摆火柴棍长度,并初始化正方形四条边所在桶均为0
if(nums == null || sum(nums)==0 || sum(nums)%4!=0)return false; // 数组长度为0 或者 火柴棍无法成为一个正方形
Integer squareLength = sum(nums)/4;
Arrays.sort(nums);
reverse(nums); // 降序排序
boolean result = generateSquare(0,squareLength,nums,square);
return result;
}
public boolean generateSquare(int i, int squareLength, int[] nums, int[] square) {
// 将第i个火柴棍连接
if(i == nums.length) // 已将所有火柴棍摆完,若所有边均满足正方形长度,则可摆成一个正方形
return square[0] == squareLength && square[1] == squareLength && square[2] == squareLength && square[3] == squareLength;
for(int j=0;j<4;j++) { // 将火柴棍逐个加到各个边上
if(square[j] + nums[i] <= squareLength) {
square[j] += nums[i]; // 若长度不够,则将火柴棍添加到该边上
if(generateSquare(i+1, squareLength, nums, square))return true; // 连接第 i+1 个火柴棍
square[j] -= nums[i]; // 回溯,将该火柴棍放在其他边上
}
}
return false; // 该火柴棍没法放在任一一条边上,则返回false,表示该放置方式(路径)错误
}
public int sum(int[] nums) {
int sum = 0;
for(int i=0;i<nums.length;i++)
sum+=nums[i];
return sum;
}
public int[] reverse(int[] nums) {
for(int i=0;i<nums.length/2;i++) {
int temp = nums[i];
nums[i] = nums[nums.length-i-1];
nums[nums.length-i-1] = temp;
}
return nums;
}
(三)分治
分治法(分而治之)就是把一个复杂的问题分成两个或更多的相同或相似的子问题,再把子问题分成更小的子问题……直到最后子问题可以简单的直接求解,原问题的解即子问题的解的合并。也是一种基于递归思想的算法。
- 算法思想
(1)分解:将原问题分解为若干个规模较小,相互独立,与原问题形式相同的子问题。
(2)求解:若子问题划分得规模较小且容易被解决时则直接解决,否则递归求解各个子问题。
(3)合并:将各个子问题的解合并为原问题的解。 - 解题格式
public void divide(int[] arr,int start,int end){
if(start >= end)return;
// 获得分割点
int dividePoint = getDividePoint(start,end);
divide(arr,start,dividePoint); // 递归分割前半部分
divide(arr,dividePoint+1,end); // 递归分割后半部分
merge(arr,start,dividePoint,end); // 合并前半部分后半部分
}
- 典型例题
归并排序
归并排序(MERGE-SORT)是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。
//归并排序的分治---分
private void divide(int[] arr,int start,int end){
//递归的终止条件
if(start >= end)
return;
//计算中间值,注意溢出
int mid = start + (end - start)/2;
//递归分
divide(arr,start,mid);
divide(arr,mid+1,end);
//治
merge(arr,start,mid,end);
}
private void merge(int[] arr,int start,int mid,int end){
int[] temp = new int[end-start+1];
//存一下变量
int i=start,j=mid+1,k=0;
//下面就开始两两进行比较
while(i<=mid && j<=end){
if(arr[i] <= arr[j]){
temp[k++] = arr[i++];
}else{
temp[k++] = arr[j++];
}
}
//各自还有剩余的没比完,直接赋值即可
while(i<=mid)
temp[k++] = arr[i++];
while(j<=end)
temp[k++] = arr[j++];
//覆盖原数组
for (k = 0; k < temp.length; k++)
arr[start + k] = temp[k];
}
}
快速排序
快速排序是指通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
一趟快速排序的算法是:
- 设置两个变量i、j,排序开始的时候:i=0,j=N-1;
- 以第一个数组元素作为关键数据,赋值给key,即key=A[0];
- 从j开始向前搜索,即由后开始向前搜索(j–),找到第一个小于key的值A[j],将A[j]和A[i]的值交换;
- 从i开始向后搜索,即由前开始向后搜索(i++),找到第一个大于key的A[i],将A[i]和A[j]的值交换;
- 重复第3、4步,直到i=j; (3,4步中,没找到符合条件的值,即3中A[j]不小于key,4中A[i]不大于key的时候改变j、i的值,使得j=j-1,i=i+1,直至找到为止。找到符合条件的值,进行交换的时候i, j指针位置不变。另外,i==j这一过程一定正好是i+或j-完成的时候,此时令循环结束)。
public int[] sortArray(int[] nums) {
//对nums进行快排
quickSort(0,nums.length-1,nums);
return nums;
}
public void quickSort(int start,int end,int[] nums) {
//对数组nums[left..right]进行快排
//left指针为数组初始位置的遍历指针,right为数组末端位置的遍历指针
if(start >= end)return;
int key = nums[start];//基准
int left = start; //起始结点
int right = end; //末端结点
while(left<right) {
//从末端指针向前遍历,直到遇到第一个小于基准的值,此时将nums[left]与nums[right]交换
while(nums[right] >= key && left<right)right--;
swapAandB(left,right,nums);
//从首端指针向后遍历,直到遇到第一个大于基准的值,此时将nums[left]与nums[right]交换
while(nums[left] <= key && left<right)left++;
swapAandB(left,right,nums);
}
//一次遍历结束idx(left=right)左边的元素均idx。此时对idx左右的元素分别进行快排
quickSort(start,left-1,nums);
quickSort(left+1,end,nums);
}
public void swapAandB(int a,int b,int[] nums) {
//将nums[a]与nums[b]交换
int tmp = nums[a];
nums[a] = nums[b];
nums[b] = tmp;
}
求数组中的逆序对
题目描述
在数组中的两个数字,如果前面一个数字大于后面的数字,则这两个数字组成一个逆序对。输入一个数组,求出这个数组中的逆序对的总数P。并将P对1000000007取模的结果输出。 即输出P%1000000007
输入描述:
题目保证输入的数组中没有的相同的数字
示例1
输入
1,2,3,4,5,6,7,0
输出
7
解题思路
利用归并排序的思想求逆序数个数。
进行归并排序时,当前一个数组第i个元素>后一个数组第j个元素时,插入后一个数组第j个元素。此时前一个数组的第i个元素之后的所有元素均大于第j个元素,故对应逆序数对有mid-i+1个。
程序代码
int count = 0;//逆序对总数
public int InversePairs(int [] array) {
if(array.length <= 0 || array == null)
return 0;
//通过对数组进行归并排序计算数组中的逆序数对
merge_sort(array,0,array.length-1);
return count;
}
public void merge_sort(int[] nums,int left,int right) {
//对数组nums[left..right]进行归并排序
if(right<=left)return;//数据规模足够小
int mid = (left + right)/2;//取中间值
merge_sort(nums,left,mid);//对子数组nums[left..mid]进行归并排序
merge_sort(nums,mid+1,right);//对子数组nums[mid+1...right]进行归并排序
merge_two_list(nums,left,mid,right);
}
public void merge_two_list(int[] nums,int left,int mid,int right) {
//将两个已排序的数组进行顺序合并nums[left,...,mid][mid+1,...,right]
//逆序数求解算法思路:
//进行归并排序时,插入后一个数组的第j个元素时,该元素相关的逆序数有mid-i+1个(前一个数组第i个元素后的元素均大于第j个元素)
int[] nums_tmp = new int[right-left+1];
int i = left;
int j = mid+1;
int k = 0;
//对数组A和数组B进行遍历,若数组A中元素i<=数组B中元素j,则将元素i加入辅助数组中;若数组A中元素i>数组B中元素j,则将元素j加入辅助数组中。
//此时辅助数组为排好序的数组,用辅助数组覆盖原数组。
while(i<=mid && j<=right) {
if(nums[i]<=nums[j]) {
nums_tmp[k++] = nums[i++];
}else {
nums_tmp[k++] = nums[j++];
//此时两个数组都是已经由小到大排好序了的,所以如果数组A中元素a大于数组B元素b,那么a元素后面的所有元素都大于b,就有mid-i+1个逆序对
count = (count+mid-i+1)%1000000007;
}
}
while(i<=mid) {
nums_tmp[k++] = nums[i++];//将数组A中未遍历完的元素加入辅助数组中
}
while(j<=right) {
nums_tmp[k++] = nums[j++];//将数组B中未遍历完的元素加入辅助数组中,此时数组A中所有元素均遍历完,均小于数组B中未遍历元素。故没有逆序对
}
//用辅助数组覆盖原数组
for(i=left;i<=right;i++)
nums[i] = nums_tmp[i-left];
}
第五章 二叉树 与 图
- 二叉树
树是n(n>=0)个节点的有限集,且这些节点满足如下关系:
有且仅有一个结点没有父结点,这些结点称为树的根。
除根外,其余每个结点都有且近有一个父结点。
树中的每个结点都构成一个以它为根的树。
二叉树满足树的条件时,满足如下条件:
每个结点最多有两个孩子(子树),这两个子树有左右之分,次序不可颠倒。
(1)数据结构
public class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode(int x) { val = x; }
}
(2)遍历
// 1.先序遍历
// 根左右
public void pre_order(Node node){
if(node != null){
system.out.println(node.var);
pre_order(node.left);
pre_order(node.right);
}
}
// 2.中序遍历
// 左根右
public void in_order(Node node){
if(node != null){
pre_order(node.left);
system.out.println(node.var);
pre_order(node.right);
}
}
// 3.后序遍历
// 左右根
public void pre_order(Node node){
if(node != null){
pre_order(node.left);
pre_order(node.right);
system.out.println(node.var);
}
}
// 4.层序遍历
public class Solution {
public ArrayList<Integer> PrintFromTopToBottom(TreeNode root) {
ArrayList<Integer> L1=new ArrayList<Integer>();
Deque<TreeNode> q = new LinkedList<TreeNode>();
// offer()方法是Queue方法,插入到队尾,不成功就返回false
q.offer(root);
while(q.peek()!=null){
// peek()和element()都在不移除的情况下返回队列的头部,peek()在队列为空时返回null,element()
// 则会抛出NoSuchElementExcetion异常。
TreeNode tmp=q.poll();
// poll()和remove()方法移除队列头部,poll()在队列为空的时候返回null,remove返回
// NoSuchElementException异常
L1.add(tmp.val);
if(tmp.left!=null)q.offer(tmp.left);
if(tmp.right!=null)q.offer(tmp.right);
}
return L1;
}
}
二叉树的特性
// 输入一棵二叉树,判断二叉树是否是平衡二叉树
public boolean IsBalanced_Solution(TreeNode root) {
// 二叉排序树树满足IsSearch(root)
// 平衡二叉树满足IsBalanced(root)
if(IsSearchTree(root) && IsBalanced(root))return true;
return false;
}
// 输入一棵二叉树,判断二叉树是否是二叉排序树
public boolean IsSearchTree(TreeNode root) {
// 二叉排序树特性:
// 1. 若它的左子树不空,则左子树上所有节点的值均小于它的根节点的值;
// 2. 若它的右子树不空,则右子树上所有节点的值均大于它的根节点的值;
// 3. 它的所有结点的左右子树也分别为二叉排序树。
if(root!=null) {
if((root.left!=null && root.left.val>=root.val) || (root.right!=null && root.right.val<=root.val))
return false;
if(root.left != null)if(!IsBalanced_Solution(root.left))return false;
if(root.right != null)if(!IsBalanced_Solution(root.right))return false;
}
return true;
}
public boolean IsBalanced(TreeNode root) {
// 高度差满足:
// 每个结点的左子树和右子树的高度差至多等于1
if(root!=null) {
if(Math.abs(getHeight(root.left)-getHeight(root.right))>1)return false;
if(root.left!=null)if(!IsBalanced(root.left))return false;
if(root.right!=null)if(!IsBalanced(root.right))return false;
}
return true;
}
public int getHeight(TreeNode root) {
if(root!=null) {
int left = root.left==null?0:getHeight(root.left);
int right = root.right==null?0:getHeight(root.right);
return left>right?left+1:right+1;
}else return 0;
}
- 图
图(Graph)是由顶点的又穷非空集合和顶点之间的集合组成,通常表示为G(V,E),其中,G表示一个图,V是图G中顶点的集合,E是图G中边的集合。
图分无向图和有向图,根据图的边长,又分带权图与不带权图。
(1)数据结构
// 图结点(带权/不带权)
public class GraphNode{
public Character key;
public List<Character> neighbors;
// 构造
public GraphNode(Character key) {
this.key = key;
this.neighbors = new ArrayList<Character>();
}
}
(2)BFS
//例1 BFS
public List BFS(List graph, GraphNode start){
// 利用BFS遍历图 graph,从任意结点 start 出发
// 通过队列存储中间结点,每次弹出一个结点,并遍历该结点的邻接结点,若该结点未访问,则加入遍历结果列表
// 特别的,对于队列而言,BFS的结果就是队列的层序遍历
List result = new ArrayList<>(); // 存储遍历结果列表
Queue<GraphNode> queue = new LinkedList<>(); // 通过队列存储中间处理数据
//初始化
queue.offer(start); // 初始结点加入队列
result.add(start.key); // 对初始结点进行访问
while(!queue.isEmpty()) {
// 队列不为空时,弹出队首结点,寻找该结点的邻接结点
GraphNode head = queue.poll();
List<neighborNode> neighbors = head.neighbors; // 获取该结点的邻结点
for(int i=0;i<neighbors.size();i++) {
// 对该结点的邻结点进行遍历,若没有访问过,则加入队列
char neighborValue = neighbors.get(i).key;
if(!result.contains(neighborValue)) { // 结果列表中不包含该结点,则对该结点进行访问
queue.offer(findGraphNodeByKey(graph,neighborValue)); // 将该结点加入队列
result.add(neighborValue); // 已访问的结点加入结果列表
}
}
}
return result;
}
(3)单源非加权最短路径(BFS)
//例2 BFS求 单源非加权最短路径
public HashMap ShortestPathWithBFS(List graph, GraphNode start){
// 利用BFS遍历图 graph,从任意结点 start 出发
// 通过队列存储中间结点,每次弹出一个结点,并遍历该结点的邻接结点,若该结点未访问,则加入遍历结果列表
// 遍历结点时,用parent 数组存储该结点的上一个结点。最终可以通过parent结点找到从根节点到各个结点的路径(最短路径)
// 返回值为一个HashMap 记录每一个结点的 key 以及最短路径情况下到达每一个结点的上一个结点的 key
List seen = new ArrayList<>(); // 存储遍历结果列表,即已经访问过的结点
Queue<GraphNode> queue = new LinkedList<>(); // 通过优先队列(默认实现小顶堆),存储中间处理数据
HashMap parent = new HashMap<>(); // parent数组,存储最短路径下遍历到当前结点和该结点的上一个结点,通过parent数组可以通过溯根找到最短路径
//初始化
queue.offer(start); // 初始结点加入队列
seen.add(start.key); // 访问初始结点
parent.put(start.key, null); // 初始结点的上一个结点为null
while(!queue.isEmpty()) {
// 队列不为空时,弹出队首结点,访问该结点的邻接结点
GraphNode head = queue.poll();
List<neighborNode> neighbors = head.neighbors; // 获取该结点的邻结点
for(int i=0;i<neighbors.size();i++) {
// 对该结点的邻结点进行遍历,若没有访问过,则加入队列
char neighborValue = neighbors.get(i).key;
if(!seen.contains(neighborValue)) { // 结果列表中不包含该结点
queue.offer(findGraphNodeByKey(graph,neighborValue)); // 将该结点加入队列
seen.add(neighborValue); // 访问该结点
parent.put(neighborValue,head.key); // 存储该结点的值 与 上一个结点的值
}
}
}
return parent;
}
(4)DFS
//例3 DFS
public List<Integer> DFS(List graph, GraphNode start){
// 利用DFS遍历图 graph,从任意结点 start 出发
// 通过栈存储中间结点,每次弹出一个结点,并遍历该结点的邻接结点,若该结点未访问,则加入遍历结果列表
// 本质就是将BFS中的队列用栈表示
List result = new ArrayList<>(); // 存储遍历结果列表
Stack<GraphNode> stack = new Stack<>(); // 通过队列存储中间处理数据
//初始化
stack.push(start); // 初始结点加入栈
result.add(start.key); // 对初始结点进行访问
while(!stack.isEmpty()) {
// 队列不为空时,弹出队首结点,寻找该结点的邻接结点
GraphNode head = stack.pop();
List<neighborNode> neighbors = head.neighbors; // 获取该结点的邻结点
for(int i=0;i<neighbors.size();i++) {
// 对该结点的邻结点进行遍历,若没有访问过,则加入队列
char neighborValue = neighbors.get(i).key;
if(!result.contains(neighborValue)) { // 结果列表中不包含该结点,则对该结点进行访问
stack.push(findGraphNodeByKey(graph,neighborValue)); // 将该结点加入队列
result.add(neighborValue); // 已访问的结点加入结果列表
}
}
}
return result;
}
(5)单源加权最短路径(Dijkstra)
// 自定义优先队列比较器
// 对图中结点距初始结点的距离进行排序
Comparator<neighborNodeWithDis> cmp = new Comparator<neighborNodeWithDis>() {
public int compare(neighborNodeWithDis node1, neighborNodeWithDis node2) {
//升序排序
return node1.dis - node2.dis;
}
};
void initParent(HashMap parent) {
parent.put('A', null);
parent.put('B', null);
parent.put('C', null);
parent.put('D', null);
parent.put('E', null);
parent.put('F', null);
}
void initDistance(HashMap distance){
distance.put('A', 0);
distance.put('B', 0);
distance.put('C', 0);
distance.put('D', 0);
distance.put('E', 0);
distance.put('F', 0);
}
// 例4 基于BFS求 单源加权最短路径,用Dijkstra算法
public void Dijkstra(List graph, GraphNode start){
// 利用Dijkstra 算法求最短路径。基于BFS算法。
// 利用 result 记录遍历过的结点
// 利用 parent 记录最短路径时遍历结点的上一个结点
// 利用 distance 记录最短路径时从 start 到达各个结点时的最短路径
List result = new ArrayList<>(); // 存储已经处理结束的结点
// 通过优先队列存储中间处理数据
// 优先队列中存储着结点的key 及 当前距离初始结点的距离
Queue<neighborNodeWithDis> queue = new PriorityQueue<>(cmp);
HashMap parent = new HashMap<>(); // parent数组,存储最短路径下遍历到当前结点和该结点的上一个结点,通过parent数组可以通过溯根找到最短路径(实时更新)
HashMap distance = new HashMap<>(); // distance数组,存储最短路径下从根节点遍历到当前结点和该结点的最短路径的距离(实时更新)
//初始化
queue.offer(new neighborNodeWithDis(start.key,0)); // 初始结点加入队列
initParent(parent); //初始化父结点数组
initDistance(distance); //初始化距离数组
while(!queue.isEmpty()) {
// 队列不为空时,弹出队首结点,对该结点进行访问
neighborNodeWithDis headNode = queue.poll();
GraphNode head = findGraphNodeByKey(graph,headNode.key);
result.add(head.key); // 弹出队列,表示该结点已经处理完毕,加入result数组
int currentDis = headNode.dis;
List<neighborNodeWithDis> neighbors = head.neighbors; // 获取该结点的邻结点
for(int i=0;i<neighbors.size();i++) {
// 对该结点的邻结点进行遍历,若没有访问过,则加入队列
neighborNodeWithDis neighborNode = neighbors.get(i);
if(!result.contains(neighborNode.key)) { // 结果列表中不包含该结点
int dis = neighborNode.dis; // 获取邻结点与当前结点的距离
char key = neighborNode.key; // 获取邻结点的key
if(currentDis+dis < (Integer)distance.get(key) || (Integer)distance.get(key)==0) {
// 若当前遍历下到该邻接点的距离梗系啊
queue.offer(new neighborNodeWithDis(key,currentDis+dis)); // 将该结点加入队列
parent.replace(key, head.key); // 存储该结点的值 与 上一个结点的值
distance.replace(key,currentDis+dis); // 存储到初始结点更短的距离
}
}
}
}
System.out.print("A" + " | " + parent.get('A') + " | " + distance.get('A') + "\n");
System.out.print("B" + " | " + parent.get('B') + " | " + distance.get('B') + "\n");
System.out.print("C" + " | " + parent.get('C') + " | " + distance.get('C') + "\n");
System.out.print("D" + " | " + parent.get('D') + " | " + distance.get('D') + "\n");
System.out.print("E" + " | " + parent.get('E') + " | " + distance.get('E') + "\n");
System.out.print("F" + " | " + parent.get('F') + " | " + distance.get('F') + "\n");
}
打印结果
A | null | 0
B | C | 3
C | A | 1
D | B | 4
E | D | 7
F | D | 10
(6)拓扑排序
拓扑排序是对有向无环图的顶点的一种排序,它使得如果存在一条从顶点A到顶点B的路径,那么在排序中B出现在A的后面。经常用于完成有依赖关系的任务的排序。
算法步骤:
- 将所有入度为0的节点加入队列
- 从队列中依次取出节点,并将该节点的边删除(指向的所有顶点入度-1)
- 此时若有顶点入度为0,则添加入队列
- 再重复上述步骤,直到队列为空
- 如果最后所有点的入度均为0,则说明为一个有向无环图,出队顺序即为一个拓扑排序
- 否则有环,无法拓扑排序,原问题无解
课程安排(有向图判断环)
题目描述
现在你总共有 n 门课需要选,记为 0 到 n-1。
在选修某些课程之前需要一些先修课程。 例如,想要学习课程 0 ,你需要先完成课程 1 ,我们用一个匹配来表示他们: [0,1]
给定课程总量以及它们的先决条件,判断是否可能完成所有课程的学习?
