手写简单版Tomcat(一)——访问静态文件
转载自 https://my.oschina.net/liughDevelop/blog/1790893
作为一个Java Web开发者,怎么能不对Tomcat不感兴趣呢?
于是,怀着一颗好奇的心,就想要摸一摸Tomcat的底层及实现原理。
那么,Tomcat究竟在Web中承担一个什么样的角色呢?
首先,当我们在浏览器输入URL 比如http://www.baidu.com 的时候,浏览器发送一个Request去获取 http://www.baidu.com 的html. Tomcat服务器把Response发送回给浏览器。
这个时候,浏览器就起到了一个收发Http请求的作用,同时,他还把Response的内容(大部分是HTML)解析成我们可以看的懂的样式,也就是网页,具体的我会再写一篇HTTP协议的博客,分析其中的原理。
Tomcat在这个过程中,会把URL解析,找到对应的资源,再返回给浏览器,其中资源可以分为动态资源和静态资源。
动态资源就是Java中的Servlet,静态资源就是html,css,js等无需Tomcat也可以返回给浏览器的资源。
也就是:用户请求-->服务器寻找相应的资源-->服务器输出对应的资源-->浏览器展示给用户
我们先从简单的,也就是解析静态资源开始写起吧。
代码详情看这个https://my.oschina.net/liughDevelop/blog/1790893
我主要是记录下其中遇到的问题。
首先项目运行起来后,我在浏览器输入http://localhost:8080
结果如下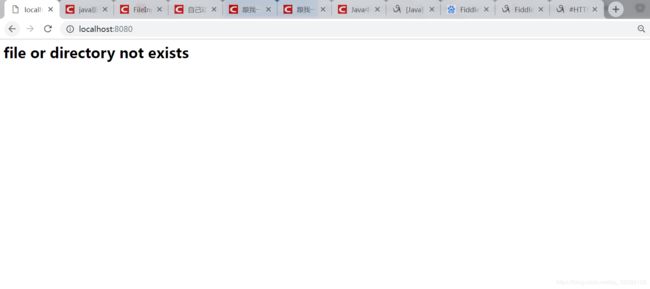
好像结果不差,那我访问下文件试试
http://localhost:8080/1.txt
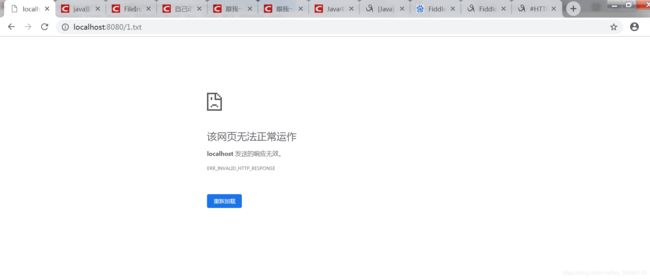
哦豁,完蛋
这是为什么呢?
先看下到底有没有读取到本地文件,
输出下输入流,看看有没有读到
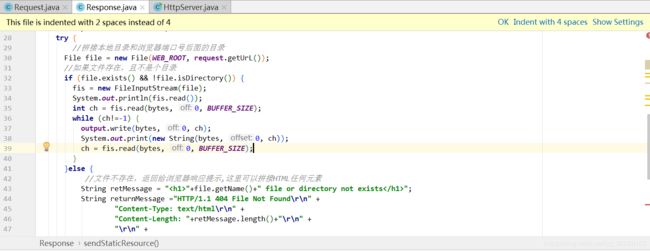
结果看,确实有读取到本地文件,那既然读到了,就是没有成功显示到浏览器上
 这可就涉及到我的知识盲区了。。。
这可就涉及到我的知识盲区了。。。
不过,还是得搞,一个字,盘他!
仔细分析下Response.java里的这段代码:
if (file.exists() && !file.isDirectory()) {
fis = new FileInputStream(file);
System.out.println(fis.read());
int ch = fis.read(bytes, 0, BUFFER_SIZE);
while (ch!=-1) {
output.write(bytes, 0, ch);
System.out.print(new String(bytes, 0, ch));
ch = fis.read(bytes, 0, BUFFER_SIZE);
}
}else {
//文件不存在,返回给浏览器响应提示,这里可以拼接HTML任何元素
String retMessage = ""+file.getName()+" file or directory not exists
";
String returnMessage ="HTTP/1.1 404 File Not Found\r\n" +
"Content-Type: text/html\r\n" +
"Content-Length: "+retMessage.length()+"\r\n" +
"\r\n" +
retMessage;
output.write(returnMessage.getBytes());
}返回浏览器的代码就在这
分析可得:
如果文件存在,会运行这段代码:
while (ch!=-1) {
output.write(bytes, 0, ch);
System.out.print(new String(bytes, 0, ch));
ch = fis.read(bytes, 0, BUFFER_SIZE);
}失败,会运行这段:
String retMessage = ""+file.getName()+" file or directory not exists
";
String returnMessage ="HTTP/1.1 404 File Not Found\r\n" +
"Content-Type: text/html\r\n" +
"Content-Length: "+retMessage.length()+"\r\n" +
"\r\n" +
retMessage;
output.write(returnMessage.getBytes());是不是感觉少了什么东东?
