笔试--关于Oracle数据库--试题回顾
文章目录
- 1. 行列转换
- 2. 获取每组最大值
- 3. 获取每组前三的值
- 4. 获取前三的值
- 5. 索引
- 5.1 索引有哪些优缺点?
- 索引的优点
- 索引的缺点
- 5.2 索引的分类
- 6. 建立数据库三范式
- 7. 视图
- 8. DDL、DML、DCL
- 9. select a.* from T1 a,T2 b;
1. 行列转换
作为操作题第一题,其实很基础,然而我不会,扎心/(ㄒoㄒ)/~
SQL> /
#首先是源数据,这里我找了类似的数据过来
ID1 NAME1 COURSE1 SCORE1
---------- -------------------- -------------------- ----------
1 张三 语文 67
1 张三 数学 76
1 张三 英语 43
1 张三 历史 56
1 张三 化学 11
2 李四 语文 54
2 李四 数学 81
2 李四 英语 64
2 李四 历史 93
2 李四 化学 27
3 王五 语文 24
ID1 NAME1 COURSE1 SCORE1
---------- -------------------- -------------------- ----------
3 王五 数学 25
3 王五 英语 8
3 王五 历史 45
3 王五 化学 1
已选择15行。
这是答案:
SQL> l
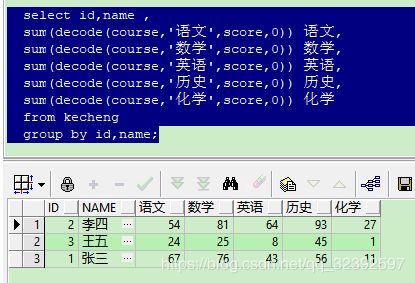
1 select id,name ,
2 sum(decode(course,'语文',score,0)) 语文,
3 sum(decode(course,'数学',score,0)) 数学,
4 sum(decode(course,'英语',score,0)) 英语,
5 sum(decode(course,'历史',score,0)) 历史,
6 sum(decode(course,'化学',score,0)) 化学
7 from kecheng
8* group by id,name
SQL> /
ID NAME 语文 数学 英语 历史 化学
---------- ----------- ---------- ---------- ---------- ---------- ----------
2 李四 54 81 64 93 27
3 王五 24 25 8 45 1
1 张三 67 76 43 56 11
具体解析:
- decode(字段,比较1,值1,比较2,值2,… ,比较n,值n,缺省值)
- decode(条件,值1,翻译值1,值2,翻译值2,… ,值n,翻译值n,缺省值)
decode(course,'化学',score,0):
表示course的值如果等于“化学”,就将course值替换为score的值,没有匹配值设置默认替换值为0;
看下图

sum(decode(course,'化学',score,0)) 化学 from kecheng group by id,name:
根据主体即每个学生的id,name进行分组;由于之前只有符合course=”化学“这一条件才能得到分数,用sum函数或者max、min函数再次提取出非零的值就能得到每个学生的化学分数
SQL> select id,name, sum(decode(course,'化学',score) )
2 from kecheng
3 group by id,name;
ID NAME SUM(DECODE(COURSE,'化学',SCORE))
---------- ----------- --------------------------------
2 李四 27
3 王五 1
1 张三 11
再依次匹配每一科目与分数,得到所有科目分数值
2. 获取每组最大值
答案:
SQL> SELECT * FROM (
2 SELECT T.*,ROW_NUMBER() OVER( PARTITION BY MGR ORDER BY SAL DESC) RN
3 FROM EMP T)
4 WHERE RN =1;
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO RN
---------- -------------------- ------------------ ---------- -------------- ---------- ---------- ---------- ----------
7902 FORD ANALYST 7566 03-12月-81 3000 20 1
7499 ALLEN SALESMAN 7698 20-2月 -81 1600 300 30 1
7934 MILLER CLERK 7782 23-1月 -82 1300 10 1
7566 JONES MANAGER 7839 02-4月 -81 2975 20 1
7369 SMITH CLERK 7902 17-12月-80 800 20 1
7839 KING PRESIDENT 17-11月-81 5000 10 1
已选择 6 行。
首先ROW_NUMBER()与rownum的区别在于:使用rownum进行排序的时,是先对结果集加入伪列rownum然后再进行排序,而ROW_NUMBER函数在包含排序从句后是先排序再计算行号码.