示例 1:
输入: 2, [[1,0]]
输出: true
解释: 总共有 2 门课程。学习课程 1 之前,你需要完成课程 0。所以这是可能的。
示例 2:
输入: 2, [[1,0],[0,1]]
输出: false
解释: 总共有 2 门课程。学习课程 1 之前,你需要先完成课程 0;并且学习课程 0 之前,你还应先完成课程 1。这是不可能的。
说明:
输入的先决条件是由边缘列表表示的图形,而不是邻接矩阵。详情请参见图的表示法。
你可以假定输入的先决条件中没有重复的边。
提示:
这个问题相当于查找一个循环是否存在于有向图中。如果存在循环,则不存在拓扑排序,因此不可能选取所有课程进行学习。
解题思路
n个课程,它们之间有m个依赖关系,可以看成顶点个数为n,边个数为m的有向图。
故,若有向图无环,则可以完成全部课程;否则不能,问题转换成构建图,并判断图是否有环。可以用两种方法判断有向图是否有环。
方法1:深度优先搜索
在深度优先搜索时,如果正在搜索某一顶点(还未退出该顶点的递归深度搜索),又回到了该顶点,即证明图有环。
方法2:拓扑排序(宽度优先搜索)
在宽度优先搜索时,只将入度为0的点添加至队列,当完成一个顶点的搜索(从队列取出),他指向的所有顶点入度都减1,若此时某顶点入度为0则添加至队列,若完成宽度搜索后,所有点入度都为0,则图无环,否则有环。
程序代码
public class GraphNode{
int label;
List<GraphNode> neighbors;
GraphNode(int label){
this.label = label;
this.neighbors = new ArrayList<>();
}
}
// 207.课程表
// 现在你总共有 n 门课需要选,记为 0 到 n-1。
// 在选修某些课程之前需要一些先修课程。 例如,想要学习课程 0 ,你需要先完成课程 1 ,我们用一个匹配来表示他们: [0,1]
// 给定课程总量以及它们的先决条件,判断是否可能完成所有课程的学习?
public boolean canFinish(int numCourses, int[][] prerequisites) {
// 通过拓扑排序(BFS)判断是否为有向无环图,若无环则可以完成所有课程;否则不能。
// 在宽度优先搜索时,只将入度为0的点添加至队列。当完成一个顶点的搜索(从队列中取出),
// 它指向的所有顶点入度减1,若此时某顶点入度为0则添加至队列,
// 若完成宽度搜索后,所有点的入度都为0,则图无环,否则有环。
List<GraphNode> graph = new ArrayList<>(); // 构造图的邻接表
int[] degree = new int[numCourses]; // 存储图结点的度
// 构造有向图的邻接表
for(int i=0;i<numCourses;i++) { // 初始化有向图结构,这里结点的label与结点的下标对应
graph.add(new GraphNode(i));
degree[i] = 0;
}
// 根据课程的依赖关系,为图添加邻接关系和度
for(int i=0;i<prerequisites.length;i++) {
// prerequisites中结点:[1,0]表示学习课程1之前,需要学习课程0,因此1是依赖0的。
// 因此有向图中结点0指向结点1。
GraphNode start = graph.get(prerequisites[i][1]);
GraphNode end = graph.get(prerequisites[i][0]);
start.neighbors.add(end); // 首节点指向尾结点
degree[end.label]++; // 尾结点入度+1
}
// BFS 进行拓扑排序
// step1:将入度为0的结点加入队列中
Queue<GraphNode> queue = new LinkedList<>();
for(int i=0;i<numCourses;i++) {
if(degree[i] == 0)queue.offer(graph.get(i));
}
// step2: 进行宽度优先遍历
while(!queue.isEmpty()) {
// step3: 完成一个结点的搜索,从队头取出
GraphNode head = queue.poll();
List<GraphNode> neighbors = head.neighbors;
for(int i=0;i<neighbors.size();i++) {
// step4: 将以搜索完毕的结点为首的尾结点入度-1,若该结点的入度为0,则加入队列中
GraphNode neighbor = neighbors.get(i);
degree[neighbor.label]--;
if(degree[neighbor.label]==0)
queue.offer(neighbor);
}
}
//step5: 遍历结束,所有点的入度都为0,则图无环,否则有环。
for(int i=0;i<numCourses;i++)
if(degree[i]!=0)return false;
return true;
}
- 典型例题
重建二叉树
题目描述
输入某二叉树的前序遍历和中序遍历的结果,请重建出该二叉树。假设输入的前序遍历和中序遍历的结果中都不含重复的数字。例如输入前序遍历序列{1,2,4,7,3,5,6,8}和中序遍历序列{4,7,2,1,5,3,8,6},则重建二叉树并返回。
算法思路
前序遍历的第一个值为根节点的值,使用这个值将中序遍历结果分成两部分,左部分为树的左子树中序遍历结果,右部分为树的右子树中序遍历的结果。
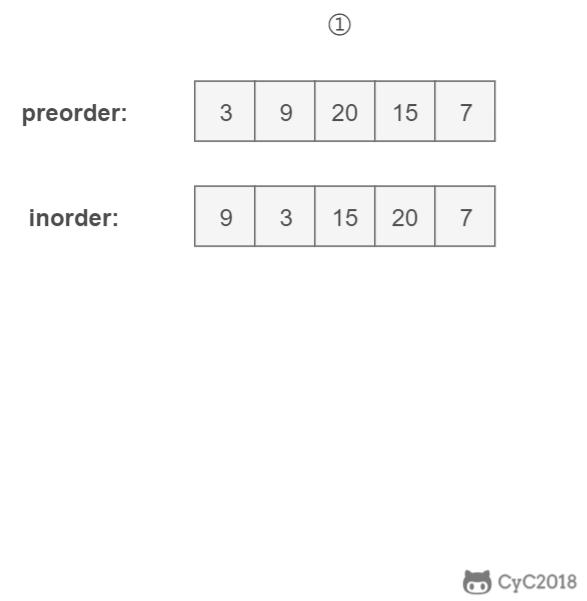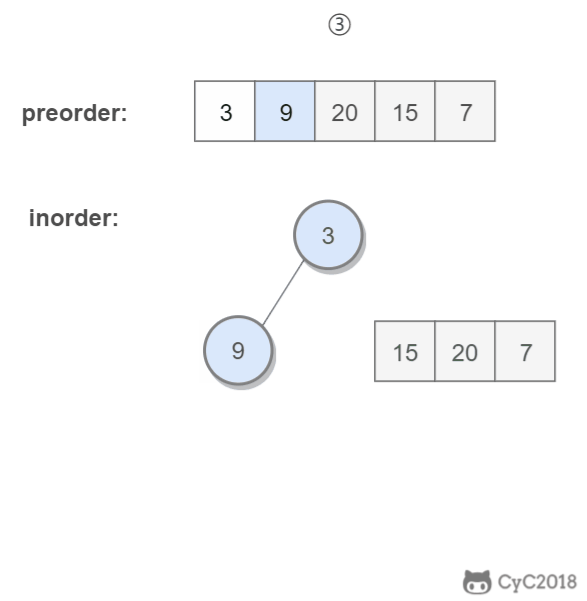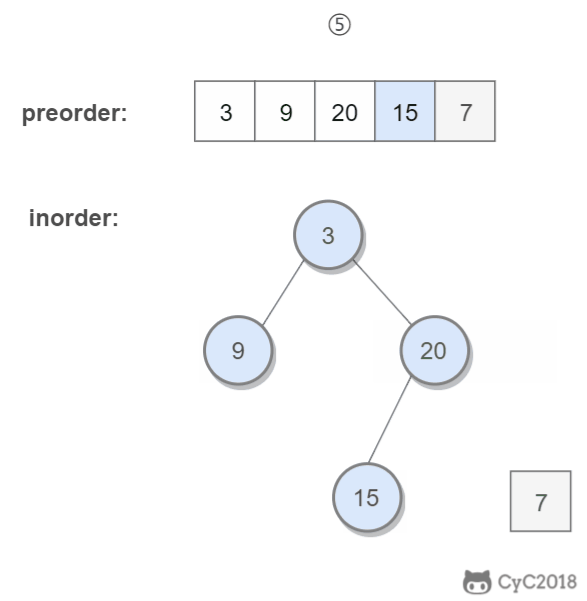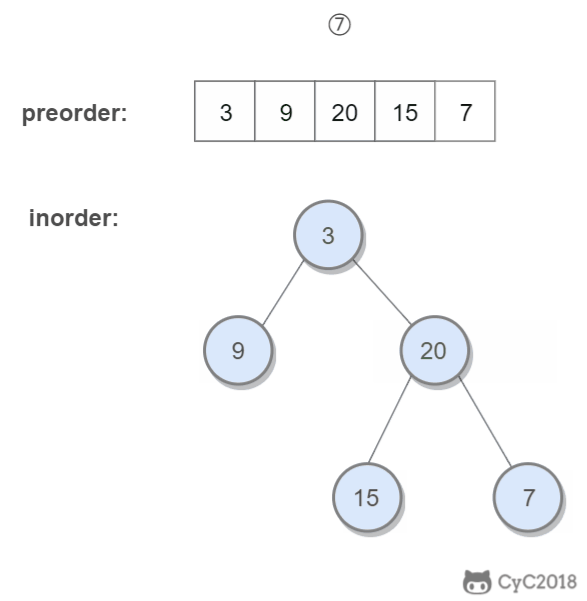
程序代码
public TreeNode reConstructBinaryTree(int [] pre,int [] in) {
if(pre == null || in == null || pre.length == 0 || in.length == 0 || pre.length != in.length)return null;
TreeNode root = ConstructBinaryTreeByPreAndInOrder(pre ,in ,0 ,pre.length-1 ,0 ,in.length-1 );
return root;
}
public TreeNode ConstructBinaryTreeByPreAndInOrder(int[] pre,int[] in, int pre_start, int pre_end, int in_start, int in_end) {
// 根据 pre[pre_start...pre_end] 与 in[in_start...in_end] 构造 二叉树
if(pre_start > pre_end || in_start > in_end)return null;
int node = pre[pre_start]; // 当前结点
// 1. 构造根节点(先序序列的头结点构造根节点)
TreeNode root_node = new TreeNode(node);
// 找到中序遍历的中间结点in_idx
int in_idx = in_start;
for(int i=in_start;i<=in_end;i++)
if(in[i] == node)in_idx = i;
// 2. 构造左子树
// 用中序结点中间结点左边的元素 in[in_start...in_idx-1] 及 先序结点对应元素 构造左子树
root_node.left = ConstructBinaryTreeByPreAndInOrder(pre, in, pre_start+1, pre_start+in_idx-in_start, in_start,in_idx-1);
// 3. 构造右子树
// 用中序结点中间结点右边的元素 in[in_idx+1...in_end] 及 先序结点对应元素 构造右子树
root_node.right = ConstructBinaryTreeByPreAndInOrder(pre, in, pre_end-in_end+in_idx+1, pre_end, in_idx + 1, in_end);
return root_node;
}
二叉树中和为某一值的路径
题目描述
输入一颗二叉树的根节点和一个整数,打印出二叉树中结点值的和为输入整数的所有路径。路径定义为从树的根结点开始往下一直到叶结点所经过的结点形成一条路径。(注意: 在返回值的list中,数组长度大的数组靠前)
程序代码
// 24. 二叉树中和为某一值的路径
//输入一颗二叉树的跟节点和一个整数,打印出二叉树中结点值的和为输入整数的所有路径。
//路径定义为从树的根结点开始往下一直到叶结点所经过的结点形成一条路径。(注意: 在返回值的list中,数组长度大的数组靠前)
public ArrayList<ArrayList<Integer>> result = new ArrayList<ArrayList<Integer>>();
public ArrayList<ArrayList<Integer>> FindPath(TreeNode root,int target) {
// 对二叉树进行DFS
if(root != null)
isPathSatisfy(root,target,0,new ArrayList<Integer>()); // DFS遍历二叉树
Collections.sort(result, listComparator); // 路径集合对路径的长度按降序排序
return result;
}
public void isPathSatisfy(TreeNode node, int target, int pathSum, ArrayList<Integer> pathList) {
// DFS遍历二叉树
// 若遍历到叶子节点且满足此时路径总和 == target,则加入结果序列
// 否则继续遍历左右子树
// * 每次遍历对现场处理 => 该状态节点遍历结束后需弹栈,恢复状态前现场
if(node == null)return;
pathSum += node.val;
pathList.add(node.val);
if(node.left == null && node.right == null && pathSum == target) {result.add(pathList);return;}
if(node.left != null)isPathSatisfy(node.left, target, pathSum,new ArrayList<Integer>(pathList));
if(node.right != null)isPathSatisfy(node.right, target, pathSum,new ArrayList<Integer>(pathList));
pathSum -= node.val;
pathList.remove(pathList.size()-1);
}
public static Comparator listComparator = new Comparator() {
// 比较器,ArrayList中的路径按路径长度排序
@Override
public int compare(Object o1, Object o2) {
// TODO Auto-generated method stub
return ((ArrayList)o2).size() - ((ArrayList)o1).size();
}
};
二叉树下一个节点
题目描述
给定一个二叉树和其中的一个结点,请找出中序遍历顺序的下一个结点并且返回。注意,树中的结点不仅包含左右子结点,同时包含指向父结点的指针。
解题思路

结合图,我们可发现分成两大类:1、有右子树的,那么下个结点就是右子树最左边的点;(eg:D,B,E,A,C,G) 2、没有右子树的,也可以分成两类,a)是父节点左孩子(eg:N,I,L) ,那么父节点就是下一个节点 ; b)是父节点的右孩子(eg:H,J,K,M)找他的父节点的父节点的父节点…直到当前结点是其父节点的左孩子位置。如果没有eg:M,那么他就是尾节点。
程序代码
// 56. 二叉树的下一个节点
// 给定一个二叉树和其中的一个结点,请找出中序遍历顺序的下一个结点并且返回。
// 注意,树中的结点不仅包含左右子结点,同时包含指向父结点的指针。
public class TreeLinkNode {
int val;
TreeLinkNode left = null;
TreeLinkNode right = null;
TreeLinkNode next = null;
TreeLinkNode(int val) {
this.val = val;
}
}
public TreeLinkNode GetNext(TreeLinkNode pNode)
{
if(pNode == null)return null;
if(pNode.right!=null)return getLeftLeaf(pNode.right);
else if(pNode.left!=null)return pNode.next;
else {
TreeLinkNode parent = pNode.next;
while(parent != null) {
if(parent.left == pNode)return parent;
else {
pNode = parent;
parent = pNode.next;
}
}
return null;
}
}
public TreeLinkNode getLeftLeaf(TreeLinkNode node) {
// 获取节点node的最左节点
// 1. 如果有左子树,则下一个节点为左子树的最左值
// 2. 否则,如果有右子树,则下一个节点为右子树的最左值
while(node.left!=null)node = node.left;
return node;
}
对称的二叉树
题目描述
请实现一个函数,用来判断一颗二叉树是不是对称的。注意,如果一个二叉树同此二叉树的镜像是同样的,定义其为对称的。
程序代码
// 57. 对称的二叉树
// 请实现一个函数,用来判断一颗二叉树是不是对称的。
// 注意,如果一个二叉树同此二叉树的镜像是同样的,定义其为对称的。
boolean isSymmetrical(TreeNode pRoot)
{
// 从根节点依次向下递归判断
// 保证左子树的左子树 = 右子树的右子树
// 左子树的右子树 = 右子树的左子树
if(pRoot == null)return true;
else return isNodeSymmetrical(pRoot.left,pRoot.right);
}
public boolean isNodeSymmetrical(TreeNode leftNode,TreeNode rightNode) {
if(leftNode == null)return rightNode == null;
if(rightNode == null)return leftNode == null;
if(leftNode.val != rightNode.val)return false;
if(!(isNodeSymmetrical(leftNode.left,rightNode.right) && isNodeSymmetrical(leftNode.right,rightNode.left)))return false;
return true;
}
按之字形顺序打印二叉树
题目描述
请实现一个函数按照之字形打印二叉树,即第一行按照从左到右的顺序打印,第二层按照从右至左的顺序打印,第三行按照从左到右的顺序打印,其他行以此类推。
程序代码
// 58.按之字形顺序打印二叉树
// 请实现一个函数按照之字形打印二叉树,
// 即第一行按照从左到右的顺序打印,第二层按照从右至左的顺序打印,第三行按照从左到右的顺序打印,其他行以此类推。
public ArrayList<ArrayList<Integer> > Print(TreeNode pRoot) {
// 1. 层序遍历各个节点,记录当前行的最右节点
// 2. 若当前遍历节点为最右节点,则换行操作
// 3. 按之字形顺序打印,故若为偶数行,则打印时需逆序打印
Queue<TreeNode> queue = new LinkedList<TreeNode>(); // 定义队列,用于层序遍历
Integer row = 1; // 记录当前遍历二叉树的层数
TreeNode lastNodeOfRow = pRoot; // 记录当前行的最右节点
TreeNode lastNodeOfNextRow = pRoot; // 记录下一行可能的最右节点
ArrayList<ArrayList<Integer>> result = new ArrayList<ArrayList<Integer>>(); // 结果数组
ArrayList<Integer> rowList = new ArrayList<Integer>();
if(pRoot == null)return result;
queue.offer(pRoot);
while(!queue.isEmpty()) {
TreeNode node = queue.poll();
rowList.add(node.val);
