EasyPR车牌识别学习总结
之前一直在学习opencv相关的知识,opencv库的学习告一段落,因此想找一个具体的项目,来学习OpenCV在具体项目开发中的使用,加深算法理解,同时了解商业项目开发的具体细节,以及一个真正项目的代码书写规则等等。之前的OpenCV学习,主要集中于单个函数的理论学习,以及调用某一个函数进行图像处理,但是并没有将多种图像处理函数整合起来,完成一个稍大型的计算机视觉方面的工程。基于此,我在CSDN博客上找到一个EasyPR车牌识别项目,该项目在GitHub上有一整套源码开源,获得了5000+star,同时在博客园,CSDN博客上有一系列完整的博文,对easyPR项目的流程,原理进行详细周到的解读。非常适合我这种初次接触大型项目的新手。于是我开始了该项目的学习。
EasyPR车牌识别分为了两个过程:即车牌检测(Plate Detection)和字符识别(Chars Recognition)两个过程。
- 车牌检测(Plate Detection):对一个包含车牌的图像进行分析,最终截取出包含车牌的一个图块。这个步骤又可以分为两个部分:
- 车牌候选区域定位。顾名思义,这一个是采用传统图像处理算法,根据车牌的特征进行车牌区域的提取,一开始我们采用车牌的垂直边缘特征,进行车牌区域的定位;之后我们又加入了基于颜色判别的车牌区域定位,最后我们又引入了基于字符识别的车牌区域定位,通过三种不同的角度,也就是全面的使用的车牌区域的特性进行车牌定位,可以有效的提高车牌检测率。主要目的是降低了在车牌识别过程中的计算量。如果直接对原始的图像进行车牌识别,会非常的慢,而且未必能成功检测出车牌。
- 车牌区域最终SVM判别:在本系统中,我们使用SVM去判别截取的图块是否是真的“车牌”。即将我们得到的车牌候选区域送入SVM,如果是车牌,输出“1”,如果不是,输出“0”。
- 字符识别(Chars Recognition):这个步骤的主要目的就是从上一个车牌检测步骤中获取到的车牌图像,进行光学字符识别(OCR)这个过程。其中用到的机器学习算法是著名的人工神经网络(ANN)中的多层感知机(MLP)模型。
车牌识别项目最核心的部分就是车牌区域的检测,基本上只要正确识别车牌区域,接下来只需将该区域送入字符识别的ANN网络,就可以输出准确的车牌字符。车牌区域的检测包括的是车牌定位,SVM训练,车牌判断三个过程,见下图。
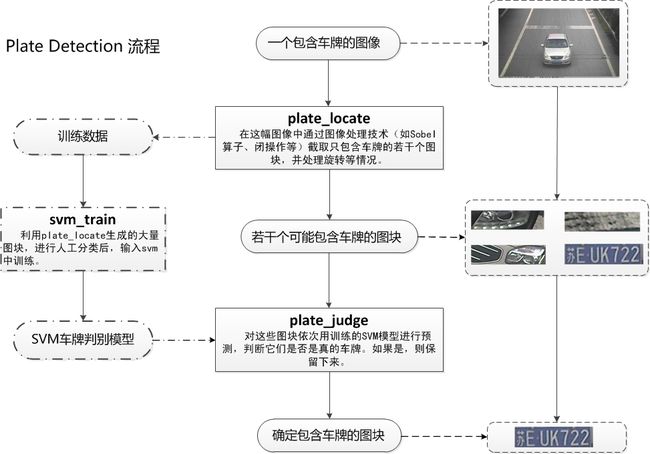
下面我来依次介绍该项目的具体细节:
1、基于垂直边缘的车牌定位
总体识别思路是:如果我们的车牌没有大的旋转或变形,那么其中必然包括很多垂直边缘(这些垂直边缘往往缘由车牌中的字符),如果能够找到一个包含很多垂直边缘的矩形块,那么有很大的可能性它就是车牌。
该方法是在灰度图像上进行操作,具体流程如下:
- 对图像进行高斯滤波,图像会变的模糊(要掌握高斯模糊的计算方法)。这步的作用是为接下来的Sobel算子去除干扰的噪声。该步骤是必须的,能有效避免非车牌区域被识别为车牌候选区域,减少后期SVM判别耗费时间;
- 对模糊后的图像进行灰度化,转换成灰度图像利于使用各种专用的算法,但失去了真实世界中辨别的最重要工具---色彩的区分。所以才有了后期版本基于颜色车牌定位的改进;
- 对图像进行Sobel运算(掌握Sobel算子的运算原理,调用方式),仅对图像做水平方向求导,得到的是图像的一阶水平方向导数,从而检测出垂直边缘。这步过后,车牌被明显的区分出来。(我们不使用水平边缘,水平边缘多也许有利于生成更精确的轮廓,但是由于有些车子前端太多的水平边缘了,例如车头排气孔,标志等等,很多的水平边缘会误导我们的连接结果)
