Real-Time Neural Style Transfer for Videos(译)—实时的视频风格迁移
Real-Time Neural Style Transfer for Videos
摘要
最近的研究表明前馈卷积网络在图像风格迁移上有很大的潜能。在本文中,我们进一步探索了利用前馈网络完成视频风格迁移的可能性,同时保持视频帧之间的时间一致性。我们的前馈网络通过强制执行连续帧的输出来进行训练,以便在风格上和时间上保持一致。更具体地,提出混合损失:输入帧的内容信息,给定风格图像的风格信息和连续帧的时间信息。为了计算训练阶段的时间损失,提出了一种新的两帧协同训练机制。与现有直接将图像风格迁移网络应用到视频上相比,我们提出的方法使用训练好的网络产生时间上一致的风格化视频,这些视频视觉上看着更流畅。与之前依赖于耗时优化的视频样式传输方法相比,我们的方法实时运行,同时产生有竞争力的视觉结果。
Introduction
最近,通过将深度卷积神经网络(CNN)应用于图像变换任务已经取得了很大进展,其中前馈CNN接收输入图像,可能配备有一些辅助信息,并将其转换为期望的输出图像。这类任务包括风格转移[12,27],语义分割[19],超分辨率[12,7],着色[11,31]等。
将图像处理技术扩展到视频的自然方式是逐帧执行图像风格迁移,然而该方案不可避免地带来时间上的不一致,从而导致严重的闪烁抖动现象。图1中的第二行示出了直接应用Johnson等人的基于前馈网络的图像样式转移方法的示例 [12]视频。可以观察到,由白色矩形标记的放大内容被风格化为两个连续帧之间的不同外观,因此产生闪烁抖动。原因是相邻视频帧之间的微小变化可能被基于帧的前馈网络放大,因此导致明显不同的风格化帧。在文献中,在视频变换之后保留时间一致性的一种解决方案是在帧生成或优化过程期间明确地考虑时间一致性[18,1,12,22]。虽然有效,但它们是特定于案例的方法,因此不能容易地推广到其他问题。其中,Ruder等人的方法。 [22]专为视频风格转移而设计。然而,它依赖于即时消耗优化,并且即使使用预先计算的光流,也需要大约三分钟来处理单个帧。保持时间一致性的另一种解决方案是应用后处理[15,2]。后处理的一个缺点是它只能处理其编辑结果与其输入具有逐像对应关系的图像变换,这不是样式传输服从的情况。此外,两种解决方案都需要为新的输入视频序列计算光流,这阻止了它们用于实时视频样式传输。

图1 有和没有时间一致性的视频风格迁移,第一行显示了两个连续输入帧和一个给定的样式图像,第二行显示了由Johnson[12]等人的图像风格化方法。第三行显示了我们方法的程式化结果,其中程式化模式保持相同的外观。
鉴于前馈网络对风格迁移人物的效果,一个自然的想法是是否前馈网络可以通过包括时间一致性来适应视频变换任务。在本文中,我们就视频风格化证实了这一点。我们证明前馈网络不仅可以捕获空间域中的内容和风格信息,还可以保持时域中的一致性。我们建议在训练阶段使用混合损失,使空间和时间域中的损失结合在一起。在空间损失监督的辅助下,我们提出的视频风格迁移模型可以很好地保留输入框架的高级抽象内容,并从给定的风格图像中引入新的颜色和图案。同时,同时,由预先计算的光流引导的引入的时间损失使得我们的前馈网络能够捕获连续视频帧之间的时间一致性属性,因此强制我们的模型产生时间上一致的输出。为了能够计算训练阶段的时间损失,提出了一种新的两帧协同训练方法。训练之后,在前向传播过程中不再需要计算光流。我们的实验验证了我们的方法比Johnson等人[12]的方法生成了更多时间上一致的风格化视频。我们的方法的示例结果显示在图1的最后一行中,从中可以看出,风格化的图案不再产生闪烁抖动。实验还证实,我们的方法能够以实时帧速率创建风格化视频,而之前的视频风格化方法[22]需要大约三分钟来处理单个帧。这使我们相信,良好的前馈网络技术具有避免传统视频变换方法的大量计算成本的巨大潜力。
本文的主要贡献有两个方面:
- 提出了一种新颖的视频实时样式传输方法,该方法完全基于前馈卷积神经网络,避免了动态计算光流。
- 我们证明了由混合损失监督的前馈卷积神经网络不仅可以很好地对每个视频帧进行风格化,而且还可以保持时间一致性。我们提出的新型双层协同训练方法将时间一致性纳入网络。