// 每次加入左右节点,均为下一行可能的最右节点(最后一个加入的节点即为最右节点)
if(node.left!=null) {queue.offer(node.left);lastNodeOfNextRow = node.left;}
if(node.right!=null) {queue.offer(node.right);lastNodeOfNextRow = node.right;}
if(node == lastNodeOfRow) {
// 如果该节点为当前行的最后节点,换行的各种操作
if(row % 2 == 0) reverseList(rowList); // 偶数行,则转置
result.add(rowList); // 将该行的结果加入结果集
row++; // 行数+1,定义新行数
rowList = new ArrayList<Integer>();
lastNodeOfRow = lastNodeOfNextRow; // 换行后该行的最右节点
}
}
return result;
}
public void reverseList(List list) {
for(int i=0;i<list.size()/2;i++)
{
Object temp = list.get(i);
list.set(i, list.get(list.size()-1-i));
list.set(list.size()-1-i, temp);
}
}
第六章 二分查找与二叉排序树
- 基础知识
(一)二分查找
二分查找又称折半查找,首先假设表中元素是按升序排列,将表中间位置的关键字与查找关键字比较:
如果两者相等,则查找成功;
否则利用中间位置将表分成前、后两个子表:
(1)如果中间位置的关键字大于查找关键字,则进一步查找前一子表
(2)否则进一步查找后一子表
重复以上过程,直到找到满足条件的记录,即查找成功,或直到子表不存在为止,此时查找不成功。
代码:
// 二分查找(递归)
public boolean binary_search(int[] sort_array, int begin, int end, int target) {
// 搜索target到返回true,否则返回false
// begin和end为待搜索区间左端,右端
if(begin>end)return false; // 区间不存在
int mid = (begin+end)/2; //找中点
if(target == sort_array[mid])return true; //找到target
else if(target < sort_array[mid])
return binary_search(sort_array,begin,mid-1,target);
else
return binary_search(sort_array,mid+1,end,target);
}
// 二分查找(循环)
public boolean binary_search2(int[] sort_array, int target) {
int begin = 0;
int end = sort_array.length-1;
while(begin<=end) {
int mid = (begin+end)/2;
if(target == sort_array[mid])return true;
else if(target<sort_array[mid]) {
end = mid - 1;
}else if(target>sort_array[mid]) {
begin = mid + 1;
}
}
return false;
}
(二)二叉排序树
- 数据结构
二叉查找树,它是一棵具有下列性质的二叉树:
若左子树不空,则左子树上所有结点的值均小于或等于它的根节点的值;
若右子树不空,则左子树上所有结点的值均大于或等于它的根节点的值;
左、右子树也分别为二叉排序树;
等于的情况只能出现在左子树或右子树的某一侧;
class TreeNode{
int value;
TreeNode left;
TreeNode right;
TreeNode(int value){
this.value = value;
left = null;
right = null;
}
}
- 查找
查找数值value是否在二叉查找树中出现:
如果value等于当前查看node的节点值,返回真
如果value节点值小于当前node节点值:
如果当前结点有左子树,继续在左子树中查找该值;否则,返回假
否则(如果value节点值大于当前node节点值:)
如果当前结点有右子树,继续在右子树中查找该值;否则,返回假
// 二叉查找树查找数值
boolean BST_search(TreeNode node,int value) {
if(node.value == value)return true; // 当前结点就是value,返回真
if(node.value > value) {
// 当前node结点值大于value
if(node.left != null)return BST_search(node.left,value); // node结点有左子树,继续搜索左子树
else return false;
}else {
if(node.right != null)return BST_search(node.right,value); // node结点有右子树,继续搜索右子树
else return false;
}
}
- 插入节点
将某结点(insert_node)插入至以node为根的二叉查找树中:
如果insert_node节点值小于当前node节点值:
如果node有左子树,则递归的将该结点插入至左子树为根二叉排序树中
否则,将node->left赋值为该结点地址
否则(如果insert_node节点值大于等于当前node节点值:)
如果node有左子树,则递归的将该结点插入至左子树为根二叉排序树中
否则,将node->left赋值为该结点地址
// 二叉查找树插入数值
void BST_insert(TreeNode node, TreeNode insert_node) {
if(insert_node.value < node.value) {
if(node.left != null)
BST_insert(node.left,insert_node); // 左子树不为空,递归将insert_node插入左子树
else
node.left = insert_node; // 左子树为空时,将node左指针与待插入结点相连
}
else {
if(node.right!=null)
BST_insert(node.right,insert_node); // 右子树不为空,递归将insert_node插入右子树
else
node.right = insert_node;// 右子树为空时,将node右指针与待插入结点相连
}
}
-
二叉树中序遍历为升序数列
-
典型例题
旋转数组的最小值
题目描述
把一个数组最开始的若干个元素搬到数组的末尾,我们称之为数组的旋转。
输入一个非递减排序的数组的一个旋转,输出旋转数组的最小元素。
例如数组{3,4,5,1,2}为{1,2,3,4,5}的一个旋转,该数组的最小值为1。
NOTE:给出的所有元素都大于0,若数组大小为0,请返回0。
程序代码
public int minNumberInRotateArray(int [] array) {
if(array == null || array.length == 0)return 0;
return getMinFromArray(array,0,array.length-1);
}
public int getMinFromArray(int[] array,int start,int end) {
//使用二分查找从旋转数组 array[start..end]中选取最小值
if(start == end) return array[start];
int mid = (start + end)/2;
int left_min = 0; // 数组左端最小值
int right_min = 0; // 数组右端最小值
// 获取数组左端最小值
if(array[start]<=array[mid])left_min = array[start]; // array[start..mid]为递增序列,返回最小值array[start]
else left_min = getMinFromArray(array,start,mid); // array[start..mid]为旋转数组
// 获取数组右端最小值
if(array[mid+1]<=array[end])right_min = array[mid+1]; // array[mid+1..end]为递增序列,返回最小值array[mid+1]
else right_min = getMinFromArray(array,mid+1,end); // array[mid+1..end]为旋转数组
return Integer.min(left_min, right_min);
}
判断数组是否为二叉搜索树后续遍历序列
题目描述
输入一个整数数组,判断该数组是不是某二叉搜索树的后序遍历的结果。如果是则输出Yes,否则输出No。假设输入的数组的任意两个数字都互不相同。
程序代码
public boolean VerifySquenceOfBST(int [] sequence) {
/*基本知识储备:
* 二叉搜索树:左子树<根<右子树+后续遍历:左右根
* 思想:BST的后序序列的合法序列是,对于一个序列S,最后一个元素是x (也就是根),如果去掉最后一个元素的序列为T,那么T满足:
* T可以分成两段,前一段(左子树)小于x,后一段(右子树)大于x,且这两段(子树)都是合法的后序序列。
*/
if(sequence.length==0)return false;
return judge(sequence,0,sequence.length-1);
}
public boolean judge(int[] sequence,int start,int end) {
// 判断sequence[start..end]是否为后序遍历序列
// 只要有一个子树不满足后序遍历条件,即非后序遍历序列
if(start >= end)return true;
int key = sequence[end]; // 二叉搜索树根节点
int i = end - 1; // 二叉搜索树的遍历指针
int mid = end-1; // 二叉搜索树左右子树分隔节点
for(;i>=0;i--) if(sequence[i]<key) {mid=i;break;}
for(;i>=0;i--) if(sequence[i]>=key) return false; // 若左子树值大于根节点,则不是二叉搜索树
if(!judge(sequence,start,mid))return false; // 若左子树不满足二叉搜索树,则非二叉搜索树
if(!judge(sequence,mid+1,end-1))return false; // 若右子树不满足二叉搜索树,则非二叉搜索树
return true;
}
求二叉搜索树中第k小的节点
题目描述
给定一棵二叉搜索树,请找出其中的第k小的结点。例如, (5,3,7,2,4,6,8) 中,按结点数值大小顺序第三小结点的值为4。
程序代码
// 61. 二叉搜索树第k个节点
// 给定一棵二叉搜索树,请找出其中的第k小的结点。
// 例如, (5,3,7,2,4,6,8)中,按结点数值大小顺序第三小结点的值为4。
ArrayList<TreeNode> sortList = new ArrayList<TreeNode>();
Integer nodeNumber = 0;
TreeNode KthNode(TreeNode pRoot, int k)
{
// 利用二叉搜索树的性质:
// 中序遍历结果为从小到大的顺序序列
constructSortList(pRoot);
if(k<=0 || k>nodeNumber) return null; // 不合法
return sortList.get(k-1);
}
public void constructSortList(TreeNode node) {
if(node!=null) {
constructSortList(node.left);
sortList.add(node);
nodeNumber++;
constructSortList(node.right);
}
}
第七章 哈希表与字符串
-
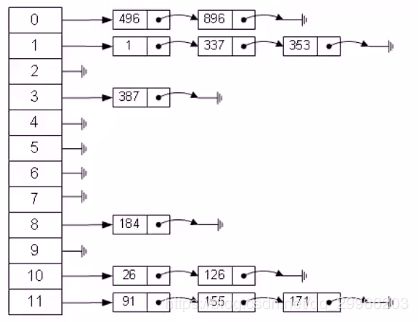
哈希表 基础知识
哈希表(Hash table,也叫散列表),是根据关键字(key)直接进行访问的数据结构,它通过把关键值映射到表中一个位置(数组下标)来直接访问,以加快查找关键值的速度。这个映射函数叫做哈希(散列)函数,存放记录的数组叫做哈希(散列)表。
给定表(M),存在函数f(key),对任意的关键值key,代入函数后若能得到包含该关键字的表中地址,称表M为哈希表,函数f(key)为哈希函数。
-
最简单的哈希——字符哈希
int main(){
// ASCII码,从0~127,故使用数组下标做映射,最大范围至128
int char_map[128] = {0};
string str = "abcdefgaaxxy";
// 统计字符串中,各个字符的数量。若char_map['a']++;即char_map[97]++;
for(int i=0;i<str.length();i++)char_map[str[i]]++;
for(int i=0;i<128;i++)
if(char_map[i]>0)
printf("[%c][%d] : %d\n", i, i, char_map[i]);
return 0;
}
- Hash表的实现
问题引入1:任意元素的映射
解决:利用哈希函数
将关键值(大整数、字符串、浮点数等)转化为整数再对表长取余,从而关键字值被转换为哈希表的表长范围内的整数。
问题引入2:不同整数或字符串,由于哈希函数的选择,映射到同一个下标,发生冲突
解决:拉链法解决冲突
将所有哈希函数结果相同的结点连接在同一个单链表中。
若选定的哈希表长度为m,则可将哈希表定义为一个长度为m的指针数组t[0…m-1],指针数组中的每个指针指向哈希函数结果相同的单链表。
插入value:
将元素value插入哈希表,若元素value的哈希函数值为hash_key,将value对应的结点以头插法的方式插入到以t[hash_key]为头指针的单链表中。
查找value:
若元素value的哈希函数值为hash_key,遍历以t[hash_key]为头指针的单链表,查找链表各个结点的值域是否为value。
public class HashNode{
// Hash表数据结构为单链表构成的数组
int val;
HashNode next;
HashNode(int x){
val = x;
next = null;
}
}
int hash_func(int key,int table_len) {
// 整数哈希函数:直接对表长取余。获得表长范围内的正整数。
return key % table_len;
}
void insert(HashNode[] hash_table, HashNode node, int table_len) {
// 向哈希表中插入元素,采用头插法
int hash_key = hash_func(node.val, table_len);
node.next = hash_table[hash_key].next;
hash_table[hash_key].next = node;
}
boolean search(HashNode[] hash_table, int value, int table_len) {
// 从哈希表中查找元素,遍历哈希值对应的单链表
int hash_key = hash_func(value, table_len);
HashNode head = hash_table[hash_key].next;
while(head != null) {
if(head.val == value)return true;
head = head.next;
}
return false;
}
- HashMap 基本使用
- 基本方法
- 遍历
(1)将Map中所有的键装到Set集合中返回
//public Set keySet();
Set set=map. keySet()
(2)返回集合中所有的value的值的集合
// public Collection values();
Collection c=map.values()
(3)将每个键值对封装到一个个Entry对象中,再把所有Entry的对象封装到Set集合中返回
// public Set
Set
HashMap<String,Integer> map =new HashMap<>();
map.put("a", 1);
map.put("b", 2);
map.put("c", 3);
map.put("d", 4);
// 遍历方法1——将Map中所有的键装到Set集合中返回
Iterator<String> iterator = map.keySet().iterator();
while (iterator.hasNext()) {
Object key = iterator.next();
System.out.println("map.get(key) is :"+map.get(key));
}
// 遍历方法2——将每个键值对封装到一个个Entry对象中,再把所有Entry对象封装到Set集合中返回