- 对图像进行二值化。将灰度图像(每个像素点有256个取值可能)转化为二值图像,对图像的每个像素做一个阈值处理。一般使用OTSU自适应阈值方法(掌握OTSU方法),不用我们人为定义阈值,为后续的形态学操作做准备;
- 使用闭操作(掌握形态学基本操作)。模板:3*17;将车牌字母连接成为一个连通域,便于取轮廓。闭操作就是对图像先膨胀,再腐蚀。闭操作的结果一般是可以将许多靠近的图块相连称为一个无突起的连通域。在我们的图像定位中,使用了闭操作去连接所有的字符小图块,然后形成一个车牌的大致轮廓;在闭操作处理中要注意矩形模板的尺寸选取,调用闭操作的方法是首先建立矩形模板,矩形是用来覆盖以中心像素的所有其他像素,中国车牌有一个特点,就是表示城市的字母与右边相邻的字符距离远大于其他相邻字符之间的距离。如果你设置的不够大,结果导致左边的字符与右边的字符中间断开了,如果设置的太大,会导致闭操作连接不该连接的部分。
- 求出图中所有的轮廓(掌握求轮廓原理)。将连通域的外围勾画出来,便于形成外接矩形。这个算法会把全图的轮廓都计算出来,因此要进行筛选。
- 对轮廓求最小外接矩形,然后验证,不满足条件的淘汰。两个条件:一是计算最大和最小的宽高比rmax、rmin。判断矩形的r是否满足在rmax、rmin之间。二是设定一个面积最大值max与面积最小值min。判断矩形的面积area是否满足在max与min之间。 中国车牌的一般大小是440mm*140mm,面积为440*140,宽高比为3.14。个人觉得根据区域的大小判断是否车牌其实并不合理,因为你并不知道你的车牌到底占了图像多少比例,我们假设原图像是我们离车牌很近的距离拍摄的,那么图像中会有很大一部分都是车牌,但根据面积条件,机器会把它排除,基于面积判别,或者说得更直观些,基于区域像素个数来判别车牌可能只适用于,在相机和车辆固定距离内,拍摄到的车牌照片。这里采用宽高比最为合理;
- 角度判断与旋转(因为我们假定车牌是水平放置,这样才有垂直边缘的方法)。把倾斜角度大于阈值(如正负30度)的矩形舍弃。余下的矩形进行微小的旋转,使其水平。这里也是有一个假设条件,即相机与车辆保持水平,应用场景是车辆出入口禁或交通检测,如果是生活中我们随手拍的照片,可能车牌方向本身就不是水平的,这样角度判别也就失去了意义。
- 统一尺寸。上步得到的图块尺寸是不一样的。为了进入机器学习模型,需要统一尺寸。统一尺寸的标准宽度是136,长度是36。这个标准是对千个测试车牌平均后得出的通用值。
下图是基于垂直边缘的车牌定位的流程:

1、二维高斯函数:![]()
2、OTSU:最大类间方差: g=wo * (uo - u) * (uo - u) + w1 * (u1 - u) * (u1 - u)
从L个灰度级遍历T,使得T为某个值的时候,前景和背景的方差最大, 则这个T 值便是我们要求得的阈值。
from:https://blog.csdn.net/qq_30815237/article/details/86689519
3、腐蚀:移动结构B,如果结构B与图像A的交集完全属于A的区域内,则保存该位置点,所有满足条件的点构成腐蚀的结果。
膨胀:将结构B在A上进行卷积操作,移动B的过程中,与A存在重叠位置,所有B与A存在交集的位置为膨胀结果。
不足:1、闭运算涉及到模板尺寸的设置,所以要求车牌图片的像素个数一定,可以用于视频车牌检测,这样,汽车由远及近,必定有一帧图像可以检测出车牌,对于单张图像,则需要指定的车牌像素大小范围;
2、不适合除车牌外还有其他垂直边缘的车型。
改进:1、加入直方图均衡,增强图像的总体对比度,熵最大?实际应用时并不理想,车牌上有一些斑点,均衡后增强了这些斑点。