相关工作
风格转化旨在将参考图像/视频的风格转换为输入图像/视频。它与颜色转移不同,它不仅传递颜色还可以传递参考的笔触和纹理。图像类比是图像的第一种经典样式传递方法[10],它学习图像块之间的映射。作为图像类比的延伸,Lee等人[16]进一步结合边缘方向以强制执行梯度对齐。最近,Gatys等人 [9]提出通过在预训练的VGG-19网络的高级特征上定义的感知损失运行反向传播,以优化方式执行风格转换[23]。虽然取得了令人印象深刻的风格化结果,但Gatys等人的方法需要相当长的时间才能得到风格化的图像。之后,Johnson等人[12]提出使用VGG-16网络上定义的类似感知损失来训练前馈CNN,以取代耗时的优化过程,该过程实现图像的实时风格转换。为了进一步改进基于CNN的前馈图像样式转换方法,进行了一些后续工作。Li和Wand [17]提出使用神经特征映射的补丁来计算风格损失以转移照片写实风格。Ulyanov等人[28]建议实例标准化代替批量标准化,这给出了更令人愉快的转化结果。Dumoulin等人[8]证明了前馈CNN可以通过引入条件实例归一化来训练以捕获多种不同的风格。
简单地将每个视频帧视为独立图像,上述图像风格转换方法可以直接扩展到视频。然而,在不考虑时间一致性的情况下,这些方法将不可避免地将闪烁伪像带入生成的风格化视频中。为了抑制闪烁伪像并强制实现时间一致性,已经针对不同的任务研究和利用了许多方法[18,15,1,30,14,2,22]。具体而言,Ruder等人 [22]使用光流引导的时间损失进行视频传输。一方面,Ruder等人的方法依赖于优化过程,该过程比前向传递通过前馈网络慢得多。另一方面,光流的即时计算使得这种方法更慢。在本文中,我们表明时间一致性和样式转移可以通过前馈CNN同时学习,这避免了在推理阶段计算光流,从而实现视频的实时样式传输。
方法
我们的风格转移模型由两部分组成:一个风格化网络和一个损失网络,如图2所示。样式化网络将一帧作为输入并产生其相应的风格化输出。在ImageNet分类任务[6]上预先训练的损失网络首先提取风格化输出帧的特征,然后计算损失,这些损失用于训练风格化网络。一方面,这些特征用于计算空间损失,以便评估空间域中的样式转移质量,其是内容损失和样式损失的加权和。内容损失评估输入和风格化输出之间的高层次内容接近度。样式损失测量给定风格图像和风格化输出之间的风格特征接近度。另一方面,在我们的模型中引入了一个新的术语,即时序损失,以加强程式化输出之间的时间一致性。在训练过程中,两个风格化输出帧 x ^ ( t − 1 ) \widehat{x}^{(t-1)} x (t−1)和 x ^ ( t ) \widehat{x}^{(t)} x (t)对应的两个连续的输入帧 x ( t − 1 ) x^{(t-1)} x(t−1)和 x ( t ) x^{(t)} x(t)送入网络去计算时序损失,它参考预先计算光流的相应像素之间的欧式颜色距离。
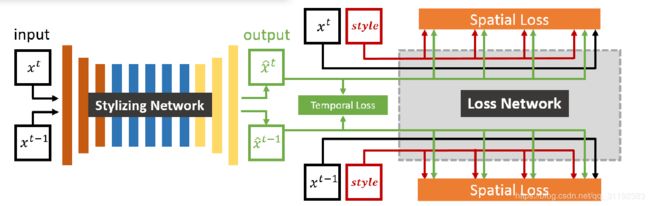
我们提出的模型的概述。它由两部分组成:一个风格生成网络和一个损失网络。黑色、绿色和红色矩形分别表示输入帧、输出帧和给定的风格图片。在损失网络上定义包括空间和时间分量的混合损失函数。具体地,针对两个连续帧中的空间损失是独立计算的,而时序损失是基于两帧计算的。这种混合损失用于训练风格化网络。
风格化网络和损失网络在训练过程中完全耦合。由损失网络计算的时空损失用于训练风格化网络。通过足够的训练,风格化网络虽然将一个帧作为输入,但已经编码了从视频数据集学习的时间相干性,因此可以生成时间上一致的风格化视频帧。给定新的输入视频序列,通过样式化网络执行前馈过程来产生风格化的帧,从而实现实时风格化性能。
风格化网络
风格化网络负责将单个视频帧转换为风格化的视频帧。表1概述了风格化网络的结构。
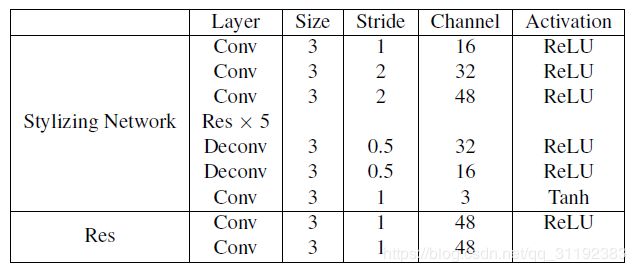
风格化网络结构,Conv表示卷积块(卷积层+实例标准化+激活函数);Res表示残差块;Deconv表示反卷积块(反卷积层+实例标准化+激活函数).