Set<Map.Entry<String, Integer>> set=map.entrySet();
Iterator<Map.Entry<String, Integer>> it=set.iterator();
while(it.hasNext()){
//System.out.println(list.get(0) );
Map.Entry<String, Integer> e=it.next();
System.out.println(e.getKey()+":"+e.getValue());
}
- 滑动窗口(Sliding Window)解决字符串匹配
滑动窗口算法的思路是这样:
- 我们在字符串 S 中使用双指针中的左右指针技巧,初始化 left = right = 0,把索引闭区间 [left, right] 称为一个「窗口」。
- 我们先不断地增加 right 指针扩大窗口 [left, right],直到窗口中的字符串符合要求。
- 此时,我们停止增加 right,转而不断增加 left 指针缩小窗口 [left, right],直到窗口中的字符串不再符合要求。同时,每次增加 left,我们都要更新一轮结果。
上述过程可以简单地写出如下伪码框架:
int left = 0, right = 0;
while (right < s.size()) {
window.add(s[right]);
right++;
while (valid) {
window.remove(s[left]);
left++;
}
}
无重复字符的最长子串
题目描述
给定一个字符串,请你找出其中不含有重复字符的 最长子串 的长度。
示例 1:
输入: "abcabcbb"
输出: 3
解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。
算法思路
遇到子串问题,首先想到的就是滑动窗口技巧。
类似之前的思路,使用 window 作为计数器记录窗口中的字符出现次数,然后先向右移动 right,当 window 中出现重复字符时,开始移动 left 缩小窗口,如此往复:
程序代码
int lengthOfLongestSubstring(string s) {
int left = 0, right = 0;
unordered_map<char, int> window;
int res = 0; // 记录最长长度
while (right < s.size()) {
char c1 = s[right];
window[c1]++;
right++;
// 如果 window 中出现重复字符
// 开始移动 left 缩小窗口
while (window[c1] > 1) {
char c2 = s[left];
window[c2]--;
left++;
}
res = max(res, right - left);
}
return res;
}
最小窗口子串
题目描述
给你一个字符串 S、一个字符串 T,请在字符串 S 里面找出:包含 T 所有字母的最小子串。
示例:
输入: S = "ADOBECODEBANC", T = "ABC"
输出: "BANC"
说明:
如果 S 中不存这样的子串,则返回空字符串 “”。
如果 S 中存在这样的子串,我们保证它是唯一的答案。
题目不难理解,就是说要在 S(source) 中找到包含 T(target) 中全部字母的一个子串,顺序无所谓,但这个子串一定是所有可能子串中最短的。
如果我们使用暴力解法,代码大概是这样的:
for (int i = 0; i < s.size(); i++)
for (int j = i + 1; j < s.size(); j++)
if s[i:j] 包含 t 的所有字母:
更新答案
思路很直接吧,但是显然,这个算法的复杂度肯定大于 O(N^2)了,不好。
滑动窗口算法的思路是这样:
-
我们在字符串 S 中使用双指针中的左右指针技巧,初始化 left = right = 0,把索引闭区间 [left, right] 称为一个「窗口」。
-
我们先不断地增加 right 指针扩大窗口 [left, right],直到窗口中的字符串符合要求(包含了 T 中的所有字符)。
-
此时,我们停止增加 right,转而不断增加 left 指针缩小窗口 [left, right],直到窗口中的字符串不再符合要求(不包含 T 中的所有字符了)。同时,每次增加 left,我们都要更新一轮结果。
-
重复第 2 和第 3 步,直到 right 到达字符串 S 的尽头。
这个思路其实也不难,第 2 步相当于在寻找一个「可行解」,然后第 3 步在优化这个「可行解」,最终找到最优解。左右指针轮流前进,窗口大小增增减减,窗口不断向右滑动。
下面画图理解一下,needs 和 window 相当于计数器,分别记录 T 中字符出现次数和窗口中的相应字符的出现次数。
初始状态:
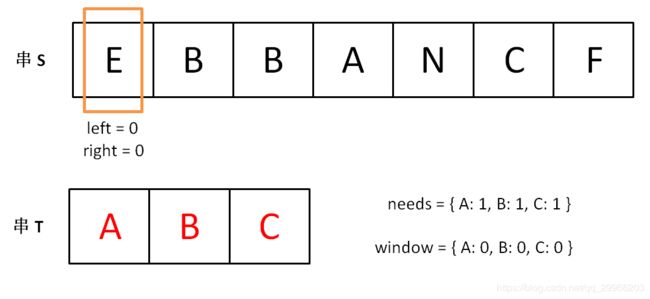 增加 right,直到窗口 [left, right] 包含了 T 中所有字符:
增加 right,直到窗口 [left, right] 包含了 T 中所有字符:
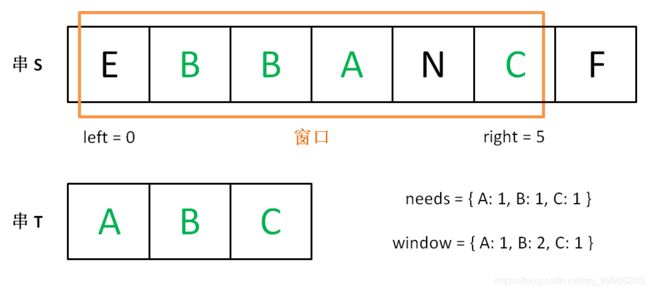
现在开始增加 left,缩小窗口 [left, right]。
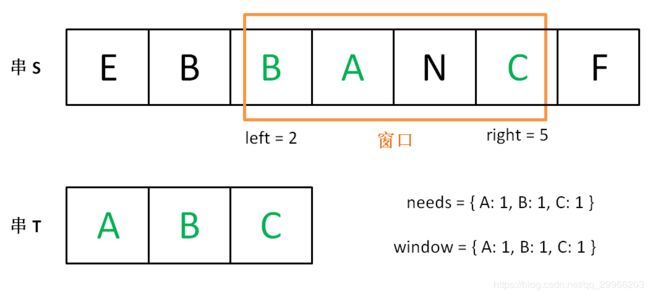
直到窗口中的字符串不再符合要求,left 不再继续移动。
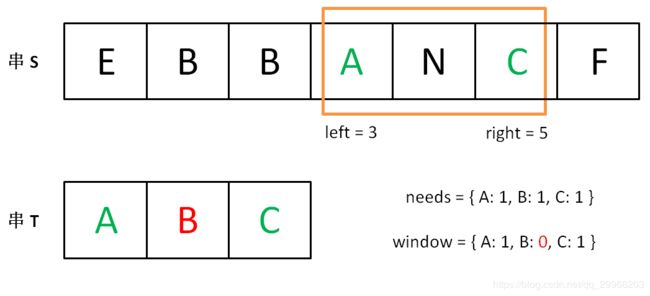
之后重复上述过程,先移动 right,再移动 left…… 直到 right 指针到达字符串 S 的末端,算法结束。
如果你能够理解上述过程,恭喜,你已经完全掌握了滑动窗口算法思想。至于如何具体到问题,如何得出此题的答案,都是编程问题,等会提供一套模板,理解一下就会了。
上述过程可以简单地写出如下伪码框架:
string s, t;
// 在 s 中寻找 t 的「最小覆盖子串」
int left = 0, right = 0;
string res = s;
while(right < s.size()) {
window.add(s[right]);
right++;
// 如果符合要求,移动 left 缩小窗口
while (window 符合要求) {
// 如果这个窗口的子串更短,则更新 res
res = minLen(res, window);
window.remove(s[left]);
left++;
}
}
return res;
程序代码
string minWindow(string s, string t) {
// 记录最短子串的开始位置和长度
int start = 0, minLen = INT_MAX;
int left = 0, right = 0;
unordered_map<char, int> window;
unordered_map<char, int> needs;
for (char c : t) needs[c]++;
int match = 0;
while (right < s.size()) {
char c1 = s[right];
if (needs.count(c1)) {
window[c1]++;
if (window[c1] == needs[c1])
match++;
}
right++;
while (match == needs.size()) {
if (right - left < minLen) {
// 更新最小子串的位置和长度
start = left;
minLen = right - left;
}
char c2 = s[left];
if (needs.count(c2)) {
window[c2]--;
if (window[c2] < needs[c2])
match--;
}
left++;
}
}
return minLen == INT_MAX ?
"" : s.substr(start, minLen);
}
- 典型例题
词语模式
题目描述
给定一种规律 pattern 和一个字符串 str ,判断 str 是否遵循相同的规律。
这里的 遵循 指完全匹配,例如, pattern 里的每个字母和字符串 str 中的每个非空单词之间存在着双向连接的对应规律。
示例1:
输入: pattern = "abba", str = "dog cat cat dog"
输出: true
示例 2:
输入:pattern = "abba", str = "dog cat cat fish"
输出: false
解题思路
匹配:字符串str中的单词与pattern中地字符一一对应(一一遍历,一一比较)
结论:
(1)当拆解出一个单词时,若该单词已出现,则当前单词对应的pattern字符必为该单词曾经对应地pattern字符。
(2)当拆解出一个单词时,若该单词未曾出现,则当前单词对应的pattern字符也必须未曾出现。
(3)单词的个数与pattern字符串中字符数量相同
算法思路:
- 设置单词(字符串)到pattern字符的映射(哈希);使用数组used[128]记录pattern字符是否使用。
- 遍历str,按照空格拆分单词,同时对应的向前移动指向pattern字符的指针,每拆分出一个单词,判断
如果该单词从未出现在哈希表中:
如果当前的pattern字符已被使用,返回false
将单词与当前指向pattern字符做映射;标记当前指向pattern字符已使用
否则:
如果当前单词在哈希表中的映射字符不是当前指向的pattern字符,则返回false - 若单词个数与pattern字符个数不符,则返回false
程序代码
public boolean wordPattern(String pattern, String str) {
// 匹配:字符串str中的单词与pattern中地字符一一对应(一一遍历,一一比较)
// 结论:
//(1)当拆解出一个单词时,若该单词已出现,则当前单词对应的pattern字符必为该单词曾经对应地pattern字符。
//(2)当拆解出一个单词时,若该单词未曾出现,则当前单词对应的pattern字符也必须未曾出现。
//(3)单词的个数与pattern字符串中字符数量相同
// 算法思路:
// 1.设置单词(字符串)到pattern字符的映射(哈希);使用数组used[128]记录pattern字符是否使用。
// 2.遍历str,按照空格拆分单词,同时对应的向前移动指向pattern字符的指针,每拆分出一个单词,判断
// 如果该单词从未出现在哈希表中:
// 如果当前的pattern字符已被使用,返回false
// 将单词与当前指向pattern字符做映射;标记当前指向pattern字符已使用
// 否则:
// 如果当前单词在哈希表中的映射字符不是当前指向的pattern字符,则返回false
// 3.若单词个数与pattern字符个数不符,则返回false
HashMap<String, Integer> hash_table = new HashMap<String, Integer>(); // 定义一个哈希表,存储单词对应的模式字符
boolean[] used = new boolean[128]; // 定义used数组,表示各模式字符是否被使用过,初始化均未使用
for(int i=0; i<128; i++)used[i] = false;
String[] str_list = str.split(" "); // 将字符串拆分为单词数组
if(str_list.length != pattern.length())return false; // 情况1:如果模式串长度与单词数组长度不同,则不匹配
for(int i=0;i<str_list.length;i++) {
String cur_str = str_list[i];
int cur_pattern = pattern.charAt(i);
if(hash_table.containsKey(cur_str)) {
// 若单词出现在哈希表中,则该单词对应的模式字符一定为之前存储在哈希表中的模式字符
// 情况2:模式字符串中对应字符 与 哈希表存储模式字符 不同,则不匹配
if(hash_table.get(cur_str) != cur_pattern)return false;
}else {
// 若该单词从未出现在哈希表中,说明是一个新单词。该单词对应的模式为一个新字符
// 情况3:若未使用过的字符 出现在 used表中(向前遍历pattern已使用),则不匹配
if(used[cur_pattern])return false;
// 添加该字符的映射到哈希表,并标记使用
hash_table.put(cur_str, cur_pattern);
used[cur_pattern] = true;
}
}
return true;
}
无重复字符的最长子串(优化)
在暴力法中,我们会反复检查一个子字符串是否含有有重复的字符,但这是没有必要的。如果从索引 i到 j - 1之间的子字符串 s{ij}已经被检查为没有重复字符。我们只需要检查 s[j]对应的字符是否已经存在于子字符串 s{ij}中。
要检查一个字符是否已经在子字符串中,我们可以检查整个子字符串,这将产生一个复杂度为 O(n^2)的算法,但我们可以做得更好。
通过使用 HashSet 作为滑动窗口,我们可以用 O(1)的时间来完成对字符是否在当前的子字符串中的检查。
滑动窗口是数组/字符串问题中常用的抽象概念。 窗口通常是在数组/字符串中由开始和结束索引定义的一系列元素的集合,即 [i, j)(左闭,右开)。而滑动窗口是可以将两个边界向某一方向“滑动”的窗口。例如,我们将 [i, j) 向右滑动 11 个元素,则它将变为 [i+1, j+1)(左闭,右开)。
回到我们的问题,我们使用 HashSet 将字符存储在当前窗口 [i, j)(最初 j = i)中。 然后我们向右侧滑动索引 j,如果它不在 HashSet 中,我们会继续滑动 j。直到 s[j] 已经存在于 HashSet 中。此时,我们找到的没有重复字符的最长子字符串将会以索引 i开头。
我们可以做以下优化:我们可以定义字符到索引的映射,而不是使用集合来判断一个字符是否存在。 当我们找到重复的字符时,我们可以立即跳过该窗口。
也就是说,如果 s[j]s[j] 在 [i, j)范围内有与 j’重复的字符,我们不需要逐渐增加 i 。 我们可以直接跳过 [i,j’]范围内的所有元素,并将 i 变为j ′ +1。
算法思路
- 定义result为当前最长子串的长度
- 定义begin指向滑动窗口的起始索引,end指向滑动窗口的结束索引
- 定义哈希表记录当前各字符的位置
- 指针向后逐个扫描字符串中的字符,并用哈希表记录当前字符的位置。
- 如果该字符在哈希表中,说明该字符重复遍历,此时起始索引为 当前起始索引 与 上一次遍历该字符的索引 中较大值。
- 如果该字符不在哈希表中,则在哈希表中记录该字符索引。
- 整个过程中,begin 与 end 维护一个窗口,窗口中的子串为无重复字符的子串。若该子串长度大于当前最长子串长度result,则更新result
程序代码
public int lengthOfLongestSubstring(String s) {
// 滑动窗口
int result = 0; // result为当前最长子串的长度
int begin = 0;int end = 0; // begin指向滑动窗口的起始索引,end指向滑动窗口的结束索引
HashMap<Character, Integer> hash_map = new HashMap<Character, Integer>(); // 利用哈希表记录当前各字符的位置
// 指针向后逐个扫描字符串中的字符,并用哈希表记录当前字符的位置。
// 如果该字符在哈希表中,说明该字符重复遍历,此时起始索引为 当前起始索引 与 上一次遍历该字符的索引 中较大值。
// 如果该字符不在哈希表中,则在哈希表中记录该字符索引。
// 整个过程中,begin 与 end 维护一个窗口,窗口中的子串为无重复字符的子串。若该子串长度大于当前最长子串长度result,则更新result
for(end = 0;end < s.length();end++) {
Character cur_char = s.charAt(end);
if(hash_map.containsKey(cur_char)) {
// 滑动窗口的优化,避免无用的遍历(包含该重复字符),将起始索引指向该字符的索引+1 与 当前索引 中较大值
begin = Math.max(hash_map.get(cur_char)+1, begin);
}
hash_map.put(cur_char, end); // hash表更新当前字符的位置
result = Math.max(result, end-begin+1); // 比较当前窗口的长度与当前最长子串长度result大小,若大于,则更新result
}
return result;
}
第八章 搜索
- BFS
- DFS
(见 第五章 图) - 典型例题
词语阶梯2
题目描述
给定两个单词(beginWord 和 endWord)和一个字典 wordList,找出所有从 beginWord 到 endWord 的最短转换序列。转换需遵循如下规则:
每次转换只能改变一个字母。
转换过程中的中间单词必须是字典中的单词。
说明:
如果不存在这样的转换序列,返回一个空列表。
所有单词具有相同的长度。
所有单词只由小写字母组成。
字典中不存在重复的单词。
你可以假设 beginWord 和 endWord 是非空的,且二者不相同。
示例 1:
输入:
beginWord = "hit",
endWord = "cog",