2、针对还有其他垂直边缘的车型的情况,采用颜色定位方法
3.1、针对闭运算的模板尺寸的选取,一般选取一个较小的模板,将3*17改为3*10:
在进行形态学处理后,求出外接矩形框,如果设置模板的宽度大,但它可能会连接别的区域,改进是:将模板宽度设置小一点这样车牌分裂为两个矩形框,根据宽高比找到属于车牌后半段的矩形框,然后增加一个滑动的窗口(滑动距离按比例),向右搜索,找到一个框,对其进行合并。
3.2、检测到矩形框后,再进行浸水填充,还可以有效解决,检测不到中文字符的情况。(经比较这两种方法,还是浸水填充好使)
方法一:步骤:假定我们检测出割裂开的车牌区域,去除矩形框面积阈值判别条件,仅采用矩形框宽高比阈值(三种宽高比:整个车牌,左半个车牌,右半个车牌),保留这三种,对右半个车牌区域,往左搜索是否有左半个车牌,有的话就合并。
方法二:闭操作之后,求轮廓,外接矩形,角度阈值滤除,然后对所有矩形框分别做浸水填充,填充后得到的矩形框做宽高比阈值判别(整个车牌)。浸水填充不仅可以解决车牌隔离问题,还可以对车牌区域进行更精确的的定位,有助于SVM判别。
2、基于颜色的车牌定位
Sobel法最大的问题就在于面对垂直边缘交错的情况下,无法准确地定位车牌,为了解决这个问题,使用颜色信息进行定位。颜色定位方法一般采用HSV模型(掌握HSV颜色模型),因为RGB颜色模型意味着除了Blue通道,你需要考虑两个变量的配比问题。RGB通道并不能很好地反映出物体具体的颜色信息 ,而HSV空间能够非常直观的表达色彩的明暗,色调,以及鲜艳程度,方便进行颜色之间的对比,比如红色在HSV空间中H维度的范围为0~10和160~180 你跟我说在RGB中它的范围是什么呢?这些问题让选择RGB颜色作为判断的难度大。与RGB颜色模型中的每个分量都代表一种颜色不同的是,HSV模型中每个分量并不代表一种颜色,而分别是:色调(Hue),饱和度Saturation,亮度V。
- H代表颜色特性的分量,取值范围为0~360,从红色开始按逆时针方向计算,红色为0,绿色为120,蓝色为240。
- S分量代表颜色的饱和信息,取值范围为0.0~1.0,值越大,颜色越饱和。
- V分量代表明暗信息
1、H分量是HSV模型中唯一跟颜色本质相关的分量。当H的取值范围在200到280时,这些颜色都可以被认为是蓝色车牌的颜色范畴。当H值在30到80时,颜色的值可以作为黄色车牌的颜色。
2、设置S、V区间排除车身。移动V和S会带来颜色的饱和度和亮度的变化。当V和S都达到最高值,也就是1时,颜色是最纯正的。降低S,颜色越发趋向于变白。降低V,颜色趋向于变黑,当V为0时,颜色变为黑色。我们可以设置一个阈值,假设S和V都大于阈值时,颜色才属于H所表达的颜色。通过S和V的判断可以排除车牌周围车身的干扰:因为很多车牌周身的车身,都是H分量属于200-280,而V分量或者S分量小于0.35的。
颜色定位的完整过程。
- 将图像的颜色空间从RGB转为HSV,在这里由于光照的影响,对于图像使用直方图均衡(掌握原理)进行预处理;
- 依次遍历图像的所有像素,当H值落在200-280之间并且S值与V值也落在0.35-1.0之间,标记为白色像素,否则为黑色像素;(说明OpenCV使用的参数是100-140,因为OpenCV使用0-180的表示范围)
- 对仅有白黑两个颜色的二值图参照原先车牌定位中的方法,使用闭操作,取轮廓等方法将车牌的外接矩形截取出来做进一步的处理。
一般说来,一幅图像需要进行一次蓝色模板的匹配,还要进行一次黄色模板的匹配,以此确保蓝色和黄色的车牌都被定位出来。