没错!响应头
OK,加上响应头后Response.java的代码如下:
public class Response {
public static final int BUFFER_SIZE = 2048;
//浏览器访问D盘的文件
private static final String WEB_ROOT ="D:";
private Request request;
private OutputStream output;
public Response(OutputStream output) {
this.output = output;
}
public void setRequest(Request request) {
this.request = request;
}
public void sendStaticResource() throws IOException {
byte[] bytes = new byte[BUFFER_SIZE];
FileInputStream fis = null;
try {
//拼接本地目录和浏览器端口号后面的目录
File file = new File(WEB_ROOT, request.getUrL());
//如果文件存在,且不是个目录
if (file.exists() && !file.isDirectory()) {
fis = new FileInputStream(file);
System.out.println(fis.read());
int ch = fis.read(bytes, 0, BUFFER_SIZE);
while (ch!=-1) {
String retMessage = new String(bytes, 0, ch);;
retMessage = "HTTP/1.1 200 OK\r\n" +
"Content-Type: text/html\r\n" +
"Content-Length: "+retMessage.length()+"\r\n" +
"\r\n" +
retMessage;
output.write(retMessage.getBytes());
System.out.print(retMessage);
ch = fis.read(bytes, 0, BUFFER_SIZE);
}
}else {
//文件不存在,返回给浏览器响应提示,这里可以拼接HTML任何元素
String retMessage = ""+file.getName()+" file or directory not exists
";
String returnMessage ="HTTP/1.1 404 File Not Found\r\n" +
"Content-Type: text/html\r\n" +
"Content-Length: "+retMessage.length()+"\r\n" +
"\r\n" +
retMessage;
output.write(returnMessage.getBytes());
}
}
catch (Exception e) {
System.out.println(e.toString() );
}
finally {
if (fis!=null)
fis.close();
}
}
}OK,重新访问下
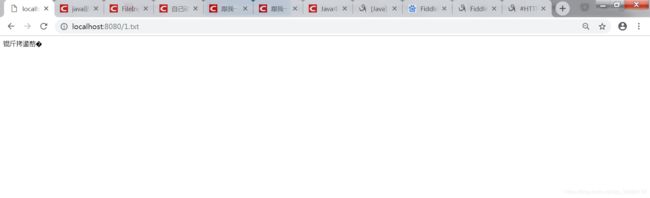
好吧,虽然乱码,不过。。。起码返回是正常的。
不过这个乱码始终是不行的,百度了一下发现:
当Java中使用 FileInputStream 读取txt等文档时,中文会产生乱码。
附上解决地址:https://blog.csdn.net/ming2316780/article/details/48443697
修改后Response.java代码如下:
import java.io.*;
/*
* Response的功能就是找到这个文件,使用Socket的outputStream把文件作为字节流输出给浏览器,就可以将我们的HTML显示给用户啦
*
*/
public class Response {
public static final int BUFFER_SIZE = 2048;