wordList = ["hot","dot","dog","lot","log","cog"]
输出:
[
["hit","hot","dot","dog","cog"],
["hit","hot","lot","log","cog"]
]
示例 2:
输入:
beginWord = "hit"
endWord = "cog"
wordList = ["hot","dot","dog","lot","log"]
输出: []
解释: endWord "cog" 不在字典中,所以不存在符合要求的转换序列。
算法思路
- 记录路径的宽度搜索
(1)将普通队列更换为vector实现队列,保存所有的搜索节点,即在pop节点时不会丢弃队头元素,只是移动front指针。
(2)在队列节点中增加该节点的前驱节点在队列中的下标信息,可通过该下标找到是队列中的哪个节点搜索到地当前节点。
class BFSItem{
String word; // 搜索节点
Integer parent_pos; //前驱节点在队列中的位置
Integer step; //到达当前节点的步数
BFSItem(String word, Integer parent_pos, Integer step){
this.word = word;
this.parent_pos = parent_pos;
this.step = step;
}
}
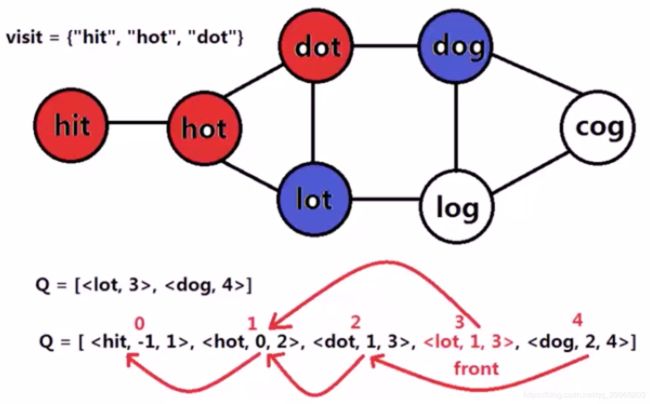
- 多条路径的保存
到达某一位置可能存在多条路径,使用映射记录到达每个位置的最短需要步数,新扩展到的位置只要未曾到达或到达步数与最短步数相同,即将该位置添加到队列中,从而存储了从不同前驱到达该位置的情况。
- 遍历搜索路径
从所有结果(endWord)所在的队列位置(end_word_pos),向前遍历直到起始单词(beginWord),遍历过程中,保存路径上的单词。如此遍历得到的路径为endWord到beginWord的路径,将其按从尾到头的顺序存储到最终结果中即可。

程序代码
// 记录路径的BFS
// 1.将普通队列更换成LinkedList,保存所有的搜索节点,在pop节点时不会丢弃对头元素,只移动front指针
// 2.再队列节点中增加该节点的前驱节点再队列中的下标信息,即可以通过该下标找到是队列中的哪个节点搜索到的当前节点。
class BFSItem{
String word; // 搜索节点
Integer parent_pos; //前驱节点在队列中的位置
Integer step; //到达当前节点的步数
BFSItem(String word, Integer parent_pos, Integer step){
this.word = word;
this.parent_pos = parent_pos;
this.step = step;
}
}
// 126. 单词接龙 II
// 给定两个单词(beginWord 和 endWord)和一个字典 wordList,找出所有从 beginWord 到 endWord 的最短转换序列。
// 转换需遵循如下规则:
// 每次转换只能改变一个字母。
// 转换过程中的中间单词必须是字典中的单词。
public List<List<String>> findLadders(String beginWord, String endWord, List<String> wordList) {
List<List<String>> result = new ArrayList<List<String>>(); // 存储所有最短转换序列
HashMap<String,ArrayList<String>> combineNode = new HashMap<String,ArrayList<String>>(); // 利用哈希表存储单词及其邻接节点列表(图结构)
HashMap<String,Integer> visited = new HashMap<String, Integer>(); // 存储已经访问过的单词节点的单词及步数
List<Integer> end_word_pos = new ArrayList<Integer>(); // 终点endWord所在队列位置下标
initCombineNode(combineNode, beginWord, wordList); // 构造邻接图
Integer min_step = 0;//到达endWord的最小步数
// 对图结构进行BFS
ArrayList<BFSItem> Q = new ArrayList<BFSItem>(); // 构造自定义队列,存储BFS节点(节点单词,父结点下标,步数)
Q.add(new BFSItem(beginWord,-1,1)); // 起始单词的前驱为-1
visited.put(beginWord, 1); // 标记起始单词的步数为1
Integer front = 0; // 队列指针front指向队列Q的队列头
while(front != Q.size()) {
BFSItem cur_item = Q.get(front); // 队列头元素
String cur_word = cur_item.word; // 当前元素单词
Integer cur_step = cur_item.step; // 当前元素步数
if(min_step!=0 && cur_step>min_step)break; // step>min_step时,代表所有到达终点的路径都搜索完成
if(cur_word == endWord) {min_step = cur_step;end_word_pos.add(front);} // 搜索到结果时,记录到达终点的最小步数
ArrayList<String> neighbours = combineNode.get(cur_word);
for(int i=0;i<neighbours.size();i++) {
String neighbourWord = neighbours.get(i);
if(!visited.containsKey(neighbourWord) || visited.get(neighbourWord) == cur_step+1) { // 节点未访问,或是另一条最短路径
Q.add(new BFSItem(neighbourWord,front,cur_step+1));
visited.put(neighbourWord, cur_step+1);//标记到达邻接点neighbourWord的最小步数
}
}
front++;
}
// 从endWord到beginWord将路径上的节点值push进入path
for(int i=0;i<end_word_pos.size();i++) { // 作为一条路径
int pos = end_word_pos.get(i);
List<String> path = new ArrayList<String>();
while(pos!=-1) {
path.add(Q.get(pos).word);
pos = Q.get(pos).parent_pos; // 根据前置节点找路径
}
List<String> result_item = new ArrayList<String>();
for(int j=path.size()-1;j>=0;j--) result_item.add(path.get(j));
result.add(result_item);
}
return result;
}
题目描述
给定两个单词(beginWord 和 endWord)和一个字典 wordList,找出所有从 beginWord 到 endWord 的最短转换序列。转换需遵循如下规则:
每次转换只能改变一个字母。
转换过程中的中间单词必须是字典中的单词。
说明:
如果不存在这样的转换序列,返回一个空列表。
所有单词具有相同的长度。
所有单词只由小写字母组成。
字典中不存在重复的单词。
你可以假设 beginWord 和 endWord 是非空的,且二者不相同。
示例 1:
输入:
beginWord = "hit",
endWord = "cog",
wordList = ["hot","dot","dog","lot","log","cog"]
输出:
[
["hit","hot","dot","dog","cog"],
["hit","hot","lot","log","cog"]
]
示例 2:
输入:
beginWord = "hit"
endWord = "cog"
wordList = ["hot","dot","dog","lot","log"]
输出: []
解释: endWord "cog" 不在字典中,所以不存在符合要求的转换序列。
算法思路
- 记录路径的宽度搜索
(1)将普通队列更换为vector实现队列,保存所有的搜索节点,即在pop节点时不会丢弃队头元素,只是移动front指针。
(2)在队列节点中增加该节点的前驱节点在队列中的下标信息,可通过该下标找到是队列中的哪个节点搜索到地当前节点。
class BFSItem{
String word; // 搜索节点
Integer parent_pos; //前驱节点在队列中的位置
Integer step; //到达当前节点的步数
BFSItem(String word, Integer parent_pos, Integer step){
this.word = word;
this.parent_pos = parent_pos;
this.step = step;
}
}
- 多条路径的保存
到达某一位置可能存在多条路径,使用映射记录到达每个位置的最短需要步数,新扩展到的位置只要未曾到达或到达步数与最短步数相同,即将该位置添加到队列中,从而存储了从不同前驱到达该位置的情况。
- 遍历搜索路径
从所有结果(endWord)所在的队列位置(end_word_pos),向前遍历直到起始单词(beginWord),遍历过程中,保存路径上的单词。如此遍历得到的路径为endWord到beginWord的路径,将其按从尾到头的顺序存储到最终结果中即可。
程序代码
// 记录路径的BFS
// 1.将普通队列更换成LinkedList,保存所有的搜索节点,在pop节点时不会丢弃对头元素,只移动front指针
// 2.再队列节点中增加该节点的前驱节点再队列中的下标信息,即可以通过该下标找到是队列中的哪个节点搜索到的当前节点。
class BFSItem{
String word; // 搜索节点
Integer parent_pos; //前驱节点在队列中的位置
Integer step; //到达当前节点的步数
BFSItem(String word, Integer parent_pos, Integer step){
this.word = word;
this.parent_pos = parent_pos;
this.step = step;
}
}
// 126. 单词接龙 II
// 给定两个单词(beginWord 和 endWord)和一个字典 wordList,找出所有从 beginWord 到 endWord 的最短转换序列。
// 转换需遵循如下规则:
// 每次转换只能改变一个字母。
// 转换过程中的中间单词必须是字典中的单词。
public List<List<String>> findLadders(String beginWord, String endWord, List<String> wordList) {
List<List<String>> result = new ArrayList<List<String>>(); // 存储所有最短转换序列
HashMap<String,ArrayList<String>> combineNode = new HashMap<String,ArrayList<String>>(); // 利用哈希表存储单词及其邻接节点列表(图结构)
HashMap<String,Integer> visited = new HashMap<String, Integer>(); // 存储已经访问过的单词节点的单词及步数
List<Integer> end_word_pos = new ArrayList<Integer>(); // 终点endWord所在队列位置下标
initCombineNode(combineNode, beginWord, wordList); // 构造邻接图
Integer min_step = 0;//到达endWord的最小步数
// 对图结构进行BFS
ArrayList<BFSItem> Q = new ArrayList<BFSItem>(); // 构造自定义队列,存储BFS节点(节点单词,父结点下标,步数)
Q.add(new BFSItem(beginWord,-1,1)); // 起始单词的前驱为-1
visited.put(beginWord, 1); // 标记起始单词的步数为1
Integer front = 0; // 队列指针front指向队列Q的队列头
while(front != Q.size()) {
BFSItem cur_item = Q.get(front); // 队列头元素
String cur_word = cur_item.word; // 当前元素单词
Integer cur_step = cur_item.step; // 当前元素步数
if(min_step!=0 && cur_step>min_step)break; // step>min_step时,代表所有到达终点的路径都搜索完成
if(cur_word == endWord) {min_step = cur_step;end_word_pos.add(front);} // 搜索到结果时,记录到达终点的最小步数
ArrayList<String> neighbours = combineNode.get(cur_word);
for(int i=0;i<neighbours.size();i++) {
String neighbourWord = neighbours.get(i);
if(!visited.containsKey(neighbourWord) || visited.get(neighbourWord) == cur_step+1) { // 节点未访问,或是另一条最短路径
Q.add(new BFSItem(neighbourWord,front,cur_step+1));
visited.put(neighbourWord, cur_step+1);//标记到达邻接点neighbourWord的最小步数
}
}
front++;
}
// 从endWord到beginWord将路径上的节点值push进入path
for(int i=0;i<end_word_pos.size();i++) { // 作为一条路径
int pos = end_word_pos.get(i);
List<String> path = new ArrayList<String>();
while(pos!=-1) {
path.add(Q.get(pos).word);
pos = Q.get(pos).parent_pos; // 根据前置节点找路径
}
List<String> result_item = new ArrayList<String>();
for(int j=path.size()-1;j>=0;j--) result_item.add(path.get(j));
result.add(result_item);
}
return result;
}
第九章 动态规划
动态规划(dynamic programming)基于最优化原理,利用各阶段之间的关系,逐个求解,最终求得全局最优解。
- 最优子结构
用动态规划求解最优化问题的第一步就是刻画最优解的结构,如果一个问题的解结构包含其子问题的最优解,就称此问题具有最优子结构性质。 - 重叠子问题
如果递归算法反复求解相同的子问题,就称为具有重叠子问题(overlapping subproblems)性质。在动态规划算法中使用数组来保存子问题的解,这样子问题多次求解的时候可以直接查表(对于重复子问题,可以将结果保存到一个数组,需要时直接从数组中取值)而不用调用函数递归。 - 算法思路
若要解一个给定问题,我们需要解其不同部分(即子问题),再合并子问题的解以得出原问题的解。 通常许多子问题非常相似,为此动态规划法试图仅仅解决每个子问题一次,从而减少计算量: 一旦某个给定子问题的解已经算出,则将其记忆化存储,以便下次需要同一个子问题解之时直接查表。 这种做法在重复子问题的数目关于输入的规模呈指数增长时特别有用。
实现步骤:
- 确认原问题与子问题
- 描绘问题的解结构(一般通过一维/二维DP数组)并确认一般状态(DP[i]的意义)
- 确认边界状态的值(可理解为递归出口) & 状态转移方程(由边界状态推出一般状态的规律,可理解为递归函数)
状态转移方程一般通过自顶向下递归分析,再自底向上动态规划推导得出。有2种解法:
自顶向下备忘录法从结果(父问题)出发,逐步向下寻找出口(子问题)。它的本质还是递归,计算递归的过程可能有O(2^n)复杂度,它将结果存储在备忘录数组中。下一次调用相同结果可以直接从备忘录数组中获取。
自底向上动态规划根据规律,从递归出口(子问题)出发(已知),设计动态规划数组,逐渐寻找父问题的解。
其实,动态规划应该先自顶向下思考,再自底向上求得结果。
- 背诵模板
求最多能赚多少钱
题目描述
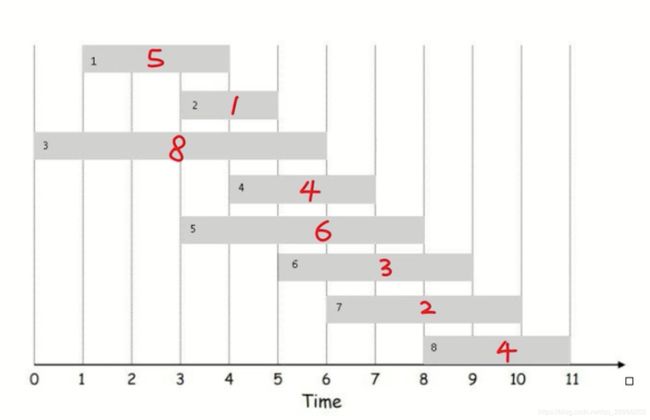
共有8个任务,如图为每个任务执行起始时间与结束时间,以及做完每件事情可赚金钱。
要求:执行每个任务的时间不能重叠
求如何选择执行任务能够赚最多钱?