颜色定位也有它的不足之处:在色彩充足,光照足够的情况下,颜色定位的效果很好,但是在面对光线不足的情况,或者蓝色车身的情况时,颜色定位的效果很糟糕。碰到失效的颜色定位情况时需要使用原先的Sobel定位法。目前是:使用了颜色定位与Sobel定位结合的方式。首先进行颜色定位,然后根据条件使用Sobel进行再次定位。
不足:对车身是蓝色或黄色的无法检测;对光照有一定要求
改进:1、颜色失效,原文中是转而使用用soble垂直边缘;
2、把形态学操作改为浸水填充
直方图均衡:https://blog.csdn.net/qq_30815237/article/details/89704870
我觉得可以直接对颜色判别作后续处理,即对颜色模板监测得到的二值图像进行矩形判别,浸水填充都是可以的。实测时不是很好用!!因为车牌车身完全一体,找不到准确的种子点位置!!!!!,所以还是老实的使用soble方法,如果还是不好使,那就是下面的方法,MSER!
3、基于字符检测的车牌定位
颜色定位在面对低光照,低对比度的图像时处理效果大幅度下降,颜色本身也是一个不稳定的特征。而光照弱时,边缘也不靠谱了。针对这种现象,增加了一种新的定位方法,文字定位方法。文字定位方法是采用了低级过滤器提取文字,然后再将其组合的一种定位方法。原先是利用在场景中定位文字,在这里利用其定位车牌。使用MSER(最大稳定极值区域)方法。
MSER的基本原理是对一幅灰度图像(灰度值为0~255)取阈值进行二值化处理,阈值从0到255依次递增。阈值的递增类似于分水岭算法中的水面的上升,随着水面的上升,有一些较矮的丘陵会被淹没,如果从天空往下看,则大地分为陆地和水域两个部分,这类似于二值图像。在得到的所有二值图像中,图像中的某些连通区域变化很小,甚至没有变化,则该区域就被称为最大稳定极值区域。这类似于当水面持续上升的时候,有些被水淹没的地方的面积没有变化。它的数学定义为:
![]()
步骤流程:
1、首先通过MSER提取区域。提取出的区域进行一个尺寸判断(判别的是字符尺寸),滤除明显不符合车牌文字尺寸的。
2、把得到的区域送入ann神经网络,输出每个区域属于文字的概率,将概率大于0.9的设为强种子(绿色方框)。靠近的强种子进行聚合,划出一条线穿过它们的中心。一般来说,这条线就是车牌的中间轴线,斜率什么都相同。
3、之后在这条线的附近寻找那些概率低于0.9的弱种子(蓝色方框)。由于车牌的特征,这些蓝色方框应该跟绿色方框距离不太远,同时尺寸也不会相差太大。蓝色方框是在绿色方框的左右查找的,有时候,几个绿色方框中间可能存在着一个方框,这可以通过每个方框之间的距离差推出来,这就是橙色的方框。全部找完以后。绿色方框加上蓝色与橙色方框的总数代表着目前在车牌区域中发现的文字数。
4、有时这个数会低于7(中文车牌的文字数),这是因为有些区域即便通过MSER也提取不到(例如非常不稳定或光照变化大的),另外很多中文也无法通过MSER提取到(中文大多是不连通的,MSER提取的区域基本都是连通的)。所以下面需要再增加一个滑动窗口(红色方框)来寻找这些缺失的文字或者中文,如果分类器概率大于某个阈值,就可以将其加入到最终的结果中。最后把所有文字的位置用一个方框框起来,就是车牌的区域。
改进:对mser文字获选区域进行连通域分析,求取最小包含矩形框,DNN判别,对矩形框进行合并(取置信度最大的矩形框为起点,往左往右扫描,比较(x,y,w,h)阈值,或者矩形框的阈值)。
或者对mser文字获选区域进行连通域分析,求取最小包含矩形框,矩形宽高判别,然后DNN判别,对判别后的矩形使用浸水填充。(但是浸水填充对光照不好的情况,不太适用)。

效果确实很好,在极低光照下也能找到车牌,但最后未必能识别字符啊.....