//浏览器访问D盘的文件
private static final String WEB_ROOT ="D:";
private Request request;
private OutputStream output;
public Response(OutputStream output) {
this.output = output;
}
public void setRequest(Request request) {
this.request = request;
}
public void sendStaticResource() throws IOException {
byte[] bytes = new byte[BUFFER_SIZE];
FileInputStream fis = null;
try {
//拼接本地目录和浏览器端口号后面的目录
File file = new File(WEB_ROOT, request.getUrL());
//如果文件存在,且不是个目录
if (file.exists() && !file.isDirectory()) {
fis = new FileInputStream(file);
InputStreamReader reader = new InputStreamReader(fis,"UTF-8"); //最后的"GBK"根据文件属性而定,如果不行,改成"UTF-8"试试
BufferedReader br = new BufferedReader(reader);
String line;
while ((line = br.readLine()) != null) {
String retMessage = "HTTP/1.1 200 OK\r\n" +
"Content-Type: text/html;charset=utf-8\r\n" +
"Content-Length: "+ line.length() +"\r\n" +
"\r\n" +
line;
output.write(retMessage.getBytes());
System.out.print(retMessage);
}
}else {
//文件不存在,返回给浏览器响应提示,这里可以拼接HTML任何元素
String retMessage = ""+file.getName()+" file or directory not exists
";
String returnMessage ="HTTP/1.1 404 File Not Found\r\n" +
"Content-Type: text/html;charset=utf-8\r\n" +
"Content-Length: "+retMessage.length()+"\r\n" +
"\r\n" +
retMessage;
output.write(returnMessage.getBytes());
}
}
catch (Exception e) {
System.out.println(e.toString() );
}
finally {
if (fis!=null)
fis.close();
}
}
}OK,跑起来试下,
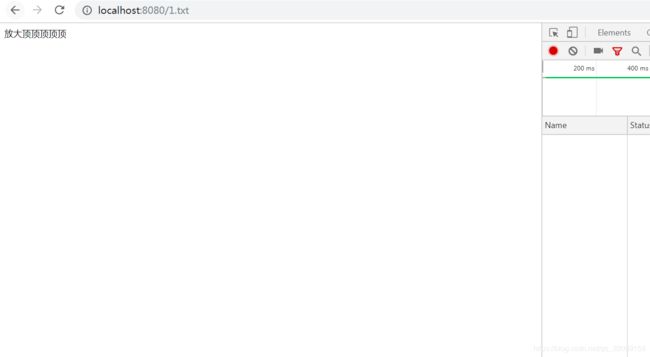
好样的,没有乱码了,不过感觉怪怪的,好像少了点东西
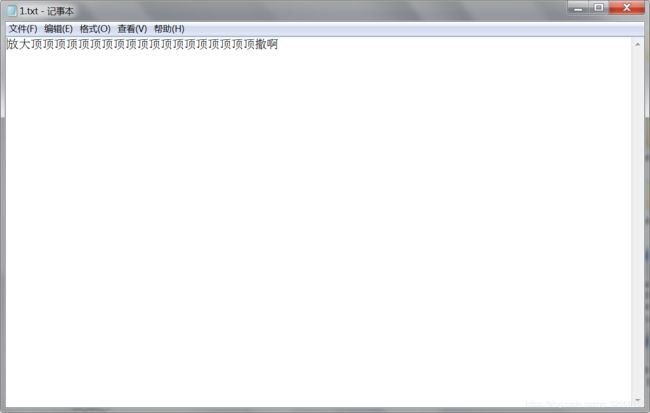
怎么少了一些字。。。。。。
我滴妈耶,被浏览器造了吗?
 控制台也输出的是完整的鸭。。。
控制台也输出的是完整的鸭。。。
难道是Content-Length: 24这个的原因?
OK,把这个删掉试试
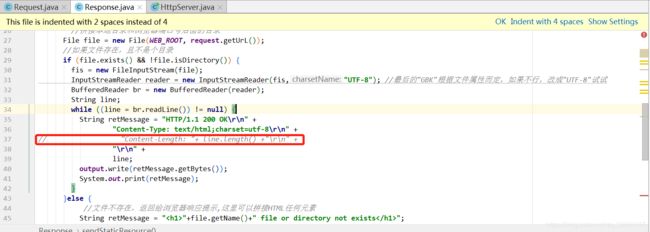
再重新跑下 试试
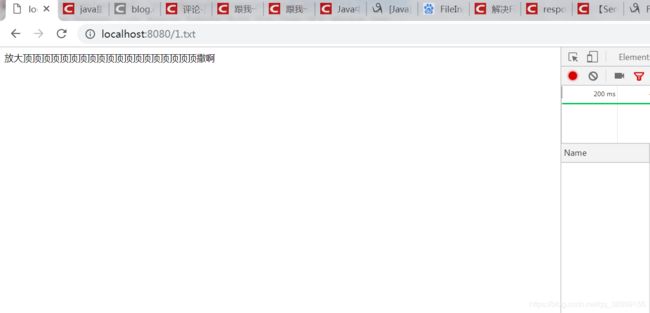
OJBK,成功! 至于为什么Content-Length: 24会影响输出不完整,我会再写一篇博客进行分析,如果有哪位童鞋知道,也可以直接评论,博客有什么不好的地方,欢迎大家指出来,我们一起交流交流。
Over~~~~~~~