解题思路
能够赚最多金钱——最优解问题,可通过定义最优解数组完成
最优解数组即 包含i个子问题的最优解。这里可理解为:可执行i个任务所能够赚的最多钱。
先自顶向下分析:一共有8个任务,每个任务都有2种状态:选/不选。选择该任务则可将多赚该任务的价值,但不能选择与该任务重叠时间的任务;不选该任务则无法赚得该任务的价值,对其余任务没有影响。例如对于OPT(8)而言即求共有8个任务时最多能够赚的金钱,如果选择了第8个任务,则可赚4元(arr[8]=4)且剩下只能选择前5个任务(prev[8]=5),此时最优解(最多可赚金钱)应该为前5个任务最多可赚金钱+第8个任务可赚金钱=OPT(5)+4;如果没有选择第8个任务,则不赚任何钱,选择前7(8-1)个任务可赚最多钱=OPT(7)。因此,含有8个任务的最优解为max(OPT(5)+4,opt(7))。剩下依此类推,可画出递归树:
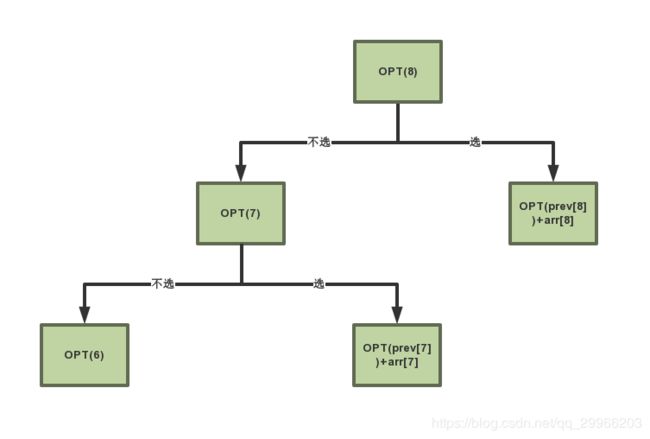
由递归树,可总结出一般规律,即:
OPT(i) = max(OPT(i-1) , OPT(prev()) + arr[i])
递归出口为:
OPT(0) = arr[0]; //只有一个任务时一定选择该任务能得到最优解
因此这里的8个任务可看做具有最优子结构(max(选/不选))的重叠子问题(都可用以上最优解方程求得最优解)。
程序代码
(1)自顶向下递归备忘录
public int BestSolution1(List<Task> list) {
//存储解决i个问题时的最优解,即需要执行i个任务可赚得最多金钱,由递归树可得代码
int[] OPT = new int[list.size()];
//初始化前置数组,即如果选择了第i个任务,则下一次只能选择前prev[i]个任务
int[] prev = new int[list.size()];
for(int i=list.size()-1;i>=0;i--) {
Integer startTime = list.get(i).startTime;
prev[i] = -1;
for(int j = i-1;j>=0;j--) {
//往前遍历,选取之前第一个结束时间在该任务开始事件之前的任务。
Integer endTime = list.get(j).endTime;
if(endTime<=startTime) {
prev[i] = j;
break;
}
}
}
int result = mem_BestSolution1(list,prev,OPT);
return result;
}
public int mem_BestSolution1(List<Task> list,int[] prev,Integer i,int[] OPT) {
//自顶向下备忘录法求得解决第i个问题时的最优解
//递归思想,复杂度为O(2^n)
//递归出口,第1个任务的最优解一定是执行完第一个任务所赚的钱
if(i<0) return 0;//i<0表示没有需要执行的任务,最优解(能赚的最多钱)=0
else if(i==0) OPT[0] = list.get(0).value;
else {
//其余任务则根据总结出的一般规律得出
int choose_A = mem_BestSolution1(list,prev,i-1,OPT);//不选择第i个任务时取前i-1个任务的最优解
int choose_B = mem_BestSolution1(list,prev,prev[i],OPT) + list.get(i).value;//选择第i个任务时取前prev[i]任务最优解 + 该任务所赚的钱
OPT[i] = max(choose_A,choose_B);//取 选/不选 该任务的最大值 即为最优解
}
return OPT[i];
}
public int max(int a,int b) {
//获取a,b中最大值
return a>=b?a:b;
}
public static class Task{
Integer startTime; //起始时间
Integer endTime; //结束时间
Integer value; //可赚金钱
public Task(Integer startTime,Integer endTime,Integer value){
this.startTime = startTime;
this.endTime = endTime;
this.value = value;
}
}
(2)自底向上动态规划
public int BestSolution1(List<Task> list) {
//存储解决i个问题时的最优解,即需要执行i个任务可赚得最多金钱,由递归树可得代码
int[] OPT = new int[list.size()];
//初始化前置数组,即如果选择了第i个任务,则下一次只能选择前prev[i]个任务
int[] prev = new int[list.size()];
for(int i=list.size()-1;i>=0;i--) {
Integer startTime = list.get(i).startTime;
prev[i] = -1;
for(int j = i-1;j>=0;j--) {
//往前遍历,选取之前第一个结束时间在该任务开始事件之前的任务。
Integer endTime = list.get(j).endTime;
if(endTime<=startTime) {
prev[i] = j;
break;
}
}
}
int result = dp_BestSolution1(list,prev,OPT);
return result;
}
public int dp_BestSolution1(List<Task> list,int[] prev,int[] OPT) {
//自底向上动态规划求得解决第i个问题时的最优解
//遍历思想,复杂度为O(n)
//递归出口,第1个任务的最优解一定是执行完第一个任务所赚的钱
Integer task_number = list.size();
OPT[0] = list.get(0).value;//最小子问题
for(int i = 1;i<task_number;i++) {
//由最小子问题逐渐向外遍历求最优解,最终求得父问题最优解
int choose_A = 0;
int choose_B = 0;
if(prev[i]==-1) {
//选择当前任务后不能再选其他任务(对数组越界(i = -1)单独处理)
choose_A = OPT[i-1];//不选择第i个任务时取前i-1个任务的最优解
choose_B = list.get(i).value;//该任务所赚的钱,下一次任务为前OPT[-1],即表示选择当前任务后不能再选取之前的任何任务
}else {
choose_A = OPT[i-1];//不选择第i个任务时取前i-1个任务的最优解
choose_B = OPT[prev[i]] + list.get(i).value;//选择第i个任务时取前prev[i]任务最优解 + 该任务所赚的钱
}
OPT[i] = choose_A>choose_B?choose_A:choose_B;//取 选/不选 该任务的最大值 即为最优解
}
return OPT[task_number-1];
}
public int max(int a,int b) {
//获取a,b中最大值
return a>=b?a:b;
}
public static class Task{
Integer startTime; //起始时间
Integer endTime; //结束时间
Integer value; //可赚金钱
public Task(Integer startTime,Integer endTime,Integer value){
this.startTime = startTime;
this.endTime = endTime;
this.value = value;
}
}
求是否存在所选数组求和 = 给定值
题目描述

对于数组arr,取出一组数字,且不能取相邻数字,是否存在方案使得所取数字之和 = S?若存在,则返回true,否则返回false。
解题思路
采用动态规划思想,定义数组subset[],第 i 个位置的元素表示包含 i 个元素的数组是否存在方案使所取数字和 = S,若存在方案使数字和 = S,则返回true,否则返回false。
采用自顶向下的思想进行分析:
对于长度为 8 的数组arr,第8个元素包含选或不选两种情况:如果选择第 8 个元素,则此时解为求解长度为7的数组arr存在数字和 = S - 第8个元素;如果不选第8个元素,则此时解为求解长度为7的数组arr存在数字和 = S。长度为 8 的数组arr存在数字和为 S 的解为 这两种情况取或(只要有一种成立即可),长度为7的数组arr,长度为6的数组arr…可用相同的思想分析,因此得一般规律
subset(i,S) = subset(i-1,S) || subset(i-1,S-arr[i])
递归出口为(递归出口的情况应该分析完整)
if(S == 0)return true;//如果取到0,则说明存在方案使取值=S
if(i == 0){
/*
if(arr[i] == S)return true;
else return false;//遍历到第一个元素,若第一个元素=S,则存在方案,否则不存在方案
*/
return arr[i] == S;
}
if(arr[i]>S)return subset(i-1,S);//若该元素大于S,则一定不选该元素
程序代码
(1)自顶向下递归备忘录
public boolean BestSolution3(int[] arr,int S) {
// 存储解决i个问题时的最优解,即长度为i的数组是否能够取一组数字,使得数字求和 = S
// 这里最优解数组为二维数组,由于每个子问题包含两个变量,一个为数组长度,一个为求和S大小,横坐标表示长度为i的数组,纵坐标表示求和S
// 即对于最优解数组SUBSET[i][j]表示长度为 i+1 的数组是否存在数字和为 j 的一组数
boolean[][] SUBSET = new boolean[arr.length][S+1];
boolean result = mem_BestSolution3(arr,S,arr.length-1,SUBSET);
//boolean result = dp_BestSolution3(arr,S,SUBSET);
return result;
}
public boolean mem_BestSolution3(int[] arr,int S,int i,boolean[][] SUBSET) {
//采用自顶向下备忘录法进行回溯
//每一次递归求的是包含 i+1 个元素的数组arr是否存在和为 S 的一组数
if(S == 0)SUBSET[i][0] = true;//若求和S=0,则一定存在方案(剩下均不选)
else if(i==0)
{
if(arr[0] == S)SUBSET[0][S] = true;
else SUBSET[0][S] = false;//如果数组只含有1个元素,若该元素=S,则存在方案,否则不存在方案
}
else if(arr[i] > S) {
//若该元素大于所需求和S,则求不选这个元素时的方案(取包含i-1个元素的数组方案)
SUBSET[i][S] = mem_BestSolution3(arr,S,i-1,SUBSET);
}
else {
// 不选该元素时,取包含 i-1 个元素是否存在求和为 S 的方案
// 选该元素时,取包含 i-1 个元素是否存在求和为 S-arr[i] 的方案
// 包含 i 个元素时的解为这两种方案求解的或
SUBSET[i][S] = (mem_BestSolution3(arr,S-arr[i],i-1,SUBSET) || mem_BestSolution3(arr,S,i-1,SUBSET));
}
return SUBSET[i][S];
}
(2)自底向上动态规划
public boolean BestSolution3(int[] arr,int S) {
// 存储解决i个问题时的最优解,即长度为i的数组是否能够取一组数字,使得数字求和 = S
// 这里最优解数组为二维数组,由于每个子问题包含两个变量,一个为数组长度,一个为求和S大小,横坐标表示长度为i的数组,纵坐标表示求和S
// 即对于最优解数组SUBSET[i][j]表示长度为 i+1 的数组是否存在数字和为 j 的一组数
boolean[][] SUBSET = new boolean[arr.length][S+1];
boolean result = mem_BestSolution3(arr,S,arr.length-1,SUBSET);
//boolean result = dp_BestSolution3(arr,S,SUBSET);
return result;
}
public boolean dp_BestSolution3(int[] arr,int S,boolean[][] SUBSET) {
//采用自底向上动态规划,从已知开始构造求解数组
//当S=0时,则一定存在方案。即SUBSET[i][0](0<=i<=arr.length-1)
for(int i=0;i<=arr.length-1;i++)SUBSET[i][0] = true;
//当i=0时,若arr[0]==S则一定存在,否则不存在
for(int j=1;j<=S;j++) {
if(arr[0] == j)SUBSET[0][j] = true;
else SUBSET[0][j] = false;
}
for(int i=1;i<=arr.length-1;i++)
for(int j=1;j<=S;j++) {
//遍历法求解
if(arr[i]>j)SUBSET[i][j] = SUBSET[i-1][j];
else {
SUBSET[i][j] = (SUBSET[i-1][j] || SUBSET[i-1][j-arr[i]]);
}
}
return SUBSET[arr.length-1][S];
}
- 典型例题
连续子数组的最大和
题目描述
HZ偶尔会拿些专业问题来忽悠那些非计算机专业的同学。今天测试组开完会后,他又发话了:在古老的一维模式识别中,常常需要计算连续子向量的最大和,当向量全为正数的时候,问题很好解决。但是,如果向量中包含负数,是否应该包含某个负数,并期望旁边的正数会弥补它呢?例如:{6,-3,-2,7,-15,1,2,2},连续子向量的最大和为8(从第0个开始,到第3个为止)。给一个数组,返回它的最大连续子序列的和,你会不会被他忽悠住?(子向量的长度至少是1)
程序代码
// 30.连续子数组的最大和
// HZ偶尔会拿些专业问题来忽悠那些非计算机专业的同学。
// 今天测试组开完会后,他又发话了:在古老的一维模式识别中,常常需要计算连续子向量的最大和,
// 当向量全为正数的时候,问题很好解决。但是,如果向量中包含负数,是否应该包含某个负数,并期望旁边的正数会弥补它呢?
// 例如:{6,-3,-2,7,-15,1,2,2},连续子向量的最大和为8(从第0个开始,到第3个为止)。
// 给一个数组,返回它的最大连续子序列的和,你会不会被他忽悠住?(子向量的长度至少是1)
public int FindGreatestSumOfSubArray(int[] array) {
// 采用动态规划
// 设F(i) 表示以array[i]为结尾的子数组的最大值,则
// F(i) = max(F(i-1)+array[i],array[i]);
// 利用数组maxArray存储这些数组的最大值,则array中子数组最大值为maxValueOf(maxArray)
int[] maxArray = constructMaxSubArray(array);// maxArrays存储以array[i]为末尾的子数组的最大值
int maxSum = Integer.MIN_VALUE; // 记录子数组最大值
for(int i=0;i<maxArray.length;i++)
if(maxArray[i]>maxSum)maxSum = maxArray[i];
return maxSum;
}
// 自顶向下备忘录法
public int[] constructMaxSubArray(int[] array) {
int[] maxArray = new int[array.length];
maxArray[0] = array[0];
for(int i=1;i<array.length;i++) {
maxArray[i] = Integer.max(maxArray[i-1] + array[i], array[i]);
}
return maxArray;
}
滑动窗口最大值
题目描述
给定一个数组和滑动窗口的大小,找出所有滑动窗口里数值的最大值。例如,如果输入数组{2,3,4,2,6,2,5,1}及滑动窗口的大小3,那么一共存在6个滑动窗口,他们的最大值分别为{4,4,6,6,6,5}; 针对数组{2,3,4,2,6,2,5,1}的滑动窗口有以下6个: {[2,3,4],2,6,2,5,1}, {2,[3,4,2],6,2,5,1}, {2,3,[4,2,6],2,5,1}, {2,3,4,[2,6,2],5,1}, {2,3,4,2,[6,2,5],1}, {2,3,4,2,6,[2,5,1]}。
程序代码
// 63.滑动窗口的最大值
// 给定一个数组和滑动窗口的大小,找出所有滑动窗口里数值的最大值。
// 例如,如果输入数组{2,3,4,2,6,2,5,1}及滑动窗口的大小3,那么一共存在6个滑动窗口,他们的最大值分别为{4,4,6,6,6,5};
// 针对数组{2,3,4,2,6,2,5,1}的滑动窗口有以下6个:
// {[2,3,4],2,6,2,5,1}, {2,[3,4,2],6,2,5,1}, {2,3,[4,2,6],2,5,1},
// {2,3,4,[2,6,2],5,1}, {2,3,4,2,[6,2,5],1}, {2,3,4,2,6,[2,5,1]}。
ArrayList<Integer> maxInWindowsList = new ArrayList<Integer>(); // 窗口最大值列表
public ArrayList<Integer> maxInWindows(int [] num, int size)
{
if(size > num.length || size<=0)return maxInWindowsList;
getMaxWindowsList(num,size);
return maxInWindowsList;
}
public void getMaxWindowsList(int[] num,int size) {
// 填充窗口最大值列表的第 i 位置元素,即
// 以第 i+size-1 个元素作为窗口尾端元素时窗口的最大值
// 一共需要填充 num.length-size+1 个元素
// 以第 i 个元素为窗口尾端元素时窗口的最大值 = 上一个滑动窗口的最大值
// 初始化,窗口最大值列表
maxInWindowsList.add(findMaxInArray(num,0,size-1));
for(int i=1;i<num.length-size+1;i++) {
// 填充窗口最大值列表的第i个位置
// 为以 j 为末端的长为size的窗口最大值
// 若新添加数 num[j]> maxInWindowsList[i-1],则最大值为num[j]
// 否则,若最大值不为上一个滑动窗口的首元素,则最大值为maxInWindowsList[i-1]
// 否则,重新通过findMaxInArray遍历窗口元素寻找最大值
int j = i+size-1; // 滑动窗口最末端元素
int lastMax = maxInWindowsList.get(i-1);
if(num[j] > lastMax)maxInWindowsList.add(num[j]);
else {
if(num[i-1] != lastMax)maxInWindowsList.add(lastMax);
else maxInWindowsList.add(findMaxInArray(num,i,j));
}
}
}
找零钱
题目描述
给定不同面额的硬币 coins 和一个总金额 amount。编写一个函数来计算可以凑成总金额所需的最少的硬币个数。如果没有任何一种硬币组合能组成总金额,返回 -1。
示例 1:
输入: coins = [1, 2, 5], amount = 11
输出: 3
解释: 11 = 5 + 5 + 1
示例 2:
输入: coins = [2], amount = 3
输出: -1
说明:
你可以认为每种硬币的数量是无限的。
算法思路
- 是否可以用贪心?
钞票面值为[1,2,5,7,10],金额为14,最优解需要2张7元。如果用贪心思想,每次优先使用较大面值的金额,选1张10元,剩下4元选2张2元。一共用3张。错解。
因此贪心思想在个别面值组合是可以的(如[1,2,5,10,20,50,100]),但本题面值不确定,因此不能用贪心思想。 - 采用动态规划的解决方案?