实际商用时,可能创造更好的光照条件才是王道。。。
通过三种方法得到的候选区域,送入SVM进行判别,当有几个定位区域重叠时,可以根据它们的置信度(也是SVM车牌判断模型得出的值)来取出其中最大概率准确的一个(掌握NMS)。这样,不同定位方法,例如Sobel与Color定位的同一个区域,只有一个可以保留。
偏斜扭转
定位结束后,我们就可以将候选区域,送入SVM进行判别?并不是,在这中间需要对得到的候选区域进行处理,才能送入SVM进行判别。我们的车牌图片可能是从不同的视角拍摄到的,在定位以后,我们如何把偏斜过来的车牌扭正呢?这个过程叫做偏斜扭转过程。核心是opencv的仿射变换函数。
偏斜扭转就是对图像的观察视角进行了一个转换。
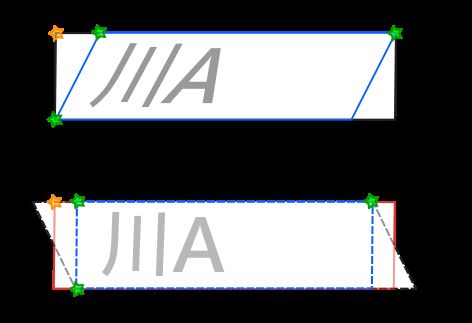
我们要解决的问题包括两类,第一类是正视角的倾斜车牌,第二类是偏斜视角的车牌。正视角的倾斜车牌的特点就是在RotataedRect内部,车牌部分仍然是个矩形。偏斜视角的图片的观察角度是非正方向的,这类图块的特点是在 RotataedRect内部,车牌部分不再是个矩形,而是一个平行四边形。


整个处理流程包括下面四步:
1.感兴趣区域ROI的截取;我们可以使用RotataedRect的boudingRect()方法。返回一个RotataedRect的最小外接矩形,而且这个矩形是一个Rect。因此将这个Rect传递给Mat(Rect...)方法就可以截取出原图的ROI图块,并获得对应的ROI图像。注意:计算一个RotataedRect的最小外接矩形Rect时,它可能会给你一个负坐标,或者是一个超过原图片外界的坐标。于是当你把Rect作为参数传递给Mat(Rect ...)的话,它会提示你所要截取的Rect中的坐标越界了!
2.角度判断,根据第一步得到的RotataedRect外接矩形,可以得到该矩形的倾斜度,如果矩形的斜率在-5到5度之间,就不在对其进行旋转处理,该角度较小,不会影响SVM判别;
3.偏斜判断,如果得到的RotataedRect外接矩形的倾斜度较大,则对其进行偏斜判断,判断之前,先对该区域进行旋转处理,旋转角度就是RotataedRect外接矩形的旋转角,这里要注意对该ROI区域进行旋转操作前,先对该ROI进行边框拓展,防止ROI图像旋转后越界导致像素丢失,然后再对旋转后的区域进行车牌提取,使用getRectSubPix方法在被旋转后的图像中截取一个正的矩形图块出来这时就可以用一个Rect外接矩形提取出车牌区域了。偏斜判断的依据主要是观察车牌区域是矩形,还是平行四边形。先对图像二值化(如何二值化?),判断二值化图像中白色的部分是平行四边形。
一种方法是:从图像中选择一些特定的行。计算在这个行中,第一个全为0的串的长度,就是平行四边形斜边上某个点距离外接矩形的长度。如果是白色图形是矩形的话,这些串的大小应该是相等或者相差很小的,相反如果是平行四边形的话,那么这些串的大小应该不等,并且呈现一个递增或递减的关系。通过这种不同,我们就可以判断车牌区域里的图形,究竟是矩形还是平行四边形。
另一种方法:用白色区域的轮廓来确定平行四边形的四个点,然后用这四个点来计算斜率。步骤:先求出二值图像的轮廓,用同样的方法求出端点,这样算出来的斜率的可能鲁棒性更好。
偏斜判断的另一个重要作用就是,计算平行四边形倾斜的斜率,根据平行四边形斜边上某个点距离外接矩形的长度,即可求得斜率,用于下一步仿射变换。