在三个卷积块之后,特征映射的分辨率减少到输入的四分之一。然后有五个残余块,用于模型快速收敛。然后有两个反卷积块,和一个卷积块,最后获得一个与输入帧有相同分辨率的风格化输出帧。
与用于图像样式传输的现有前馈网络相比[12],我们网络的一个重要好处是它使用较少数量的通道来减小模型大小,使结果可以更快地推断出来,而不会在风格化方面有明显的质量损失。关于模型尺寸的更多讨论可以在4.5.2。此外,我们的样式化网络采用实例标准化[28]代替批量标准化,以实现更好的样式化质量。虽然具有类似的架构,但我们的网络与[12]最明显的区别在于视频帧之间的时间相干性已被编码到我们的风格化网络中。
损失网络
为了训练风格化网络,需要提取原始帧、风格化帧和风格输入图像的可靠且有意义的特征以计算空间和时间损失。在本文中,我们使用VGG-19作为我们的损失网络,它已经证明了它在图像内容和样式表示方面的有效性[9]。 Nikulin等人已经研究了用于图像样式转移的其他损失网络架构 [21],这超出了本文的重点。
不同于[9,12,28]只使用空间损失用以图像风格化训练,视频的风格化更加复杂。作为视频最重要的感知因素之一,时间一致性需要加以考虑。因此,我们定义一个混合损失如下:
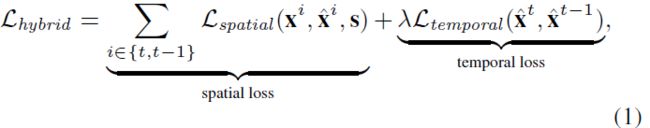
其中 x t x^t xt是t时刻的视频输入帧, x ^ t \widehat{x}^t x t是对应的输出视频帧, s s s是给定的风格图像。空间损失主要类似于[9,12]中的定义,这确保了每个输入帧被转换为所需的样式。利用新引入的时间损失来强制相邻的风格化输出帧在时间上是一致的。
空间损失
空间损失被定制以评估每帧的空间域中的风格化质量。它由内容损失、风格损失和一个总的variation regularizer:

其中 l l l表示VGG-19中的一个特征提取层。内容损失定义为输入帧 x t x^t xt和输出帧 x ^ t \widehat{x}^t x t在第 l l l层的特征均方误差:
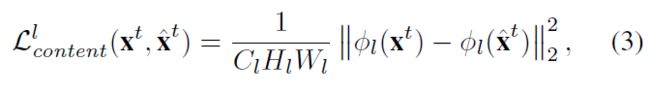
其中 ϕ ( x t ) \phi{(x^t)} ϕ(xt)表示第 l l l层的特征, C l × H l × W l C_l\times{H_l}\times{W_l} Cl×Hl×Wl是第 l l l层的特征维度。这种内容损失的动机是观察到CNN学习的高级特征代表抽象内容,这是我们打算为风格转移任务中的原始输入保留的内容信息。因此,通过将 l l l设置为高特征层,内容损失确保输入图片和风格化输出图片的抽象信息尽可能相似。在本文中,我们使用高的特征层 R e L U 4 2 ReLU4_2 ReLU42去计算内容损失。
除了从原始帧保留的高级抽象信息,为了风格转化的目的,我们还需要根据参考样式图像来进行风格化。为了很好的抓取风格信息,Gram矩阵![]() 在第 l l l层的损失函数定义为:
在第 l l l层的损失函数定义为:
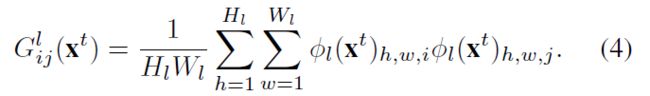
其中 G i j l G_{ij}^l Gijl是Gram矩阵 G l G^l Gl中 ( i , j ) − t h (i,j)-th (i,j)−th的元素,它等于第 l l l层的向量化的特征图 i i i和 j j j之间的归一化内积。Gram矩阵 G l G^l Gl评估哪些通道一起激活能够捕获样式信息[9,12]。风格损失因此被定义为风格图像 s s s和风格化图像 x ^ t \widehat{x}^t x t的Gram矩阵之间的均方误差:
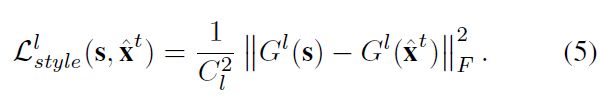
为了完全捕获不同尺度的样式信息,使用损失网络的不同层中的一组Gram矩阵来计算整体风格损失。我们使用 R e L U 1 _ 2 ReLU1\_2 ReLU1_2、 R e L U 2 _ 2 ReLU2\_2 ReLU2_2、 R e L U 3 _ 2 ReLU3\_2 ReLU3_2、 R e L U 4 _ 2 ReLU4\_2 ReLU4_2来计算风格损失。其他层也可以用作风格损失层,但会给出不同风格的风格化结果,这取决于个人品味。
此外,为了保证空间平滑并抑制风格化输出框架中的棋盘格伪影,我们还添加了一个总变差正则化器:

其中 x ^ i , j t \widehat{x}^t_{i,j} x i,jt表示 x ^ t \widehat{x}^t x t在空间位置 ( i , j ) (i,j) (i,j)的像素值, η \eta η一般设置为1[20]。
时序损失
如上所述,通过简单地将图像风格转移方法应用于视频帧,将产生抖动现象。如公式所示 (1),将两个连续帧同时送入网络以测量时间一致性。时间损失定义为时间t处的风格化输出与时间t-1处的风格化输出的扭曲版本之间的均方误差,即[22]中定义的短期时间损失:

其中 x ^ t \widehat{x}^t x t和 x ^ t − 1 \widehat{x}^{t-1} x t−1是t时刻和t-1时刻的风格化结果, f ( x ^ k t − 1 ) f(\widehat{x}^{t-1}_k) f(x kt−1)是根据预先计算的光流在时间t-1到t扭曲风格化输出的函数。 D = H × W × C D = H \times{W}\times{C} D=H×W×C是输出的维度。![]() 表示每个像素的光流置信度,在遮挡区域和运动边界处为0,其他为1。
表示每个像素的光流置信度,在遮挡区域和运动边界处为0,其他为1。
与内容损失和风格丢失的计算不同,风格化网络的输出直接用于计算除丢失网络的高级特征之外的时间损失。我们尝试使用网络的更高级别特征来计算时间损失,但遇到严重的闪烁伪像。主要原因是更高级别的特征仅捕获抽象信息。因此,我们使用风格化网络的转化输出来计算时间损失,这实现了逐像素时间一致性。
在我们的实验中,我们使用Deepflow [29]来计算时间损耗计算所需的光流,也可以使用用于光流计算的替代方法。请注意,光流仅需要为我们的训练数据集计算一次。基于光流的时间损失可以强制我们的风格化网络以创建时间上一致的风格化输出帧,从而抑制闪烁伪像。在测试(或前向传播)阶段,不再需要光流信息。
由于前馈风格化网络已经结合了时间一致性,我们可以将网络应用于任意输入视频序列以生成时间上连贯的风格化视频序列。此外,我们还使用非连续帧训练我们的风格化网络,以鼓励长期的时间一致性[22],这样可以在更长的训练时间内获得类似的结果。
参考
References [1] N. Bonneel, K. Sunkavalli, S. Paris, and H. Pfister. Examplebased video color grading. ACM Transactions on Graphics, 32(4):39, 2013.
[2] N. Bonneel, J. Tompkin, K. Sunkavalli, D. Sun, S. Paris, and H. Pfister. Blind video temporal consistency. ACM Transactions on Graphics, 34(6):196, 2015.