分析钞票面值coins=[1,2,5,7,10],金额:14
dp[i]代表金额i的最优解(即最少使用钞票的数量)。在计算dp[i]时,dp[0]、dp[1]、dp[2]、…、dp[i-1]都是已知的:而金额i可由:
金额 i-1 与coins[0](1)组合;
金额 i-2 与coins[1](2)组合;
金额 i-5 与coins[2](5)组合;
金额 i-7 与coins[3](7)组合;
金额 i-10 与coins[4](10)组合;
即状态可由状态i-1、i-2、i-5、i-7、i-10这5个状态转移到,因此dp[i] = min(dp[i-1],dp[i-2],dp[i-5],dp[i-7],dp[i-10]) + 1
程序代码
public int coinChange(int[] coins, int amount) {
// dp[i] 代表金额i的最优解(即凑成金额 i 的最小使用钞票数)
// 假设对于[1,2,5,7,10] 若需要的最小钞票数i 即为 (i-1,i-2,i-5,i-7,i-10 所需要的最小钞票数)中最小值 + 1
// 即若可通过添加某个硬币获得金额 i ,则金额 i 的状态为获取该硬币前的状态 加上 该硬币
// 即金额i的最优解(所需最少钞票数) = 获取该硬币前的最优解(所需最少钞票数) + 1
// dp[i] = min( dp[i-1],dp[i-2],dp[i-5],dp[i-7],dp[i-10]) + 1
int[] dp = new int[amount+1];//dp[i]表示金额为i时的最优解(最少使用的钞票数目)
for(int i=0;i<=amount;i++)
dp[i] = -1;//初始化dp数组,最初所有金额的初始值均为-1,表示不可到达
dp[0]=0;//金额为0的最优解为0
for(int i=1;i<=amount;i++) {//遍历所有金额,对1~所求金额求最优解
for(int j=0;j<coins.length;j++) {
//若可通过添加某个硬币得到该金额,则此时 金额i的最优解 = 获取该硬币前(金额i - coins[j])的最优解 + 1
if(i >= coins[j] && dp[i-coins[j]] != -1) {//若所求金额>硬币的值(可通过添加硬币得到金额i) 且 获取硬币前的状态可达
if(dp[i] > dp[i-coins[j]]+1 || dp[i]==-1) {//若该方案比之前取硬币方案所需硬币数更小 或者 为第一个方案
dp[i] = dp[i-coins[j]]+1;//取所有方案的最小值
}
}
}
}
return dp[amount];//返回金额为amount的最优解
}
第十章 复杂的数据结构
- 字典树(trie 树)
trie树,又称字典树或前缀树,是一种有序的、用于统计、排序和存储字符串的数据结构,它与二叉查找树不同,关键字不是直接保存在结点中,而是由结点在树中的位置决定。
一个结点的所有子孙都有相同的前缀,也就是这个结点对应的字符串,而根节点对应空字符串。一般情况下,不是所有的结点都有对应的值,只有叶子结点和部分内部结点对应的键才有相关的值。
trie树的最大优点就是利用字符串的公共前缀来减少存储空间与查询时间,从而最大限度地减少无谓字符串地比较,是非常高效地字符串查找数据结构。

trie树的java实现(leetcode 208)
- trie树节点的表示
- trie树插入一个单词
- trie树搜索一个单词
- trie树是否由前缀为prefix的单词
- trie树获取全部单词
//字典树的java实现
public class Trie {
private TrieNode root;
public Trie() {
root = new TrieNode();
root.wordEnd = false;
}
// 字典树树结点的数据结构
public class TrieNode {
Map<Character, TrieNode> children;
boolean wordEnd;
public TrieNode() {
children = new HashMap<Character, TrieNode>(); // 单词对应结点,每个结点有若干指向下个节点的指针(最多26个孩子指针'a'-'z')
wordEnd = false; //访问一个单词并不是要访问到叶子结点为止,因此需要定义wordEnd表示单词是否结束
}
}
// trie树插入单词
public void insert(String word) {
// 使用node指针指向root
// 逐个遍历待插入单词字符串 word 中各个字符
// 若该字符在children中存在:为该node创建该孩子结点
// node指针指向该孩子结点
// 标记node指针指向结点的word_end为true
TrieNode node = root;
for (int i = 0; i < word.length(); i++) {
Character c = new Character(word.charAt(i));
if (!node.children.containsKey(c)) {
node.children.put(c, new TrieNode());
}
node = node.children.get(c);
}
node.wordEnd = true;
}
// trie树查找单词
public boolean search(String word) {
// 使用 node 指针指向root
// 逐个遍历待搜索单词字符串word中各个字符:
// 如果node指向结点中不包含该字符,则单词不存在,返回false
// node 指针指向该字符结点
// 返回node指针指向结点的wordEnd
TrieNode node = root;
boolean found = true;
for (int i = 0; i < word.length(); i++) {
Character c = new Character(word.charAt(i));
if (!node.children.containsKey(c)) {
return false;
}
node = node.children.get(c);
}
return found && node.wordEnd;
}
// trie树是否由前缀为prefix的单词
public boolean startsWith(String prefix) {
TrieNode node = root;
boolean found = true;
for (int i = 0; i < prefix.length(); i++) {
Character c = new Character(prefix.charAt(i));
if (!node.children.containsKey(c)) {
return false;
}
node = node.children.get(c);
}
return found;
}
// Trie树获取全部单词
// 深度搜索trie树,对于正在搜索的结点node:
// 遍历该结点的26个孩子指针child[i],如果指针不为空:
// 将指针对应的字符push 进入栈中,
// 如果该孩子指针标记的is_end为真(说明这个位置是一个单词):
// 从栈底到栈顶堆栈进行遍历,生成字符串,保存到结果数组中
// 深度搜索child[i]
// 弹出栈顶字符
public void get_all_word_from_trie(TrieNode node,String word,List<String> wordList) {
// node为正在遍历的node,word为保存字符串字符的栈,wordList为存储单词的列表
HashMap<Character, TrieNode> children = (HashMap<Character, TrieNode>) node.children;
Iterator<Character> it = children.keySet().iterator();
while (it.hasNext()) { // 遍历该树结点的所有孩子结点
word = word + it.next();
if(node.wordEnd) // 如果是一个结点
wordList.add(word);
}
get_all_word_from_trie(node.children.get(it.next()),word,wordList);
word.substring(0, word.length()-1); // 弹出栈顶字符
}
}
添加与查找单词
题目描述
设计一个支持以下两种操作的数据结构:
void addWord(word)
bool search(word)
search(word) 可以搜索文字或正则表达式字符串,字符串只包含字母 . 或 a-z 。 . 可以表示任何一个字母。
算法思路
模拟字典树结构
程序代码
// 211. 添加与搜索单词 - 数据结构设计
// 添加与搜索单词 - 数据结构设计
// 设计一个支持以下两种操作的数据结构:
// void addWord(word)
// bool search(word)
// search(word) 可以搜索文字或正则表达式字符串,字符串只包含字母 . 或 a-z 。 . 可以表示任何一个字母。
public static class WordDictionary {
private TrieNode root;
public WordDictionary() {
root = new TrieNode();
root.wordEnd = false;
}
// 字典树树结点的数据结构
public class TrieNode {
Map<Character, TrieNode> children;
boolean wordEnd;
public TrieNode() {
children = new HashMap<Character, TrieNode>(); // 单词对应结点,每个结点有若干指向下个节点的指针(最多26个孩子指针'a'-'z')
wordEnd = false; //访问一个单词并不是要访问到叶子结点为止,因此需要定义wordEnd表示单词是否结束
}
}
// 同字典树插入单词 new Tire().insert(word);
public void addWord(String word) {
// 使用node指针指向root
// 逐个遍历待插入单词字符串 word 中各个字符
// 若该字符在children中存在:为该node创建该孩子结点
// node指针指向该孩子结点
// 标记node指针指向结点的word_end为true
TrieNode node = root;
for (int i = 0; i < word.length(); i++) {
Character c = new Character(word.charAt(i));
if (!node.children.containsKey(c)) {
node.children.put(c, new TrieNode());
}
node = node.children.get(c);
}
node.wordEnd = true;
}
public boolean search(String word) {
// node为正在搜索的结点,word为正在搜索的单词,查找成功返回true;否则返回false
// 对于word的每一个字符
// 遍历到单词结束时(i == word.length-1),若node指向的结点标记为单词的结尾 wordEnd = true,则返回真;否则返回假
// 遍历到'.'(word[i] == '.'),继续深度递归遍历该结点的所有孩子子树,node指针向前移动一个位置,如果递归深搜结果为真,则返回真
// 遍历到'a'~'z'(word[i]>='a' && word[i]<='z'),若不存在,返回false;否则指向该字符对应的结点,如果递归深搜结果为真,则返回真
TrieNode node = root;
return isCharacterExists( node, 0, word);
}
public boolean isCharacterExists(TrieNode node, int i, String word) {
// 对于字符 word[i],是否能在字典树node中找到
if(i == word.length()) { // 已遍历完所有字符
return node.wordEnd; // 若为单词结尾,返回真
}
Character c = new Character(word.charAt(i));
if(c == '.') { // 若该字符为'.'
Iterator<Character> it = node.children.keySet().iterator();
while (it.hasNext()) { // 遍历该树结点的所有孩子结点,若孩子结点深搜结果为true,返回真
if(isCharacterExists(node.children.get(it.next()), i+1, word))return true;
}
}else { // 若该字符为'a'~'z',若子树包含该字符且该字符对应子树深搜结果为true,返回真
if(node.children.containsKey(c) && isCharacterExists(node.children.get(c), i+1, word))return true;
}
return false; // 未查询到,返回false
}
}
- 并查集
并查集(Union Find),又称不相交集合(Disjiont Set),它应用于N个元素的集合求并与查询问题(或图是否存在环),在该应用场景中,我们通常是在开始时让每个元素构成一个单元素的集合,然后按一定顺序将属于同一组元素所在的集合合并,其间要反复查找一个元素在哪个集合中。虽然该问题并不复杂,但面对极大数据量时,普通的数据结构往往无法解决,并查集就是解决该种问题最为优秀的算法。 - 并查集Java实现(森林)
使用森林存储集合之间的关系,属于同一集合的不同元素,都有一个相同的根节点,代表着这个集合。
当进行查找某元素属于哪个集合时,即遍历到该元素的根节点,返回根节点所代表的集合;在遍历过程中使用路径压缩的优化算法,使整体树形状更加扁平,从而优化查询的时间复杂度。
当进行合并时,即将两棵子树合并为一颗树,将一颗子树的根节点指向另一颗子树的根节点;在合并时可按子树的大小,将规模较小的子树合并到规模较大的子树上,从而使树规模更加平衡,从而优化未来查询的时间复杂度。

并查集java实现
- 并查集构造
- 并查集查询根节点
- 并查集合并
// 并查集 java 实现(可将并查集看做树实现)
public class DisjointSet{
final int MAX_VERTICLES = 100;
int[] parent = new int[MAX_VERTICLES]; // 各结点的父结点(用来构造树型结构)
int[] rank = new int[MAX_VERTICLES]; // 各结点的高度(利用rank记录各结点的高度,进行路径压缩)
// 初始化各结点的父结点为-1,高度为0(表示各结点均为单独结点)
public DisjointSet(int size) {
for(int i=0;i<size;i++) {
parent[i] = -1;
rank[i] = 0;
}
}
// 查询根节点
public int find_root(int x) {
// 查找并查集中是否包含x元素,返回x的根节点
int x_root = x;
// 不断循环查询父结点
// 若父结点为 -1 则表示为根结点,返回
while(parent[x_root] != -1)x_root = parent[x_root];
return x_root;
}
// 合并结点
// 路径压缩:将较低树合并到较高树——>使合并后树高度不变。防止多次合并导致树过长,使得查询效率低
public boolean union_verticles(int x,int y) {
// 合并两个结点,返回true表示合并成功,返回false表示x,y已经是同一集合,不用合并(或者表示有向图有环)
int x_root = find_root(x); // x结点的根节点
int y_root = find_root(y); // y结点的根节点
if(x_root == y_root)return false; // x根节点与y根节点相同,x,y属于同一集合
else {
// 路径压缩
if(rank[x_root] > rank[y_root]) { // 若y结点所在树较低
parent[y_root] = x_root; // 则将y加入x所在树
}else if(rank[x_root] < rank[x_root]) { // 若x结点所在树较低
parent[x_root] = y_root; // 则将x加入y所在树
}else { // x结点所在树高度与y结点所在树高度相同
parent[x_root] = y_root; // 将x加入y所在树
rank[y_root]++; // y结点所在树高度++
}
return true; // 合并成功
}
}
// 返回并查集集合数,即parent结点中值为-1的结点数
public int union_number() {
int number = 0;
for(int i=0;i<parent.length;i++)
if(parent[i] == -1)number++;
return number;
}
}
朋友圈
题目描述
班上有 N 名学生。其中有些人是朋友,有些则不是。他们的友谊具有是传递性。如果已知 A 是 B 的朋友,B 是 C 的朋友,那么我们可以认为 A 也是 C 的朋友。所谓的朋友圈,是指所有朋友的集合。
给定一个 N * N 的矩阵 M,表示班级中学生之间的朋友关系。如果M[i][j] = 1,表示已知第 i 个和 j 个学生互为朋友关系,否则为不知道。你必须输出所有学生中的已知的朋友圈总数。
示例 1:
输入:
[[1,1,0],
[1,1,0],
[0,0,1]]
输出: 2
说明:已知学生0和学生1互为朋友,他们在一个朋友圈。
第2个学生自己在一个朋友圈。所以返回2。
示例 2:
输入:
[[1,1,0],
[1,1,1],
[0,1,1]]
输出: 1
说明:已知学生0和学生1互为朋友,学生1和学生2互为朋友,所以学生0和学生2也是朋友,所以他们三个在一个朋友圈,返回1。
注意:
N 在[1,200]的范围内。
对于所有学生,有M[i][i] = 1。
如果有M[i][j] = 1,则有M[j][i] = 1。
算法思路
- 传入代表朋友友谊的二维数组M
- 设置并查集,并查集大小未M.size()
- 对于任意两个学生i,j,如果他们之间存在友谊M[i,j]==1,则将他们进行合并
- 返回并查集集合个数
程序代码
public int findCircleNum(int[][] M) {
// 传入代表朋友友谊的二维数组M
// 设置并查集,并查集大小未M.size()
// 对于任意两个学生i,j,如果他们之间存在友谊M[i,j]==1,则将他们进行合并
// 返回并查集集合个数
int length = M.length; // 学生人数
DisjointSet unionFind = new DisjointSet(length);
for(int i=0;i<length;i++)
for(int j=0;j<i;j++)
if(M[i][j] == 1)unionFind.union_verticles(i, j);
return unionFind.union_number();
}
- 线段树(Segment 树)
线段树是一种平衡二叉搜索树(完全二叉树),它将一个线段区间划分成一些单元区间。对于线段树中的每一个非叶子结点[a,b],它的左儿子表示的区间为[a,(a+b)/2],右儿子表示的区间为[(a+b)/2+1,b],最后的叶子结点数目为N,与数组下标对应。
线段树作用:线段树一般包括建立、查询、插入、更新等操作,建立规模为N的时间复杂度为O(NlogN),其他操作时间复杂度O(logN)。对于求一个数组中某区间和或者更改某个值起到了优化的作用。
原数组

完全二叉树(采用数组形式构造)

left_node = 2 * node + 1;
right_node = 2 * node + 2;
线段树java实现
- 线段树构造
- 修改线段树上某结点的值
- 获取数组某个给定区间arr[L…R]中数据总和
// 线段树 java 实现
public static class SegmentTree{
// 线段树的每一个结点 tree[idx] 都理解为 原数组arr[start...end] 的一段区间
// tree[idx] 的值为 arr[start...end] 这段区间的数值的总和
final int MAX_LEN = 100;
int[] arr; // 定长数组
int[] tree; // 定长数组,线段树(完全二叉树表示)数组,存储该结点所有子树的和
int size;
public SegmentTree() {
arr = new int[MAX_LEN];
tree = new int[4*MAX_LEN];
size = 0;
}
public SegmentTree(int[] arr) {
this.arr = arr;
this.tree = new int[4*arr.length]; // arr.length为tree的叶结点个数,tree数组开四倍大小(防止越界)
build_tree(0, 0, arr.length-1);
size = arr.length;
}
// 构造线段树
public void build_tree(int node, int start, int end) {
// arr 为原数组,tree为完全二叉树的一维数组实现,node为当前节点,start为起始结点,end为结束结点
// node 结点对应的数组下标为arr[start...end]
if(start == end) // 只有一个元素时插入二叉树中
tree[node] = arr[start];
else {
// 采用分治法按下标拆分数组元素
int mid = (start + end)/2;
int left_node = 2 * node + 1;
int right_node = 2 * node + 2;
build_tree(left_node, start, mid); // 为左结点构造子树,对应arr[start...mid]
build_tree(right_node, mid+1, end); // 为右结点构造子树,对应arr[mid+1...end]
tree[node] = tree[left_node] + tree[right_node]; // 树结点的值 = 左子树结点值 + 右子树节点值
}
}
// 修改线段树上某结点的值
// 递归寻找某个结点,找到结点后沿着递归方向修改该结点父结点的值
public void update_tree(int node, int start, int end, int idx, int val) {
// arr 为原数组,tree为线段树完全二叉树数组,node为当前访问结点,start为当前访问结点对应区间的起始位置,end为结束位置