4.仿射变换。下面要做的工作就是把平行四边形扭正成一个矩形。我们使用warpAffine函数把车牌区域中的平行四边形映射为一个矩形。选取矩形车牌区域中的平行四边形车牌的三个关键点,然后再确定了我们希望将车牌扭正成的矩形的三个关键点的话,我们就可以实现从平行四边形车牌到矩形车牌的扭正,这里要注意:视框的偏移问题。倘若我们想把车牌全部显示的话,视框往右偏移一段距离,是不是就可以解决这个问题呢?为保证新的视框中心能够正好与车牌的中心重合,我们可以选择偏移xidff/2长度。正如下图所显示的一样。
重新计算的映射点坐标为下:
plTri[0] = Point2f(0 + xiff, 0);
plTri[1] = Point2f(width - 1, 0);
plTri[2] = Point2f(0, height - 1);
dstTri[0] = Point2f(xiff/2, 0);
dstTri[1] = Point2f(width - 1 - xiff + xiff/2, 0);
dstTri[2] = Point2f(xiff/2, height - 1);

SVM判别(原理推导,重中之重)
简单来说,车牌判断模块就是将候选车牌的图片一张张地输入到SVM模型中,然后问它,这是车牌么?如果SVM模型回答不是,那么就继续下一张,如果是,则把图片放到一个输出列表里。最后把列表输入到下一步处理。由于EasyPR使用的是列表作为输出,因此它可以输出一副图片中所有的车牌。SVM模型处理的是最简单的二值分类问题。
首先我们读取这幅图片,然后把这幅图片转为1行的行向量,该行向量就是待预测数据的特征,也称之为features。在这里,我们输入的特征是图像全部的像素。除了全部像素以外,也可以有其他的特征,如LBP特征(掌握),或者直方统计函数:先把图像二值化,然后统计图像中一行元素中1的数目,由于输入图像有36行,因此有36个值,再统计图像中每一列中1的数目,图像有136列,因此有136个值,两者相加等于172。接着调用svm的方法predict;perdict方法返回的值是1的话,就代表是车牌,否则就不是。
输入数据的特征不再是三原色的像素值了,而是抽取过的一些特征。直接把图像全部像素作为特征输入是最低级的做法。
既然使用SVM,就必然要用一下它的核技巧,本节使用了RBF核(掌握RBF核的原理),它将输入数据的特征维数进行一个维度转换,具体会转换为多少维?这个等于你输入的训练量。假设你有500张图片,rbf核会把每张图片的数据转换为500维的。
![]()
rbf核的使用适用于:当你的数据量很大,但是每个数据量的维度不大时。相反,当你的数据量不多,但是每个数据量的维数都很大时,适合用线型核。如果我们用的是图像的全部像素作为特征,那么根据车牌图像的136×36的大小来看的话,就是4896维的数据,再加上我们输入的是彩色图像,也就是说有R,G,B三个通道,那么数量还要乘以3,也就是14688个维度。这是一个非常庞大的数据量,你可以把每幅图片的数据理解为长度为14688的向量。这个时候,数据维度很大,而数据总数很少,如果用rbf核的效果反而不如无核。
当每个数据的特征改用直方统计,共有172个维度(36行,136列),输入训练的数据有3000张图片,这个场景下,如果用rbf核的话,就会将每个数据的维度转化为与数据总数一样的数量,也就是3000的维度,可以充分利用数据高维化后的好处。
改进:这里我们使用LBP特征,使用RBF核函数
字符识别
字符分割的结果就是将车牌中的所有文字一一分割开来,形成单一的字符块。生成的字符块就可以输入下一步的字符识别部分进行识别。在EasyPR里,字符识别所使用的技术是人工神经网络,也就是ANN。
分割字符有很多种方法。这里使用的是取字符轮廓法。字符分割过程:灰度化->颜色判断->二值化->去铆钉->取轮廓->找外接矩形->截取图块。
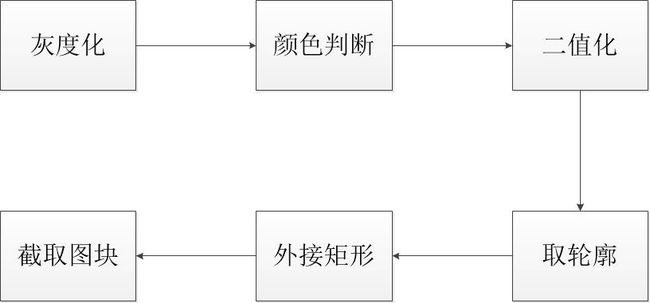