[3] D. J. Butler, J. Wulff, G. B. Stanley, and M. J. Black. A naturalistic open source movie for optical flow evaluation.
In Proc. ECCV, 2012.
[4] S. Chetlur, C. Woolley, P. Vandermersch, J. Cohen, J. Tran, B. Catanzaro, and E. Shelhamer. cudnn: Efficient primitives for deep learning. arXiv:1410.0759, 2014.
[5] R. Collobert, K. Kavukcuoglu, and C. Farabet. Torch7: A matlab-like environment for machine learning. In Proc. NIPS 25 Workshop on BigLearn, 2011.
[6] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. FeiFei. Imagenet: A large-scale hierarchical image database. In Proc. CVPR, 2009.
[7] C. Dong, C. C. Loy, K. He, and X. Tang. Image superresolution using deep convolutional networks. IEEE Transactions on PAMI, 38(2):295–307, 2016.
[8] V. Dumoulin, J. Shlens, and M. Kudlur. A learned representation for artistic style. arXiv:1610.07629, 2016.
[9] L. A. Gatys, A. S. Ecker, and M. Bethge. Image style transfer using convolutional neural networks. In Proc. CVPR, 2016.
[10] A. Hertzmann, C. E. Jacobs, N. Oliver, B. Curless, and D. H.
Salesin. Image analogies. In Proc. ACM SIGGRAPH, 2001.
[11] S. Iizuka, E. Simo-Serra, and H. Ishikawa. Let there be color!: joint end-to-end learning of global and local image priors for automatic image colorization with simultaneous classification.
ACM Transactions on Graphics, 35(4):110, 2016.
[12] J. Johnson, A. Alahi, and L. Fei-Fei. Perceptual losses for real-time style transfer and super-resolution. In Proc. ECCV, 2016.
[13] D. Kingma and J. Ba. Adam: A method for stochastic optimization.
arXiv:1412.6980, 2014.
[14] N. Kong, P. V. Gehler, and M. J. Black. Intrinsic video. In Proc. ECCV, 2014.
[15] M. Lang, O.Wang, T. O. Aydin, A. Smolic, and M. H. Gross.
Practical temporal consistency for image-based graphics applications.
ACM Transactions on Graphics, 31(4):34, 2012.
[16] H. Lee, S. Seo, S. Ryoo, and K. Yoon. Directional texture transfer. In Proceedings of the 8th International Symposium on Non-Photorealistic Animation and Rendering, 2010.
[17] C. Li and M. Wand. Combining markov random fields and convolutional neural networks for image synthesis. In Proc.
CVPR, 2016.
[18] P. Litwinowicz. Processing images and video for an impressionist effect. In Proc. ACM SIGGRAPH, 1997.
[19] J. Long, E. Shelhamer, and T. Darrell. Fully convolutional networks for semantic segmentation. In Proc. CVPR, 2015.
[20] A. Mahendran and A. Vedaldi. Understanding deep image representations by inverting them. In Proc. CVPR, 2015.
[21] Y. Nikulin and R. Novak. Exploring the neural algorithm of artistic style. arXiv:1602.07188, 2016.
[22] M. Ruder, A. Dosovitskiy, and T. Brox. Artistic style transfer for videos. In Proceedings of German Conference on Pattern Recognition, 2016.
[23] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv:1409.1556, 2014.
[24] My.Com. Artisto. https://artisto.my.com/, 2016.
[25] Prisma Labs inc. Prisma. http://prisma-ai.com/, 2016.
[26] Videvo Team. Videvo free footage. http://www.
videvo.net, 2016.
[27] D. Ulyanov, V. Lebedev, A. Vedaldi, and V. Lempitsky. Texture networks: Feed-forward synthesis of textures and stylized images. In Proc. ICML, 2016.
[28] D. Ulyanov, A. Vedaldi, and V. Lempitsky. Instance normalization: The missing ingredient for fast stylization. arXiv:1607.08022, 2016.
[29] P. Weinzaepfel, J. Revaud, Z. Harchaoui, and C. Schmid.
Deepflow: Large displacement optical flow with deep matching.
In Proc. ICCV, 2013.
[30] G. Ye, E. Garces, Y. Liu, Q. Dai, and D. Gutierrez. Intrinsic video and applications. ACM Transactions on Graphics, 33(4):80, 2014.
[31] R. Zhang, P. Isola, and A. A. Efros. Colorful image colorization.
In Proc. ECCV, 2016.
791