// idx 为需要修改数据的下标,val为修改的值。(可理解为修改arr[idx] = val)
if(start == end ) {
// 若start == end,则当前的 start == end == idx (因为idx 位于 start 与 end 之间,即找到了下标为idx的节点)
// 此时修改原始数组 arr[idx] = val 以及 线段树叶结点 tree[node] = val
arr[idx] = val;
tree[node] = val;
}else {
// 利用分治法递归修改包含idx结点父结点(包含idx的区间)的值
int mid = (start + end) / 2;
int left_node = 2 * node + 1;
int right_node = 2 * node + 2;
if(idx >= start && idx <=mid)
update_tree(left_node,start,mid,idx,val); // 搜索左子树
else
update_tree(right_node,mid+1,end,idx,val); // 搜索右子树
tree[node] = tree[left_node] + tree[right_node]; // 修改父结点的值(重构父结点)
}
}
// 获取arr[L..R]中数据总和
public int query_tree(int node, int start, int end, int L, int R) {
// arr 为原数组,tree为对应线段树,node为当前访问结点,start为该结点对应区间的起始结点,end为结束结点。L为查询区间的左结点,R为查询结点的右结点。
// query_tree 作用是在数组 arr[start... end] 内查找区间 arr[L...R] 中所有元素和
if(R < start || L > end)return 0; // 若 所查询区间范围arr[L..R] 与 所访问结点的区间arr[start..end] 不相交,则返回0(不包含任何结点)
else if(L <= start && R >= end) { // 若 所查询区间范围arr[L..R] 包含 所访问结点的区间arr[start..end]
return tree[node]; // 返回tree[node](包含该结点对应区间所有元素,即返回元素和)
}else { // 若 所访问结点的区间arr[start..end] 包含 查询区间范围arr[L..R]
// 分治法递归划分左右子树,并对所访问结点的左右子树查询
int mid = (start + end)/2;
int left_node = 2 * node + 1;
int right_node = 2 * node + 2;
int sum_left = query_tree(left_node, start, mid, L, R); // 查找左子树中包含区间arr[L..R]元素和
int sum_right = query_tree(right_node, mid+1, end, L, R); // 查找右子树中包含区间arr[L..R]元素和
return sum_left + sum_right; // 元素和相加
}
}
public void print_arr_and_tree() {
// for(int i=0;i
// System.out.print(arr[i] + " ");
// System.out.println("");
for(int i=0;i<tree.length;i++)
System.out.print(tree[i] + " ");
System.out.println("");
}
}
区域和查询
题目描述
给定一个整数数组 nums,求出数组从索引 i 到 j (i ≤ j) 范围内元素的总和,包含 i, j 两点。
update(i, val) 函数可以通过将下标为 i 的数值更新为 val,从而对数列进行修改。
示例:
Given nums = [1, 3, 5]
sumRange(0, 2) -> 9
update(1, 2)
sumRange(0, 2) -> 8
算法思路
使用线段树数据结构
程序代码
// 307. 区域和检索 - 数组可修改
// 给定一个整数数组 nums,求出数组从索引 i 到 j (i ≤ j) 范围内元素的总和,包含 i, j 两点。
// update(i, val) 函数可以通过将下标为 i 的数值更新为 val,从而对数列进行修改。
public static class NumArray {
SegmentTree st ;
int length = 0;
public NumArray(int[] nums) {
st = new SegmentTree(nums);
this.length = nums.length;
// st.print_arr_and_tree();
}
public void update(int i, int val) {
st.update_tree(0, 0, length-1, i, val);
// st.print_arr_and_tree();
}
public int sumRange(int i, int j) {
return st.query_tree(0, 0, length-1, i, j);
}
}
第十一章 其他
- 位运算
- 补码
用补码的形式表示负数:先按正数转换,再取反+1
要将十进制的-10用二进制表示,先将10用二进制表示:
0000 0000 0000 1010
取反:
1111 1111 1111 0101
加1:
1111 1111 1111 0110
所以,-10的二进制表示就是:1111 1111 1111 0110
- 按位与&
A & 1 = A
A & 0 = 0
只有当相应位上的数都是1时,该位才取1,否则该为为0。
将10与-10进行按位与(&)运算:
0000 0000 0000 1010
1111 1111 1111 0110
-----------------------
0000 0000 0000 0010
所以:10 & -10 = 0000 0000 0000 0010
- 按位或|
只要相应位上存在1,那么该位就取1,均不为1,即为0。
将10与-10进行按位或(|)运算:
0000 0000 0000 1010
1111 1111 1111 0110
-----------------------
1111 1111 1111 1110
所以:10 | -10 = 1111 1111 1111 1110
- 按位异或^
只有当相应位上的数字不相同时,该为才取1,若相同,即为0。
将10与-10进行按位异或(^)运算:
0000 0000 0000 1010
1111 1111 1111 0110
-----------------------
1111 1111 1111 1100
所以:10 ^ -10 = 1111 1111 1111 1100
- 取反~
每个位上都取相反值。
对10进行取反(~)运算:
0000 0000 0000 1010
---------------------
1111 1111 1111 0101
所以:~10 = 1111 1111 1111 0101
- 左移<<
进行左移运算,用来将一个数各二进制位全部向左移动若干位。
左移一位的结果就是原值乘2,左移两位的结果就是原值乘4。
对10左移2位(就相当于在右边加2个0):
0000 0000 0000 1010
--------------------
0000 0000 0010 1000
所以:10 << 2 = 0000 0000 0010 1000 = 40
- 右移>>
进行右移运算,用来将一个数各二进制位全部向右移动若干位。
右移一位的结果就是原值除2,左移两位的结果就是原值除4。
对10右移2位(就相当于在左边加2个0):
0000 0000 0000 1010
--------------------
0000 0000 0000 0010
所以:10 >> 2 = 0000 0000 0000 0010 = 2
- 典型例题
二维数组的查找
题目描述
在一个二维数组中(每个一维数组的长度相同),每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序。请完成一个函数,输入这样的一个二维数组和一个整数,判断数组中是否含有该整数。
算法思路
矩阵是有序的,从左下角开始遍历。向上数字递减,向右数字递增,因此从左下角开始查找(可以减少四种移动方式中两种可能性)
当要查找数字比左下角大的时候,右移;
当要查找数字比左下角小的时候,上移.
程序代码
public boolean Find(int target, int [][] array) {
// 矩阵是有序的,从左下角开始遍历。向上数字递减,向右数字递增
// 因此从左下角开始查找(可以减少四种移动方式中两种可能性)
// 当要查找数字比左下角大的时候,右移;
// 当要查找数字比左下角小的时候,上移.
if(array == null || array.length == 0)return false;
int row = array.length-1;
int col = array[0].length-1;
int idx_x = row;
int idx_y = 0;
while(idx_x >=0 && idx_y <= col) {
if(target == array[idx_x][idx_y])return true; // 查找到target,返回true
if(target < array[idx_x][idx_y]){
idx_x--; // 查找数字较小,则上移
}else {
idx_y++;// 查找数字较大,则右移动
}
}
return false; // 遍历结束仍未查找到target,返回false
}
二进制中1的个数
题目描述
输入一个整数,输出该数二进制表示中1的个数。其中负数用补码表示。
程序代码
// 11.二进制中1的个数
// 输入一个整数,输出该数二进制表示中1的个数。其中负数用补码表示。
public int NumberOf1(int n) {
// 方式1:从n的2进制形式最右边开始右移判断是不是1(可能陷入死循环)
// 这种方式用于负数运算可能陷入死循环,因为负数右移的时候,最高位补的是1,本题求1的个数,此时会有无数个1
// int count = 0;// 二进制表示中1的个数
// while(n!=0) {
// if((n & 1) == 1) count++;// 如果 n & 1 = 1(1和n进行位与运算),表示n的二进制表示数最后一位为 1,则二进制表示中 1 的个数++
// n = n >> 1;// n 的二进制表示数 整体右移一位(相当于/2)
// }
// return count;
// 方式2:从1开始不断左移动判断是不是1
int count = 0;
int flag = 1; //从1开始左移
while(flag != 0) {
if((n & flag) != 0)count++; // 从右向左遍历n的每一位
flag = flag << 1; // 位数指示器左移
}
return count;
}
调整数组顺序使奇数位于偶数前面
题目描述
输入一个整数数组,实现一个函数来调整该数组中数字的顺序,使得所有的奇数位于数组的前半部分,所有的偶数位于数组的后半部分,并保证奇数和奇数,偶数和偶数之间的相对位置不变。
程序代码
// 13.调整数组顺序使奇数位于偶数前面
// 输入一个整数数组,实现一个函数来调整该数组中数字的顺序,
// 使得所有的奇数位于数组的前半部分,所有的偶数位于数组的后半部分,
// 并保证奇数和奇数,偶数和偶数之间的相对位置不变。
public void reOrderArray(int [] array) {
// 1. 遍历数组中的每个数字(数组前半段全是奇数,后半段全是偶数)
// 2. 若遍历到奇数,则向前遍历插入到第一个遇到的奇数后面
boolean isInsert = false;
for (int i = 0;i<array.length;i++) {
if(array[i]%2 == 1) { //若遍历到奇数
int temp = array[i];
for(int j=i-1;j>=0;j--)
if(array[j]%2==1) { // 若遇到奇数,则停止遍历,并插入该奇数后
array[j+1] = temp;
isInsert = true;
break;
}else { // 若遇到偶数,则将偶数向后移动
array[j+1] = array[j];
}
if(!isInsert)array[0] = temp;
}
}
}
丑数
题目描述
把只包含质因子2、3和5的数称作丑数(Ugly Number)。例如6、8都是丑数,但14不是,因为它包含质因子7。 习惯上我们把1当做是第一个丑数。求按从小到大的顺序的第N个丑数。
程序代码
Queue<Integer> multi_2 = new LinkedList<Integer>();
Queue<Integer> multi_3 = new LinkedList<Integer>();
Queue<Integer> multi_5 = new LinkedList<Integer>();
List<Integer> min_array = new ArrayList<Integer>();// 存储1..index的丑数
public int GetUglyNumber_Solution(int index) {
// 暴力穷举
// 定义3个队列,分别为*2队列*3队列*5队列
// 丑数一定为 2^x*3^y*5^z
// 即丑数均是从这3个队列中计算所得,即任一丑数通过*2,*3,*5计算所得
// 丑数数组为逐一求得丑数的集合,将丑数最后一个丑数*2,*3,*5并放入队列(可能最小值队列)
// 最小值为三个3队列中队首元素中最小值,逐一比较,若为最小值则将队列出队,并将最小值存入丑数数组
min_array.add(1); // 第一个丑数为1
if(index<1)return 0;
for(int i=0;i<index;i++)
putUglyNumberInArray(i);
return min_array.get(index-1);
}
public void putUglyNumberInArray(int i) {
// 将第 i 个丑数放入数组中
int lastUglyNumber = min_array.get(min_array.size()-1);// 获取丑数数组最后一个数
multi_2.offer(lastUglyNumber*2);
multi_3.offer(lastUglyNumber*3);
multi_5.offer(lastUglyNumber*5);
min_array.add(chooseMinValueOfThreeQueue());
}
public Integer chooseMinValueOfThreeQueue() {
int min_2 = multi_2.peek();
int min_3 = multi_3.peek();
int min_5 = multi_5.peek();
int min_value = min_2<min_3?(min_2<min_5?min_2:min_5):(min_3<min_5?min_3:min_5);
if(min_value == min_2)multi_2.poll();
if(min_value == min_3)multi_3.poll();
if(min_value == min_5)multi_5.poll();
return min_value;
}
正则表达式匹配
题目描述
请实现一个函数用来匹配包括’.‘和’‘的正则表达式。模式中的字符’.‘表示任意一个字符,而’'表示它前面的字符可以出现任意次(包含0次)。 在本题中,匹配是指字符串的所有字符匹配整个模式。例如,字符串"aaa"与模式"a.a"和"abaca"匹配,但是与"aa.a"和"ab*a"均不匹配
程序代码
// 51.正则表达式匹配[模拟思想]
// 请实现一个函数用来匹配包括'.'和'*'的正则表达式。
// 模式中的字符'.'表示任意一个字符,而'*'表示它前面的字符可以出现任意次(包含0次)。
// 在本题中,匹配是指字符串的所有字符匹配整个模式。
// 例如,字符串"aaa"与模式"a.a"和"ab*ac*a"匹配,但是与"aa.a"和"ab*a"均不匹配
public boolean match(char[] str, char[] pattern) {
// 当模式中的第二个字符不是“*”时:
// 1、如果字符串第一个字符和模式中的第一个字符相匹配,那么字符串和模式都后移一个字符,然后匹配剩余的。
// 2、如果 字符串第一个字符和模式中的第一个字符相不匹配,直接返回false。
//
// 而当模式中的第二个字符是“*”时:
// 如果字符串第一个字符跟模式第一个字符不匹配,则模式后移2个字符,继续匹配。如果字符串第一个字符跟模式第一个字符匹配,可以有3种匹配方式:
// 1、模式后移2字符,相当于x*被忽略;
// 2、字符串后移1字符,模式后移2字符;
// 3、字符串后移1字符,模式不变,即继续匹配字符下一位,因为*可以匹配多位;
if (str == null || pattern == null) {
return false;
}
int strIndex = 0;
int patternIndex = 0;
return matchCore(str, strIndex, pattern, patternIndex);
}
public boolean matchCore(char[] str, int strIndex, char[] pattern, int patternIndex) {
//有效性检验:str到尾,pattern到尾,匹配成功
if (strIndex == str.length && patternIndex == pattern.length) {
return true;
}
//pattern先到尾,匹配失败
if (strIndex != str.length && patternIndex == pattern.length) {
return false;
}
//模式第2个是*,且字符串第1个跟模式第1个匹配,分3种匹配模式;如不匹配,模式后移2位
if (patternIndex + 1 < pattern.length && pattern[patternIndex + 1] == '*') {
if ((strIndex != str.length && pattern[patternIndex] == str[strIndex]) || (pattern[patternIndex] == '.' && strIndex != str.length)) {
return matchCore(str, strIndex, pattern, patternIndex + 2)//模式后移2,视为x*匹配0个字符
|| matchCore(str, strIndex + 1, pattern, patternIndex + 2)//视为模式匹配1个字符
|| matchCore(str, strIndex + 1, pattern, patternIndex);//*匹配1个,再匹配str中的下一个
} else {
return matchCore(str, strIndex, pattern, patternIndex + 2);
}
}
//模式第2个不是*,且字符串第1个跟模式第1个匹配,则都后移1位,否则直接返回false
if ((strIndex != str.length && pattern[patternIndex] == str[strIndex]) || (pattern[patternIndex] == '.' && strIndex != str.length)) {
return matchCore(str, strIndex + 1, pattern, patternIndex + 1);
}
return false;
}
表示数值的字符串
题目描述
请实现一个函数用来判断字符串是否表示数值(包括整数和小数)。例如,字符串"+100",“5e2”,"-123",“3.1416"和”-1E-16"都表示数值。 但是"12e",“1a3.14”,“1.2.3”,"±5"和"12e+4.3"都不是。
程序代码
// 52.表示数值的字符串
// 请实现一个函数用来判断字符串是否表示数值(包括整数和小数)。
// 例如,字符串"+100","5e2","-123","3.1416"和"-1E-16"都表示数值。
// 但是"12e","1a3.14","1.2.3","+-5"和"12e+4.3"都不是。
public boolean isNumeric(char[] str) {
// 法一:直接采用正则表达式求解
// [\\+\\-]? -> 正或负符号出现与否
// \\d* -> 整数部分是否出现,如-.34 或 +3.34均符合
// (\\.\\d+)? -> 如果出现小数点,那么小数点后面必须有数字;
// 否则一起不出现
// ([eE][\\+\\-]?\\d+)? -> 如果存在指数部分,那么e或E肯定出现,+或-可以不出现,
// 紧接着必须跟着整数;或者整个部分都不出现
// String string = String.valueOf(str);
// return string.matches("[\\+\\-]?\\d*(\\.\\d+)?([eE][\\+\\-]?\\d+)?");
// 法2:对字符串中的每个字符进行判断分析,基本格式:+/- A.B e(E) +/- C
// e(E)后面只能接数字,并且不能出现2次
// 对于+、-号,只能出现在第一个字符或者是e的后一位
// 对于小数点,不能出现2次,e后面不能出现小数点
boolean hasPoint = false;
boolean hasE = false;
for(int i=0;i<str.length;i++) {
if(i == 0) { //首字符单独处理,必须为数字或者+/-
if(!(isInteger(str[i]) || str[i]=='+' || str[i] == '-'))return false;
}else if(str[i] == '.') {
if(hasPoint || hasE)return false; // 小数点只能出现一次且只能出现在指数符号前面
hasPoint = true;
}else if(str[i] == 'E' || str[i] == 'e') {
i++;
if(hasE || i==str.length || !(isInteger(str[i]) || str[i]=='+' || str[i] == '-'))return false;
hasE = true;
}else if(!isInteger(str[i])) {
return false;
}
}
return true;
}
public boolean isInteger(Character c) {
if(c >= '0' && c<='9')return true;
else return false;
}