对图像灰度化,进行颜色判断的,这是因为对于蓝色和黄色车牌而言,使用的二值化策略必须不同。获取颜色后,就可以选择不同的参数,使用spatial-ostu替代普通的ostu算法进行二值化,改进了图像分割在面对光照不均匀的图像上的二值化效果。
有些中国的车牌中有柳钉。倘若对一副含有柳钉的图进行二值化,极有可能会出现下图的结果。一些字符图块通过柳钉的原因联系到了一体,那样的话就无法通过取轮廓操作来分割了, 因此在二值化之后,进行去除柳钉的操作:就是依次扫描每行,判断跳变次数。车牌字符所在的行的跳变次数是很多的,而柳钉所在的行就会偏少。随后调用方法findContours取轮廓,成功获取了所有的字符的外接矩形,截取字符块区域。
这里注意:对于中文字符,取轮廓求外接矩形未必奏效,针对这种情况,一般先统计一下所有的外接矩形的面积,大部分字符矩形面积应当大致相同,统计相同面积矩形的个数,如果是7个,说明中文字符已经提取了,如果只有6个,说明中文字符未被提取,从这6个矩形框中选择最左侧的矩形框(省份字符),然后以它为参照,用相同大小的矩形滑动框向左移动特定距离,就是中文字符框,移动的距离可以根据现实中车牌字符间隔比例设置。
改进:使用投影法代替轮廓提取,解决中文字符分割问题。统计每列白色像素的个数,得到一个向量vertical_pos。根据垂直投影求出来每个字符的边界值进行单个字符切割。阈值很好定,因为我们现在的车牌大小是36*136.min_range设为3(这个不好用如“I”),min_thresh设为7。阈值小些没关系,假设非字符列中都是0值。
for (int i = 0; i < vertical_pos.size(); i++) {
if (vertical_pos[i] >= min_thresh && begin == 0)
begin = i;
else if (vertical_pos[i] >= min_thresh && begin != 0)
continue;
else if (vertical_pos[i] < min_thresh && begin != 0)
{
end = i;
if (end - begin >= min_range) {//该判断一行字符应具有的最小heigth
char_range range;
range.begin = begin;
range.end = end;
peek_range.push_back(range);
begin = 0;
end = 0;
}
ANN判别
字符分割完成后,将7个字符块送入ANN模型,进行判别。这里的ANN模型是一个3层的多层感知器(掌握),全连接,只有一个隐藏层,输入层有120个神经元,表示一个样本是由120个特征值组成的特征向量;隐藏层40神经元;输出层的神经元等于需要分类的个数,即65个字符。虽然结构很简单,但对于字符识别已经足够了。
同SVM输入一样,单纯输入图像像素是很low的方式,这里也是,先对字符块进行特征提取,对于10*10的非中文字符features个数为 :10+10+10*10=120,10个水平投影,10个垂直投影,100个像素行累加和特征。将待判断的字符特征输入ANN,ANN输出65个分数,最大分数对应的几位判断得到的字符。
使用逻辑激活函数。
至此,EasyPR的学习告一段落。。。。收获多多,感谢开源!!!
除此之外我还了解学习了其他关于车牌识别的方法,比如ababoost+haar特征级联器、faster-RCNN、英特尔在OpenVINO模型加速库中设计了一个全新的车牌识别模型用于识别各种车牌包括中文车牌识别。OpenVINO车牌识别网络详解