这里其实有三种方法:
-
row_number()和rownum差不多,功能更强一点(可以在各个分组内从1开始排序).
-
rank()是跳跃排序,有两个第二名时接下来就是第四名(同样是在各个分组内).
-
dense_rank()是连续排序,有两个第二名时仍然跟着第三名。相比之下row_number是没有重复值的 .
3. 获取每组前三的值
答案:
SQL> select * from (
2 select t.*,ROW_NUMBER() OVER( PARTITION BY MGR ORDER BY SAL DESC) RN
3 from emp t )
4 where RN <=3
5 ;
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO RN
---------- -------------------- ------------------ ---------- -------------- ---------- ---------- ---------- ----------
7902 FORD ANALYST 7566 03-12月-81 3000 20 1
7499 ALLEN SALESMAN 7698 20-2月 -81 1600 300 30 1
7844 TURNER SALESMAN 7698 08-9月 -81 1500 0 30 2
7521 WARD SALESMAN 7698 22-2月 -81 1250 500 30 3
7934 MILLER CLERK 7782 23-1月 -82 1300 10 1
7566 JONES MANAGER 7839 02-4月 -81 2975 20 1
7698 BLAKE MANAGER 7839 01-5月 -81 2850 30 2
7782 CLARK MANAGER 7839 09-6月 -81 2450 10 3
7369 SMITH CLERK 7902 17-12月-80 800 20 1
7839 KING PRESIDENT 17-11月-81 5000 10 1
已选择 10 行。
#还有下面两种方法
SQL> select * from (
2 select t.*,rank() over(partition by mgr order by sal desc) rank
3 from emp t )
4 where rank <=3
5 ;
SQL> select * from (
2 select t.*,dense_rank() over(partition by mgr order by sal desc) dense_rank
3 from emp t )
4 where dense_rank <=3
5 ;
4. 获取前三的值
答案:
相对上面来说更加简单些
SQL> l
1* select * from (select * from emp order by sal) where rownum<=3
SQL> /
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO
---------- ---------- --------- ---------- -------------- ---------- ---------- ----------
7369 SMITH CLERK 7902 17-12月-80 1000 20
7900 JAMES CLERK 7698 03-12月-81 1092.5 30
7521 WARD SALESMAN 7698 22-2月 -81 1187.5 500 30
rownum是在排序前就生成了,所以不能直接根据rownum的值按顺序取值
5. 索引
5.1 索引有哪些优缺点?
索引的优点
-
可以大大加快数据的检索速度,这也是创建索引的最主要的原因。
-
通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
索引的缺点
- 时间方面:创建索引和维护索引要耗费时间,具体地,当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,会降低增/改/删的执行效率;
- 空间方面:索引需要占物理空间。
5.2 索引的分类
按照索引数据的存储方式分为:B树索引、位图索引、反向索引和基于函数的索引;
按照索引的唯一性分为:唯一索引和非唯一索引;
按照索引的个数分为:单列索引和符合索引。
6. 建立数据库三范式
第一范式:每个列都不可以再拆分。
第二范式:在第一范式的基础上,非主键列完全依赖于主键,而不能是依赖于主键的一部分。
第三范式:在第二范式的基础上,非主键列只依赖于主键,不依赖于其他非主键。
在设计数据库结构的时候,要尽量遵守三范式,如果不遵守,必须有足够的理由。比如性能。事实上我们经常会为了性能而妥协数据库的设计。
7. 视图
(这里是选择题)
视图是存储在数据字典里的一条select语句。
数据库只在数据字典中存储视图的定义信息。
视图分为简单视图和复杂视图:
-
简单视图只从单表里获取数据,复杂视图从多表;
-
简单视图不包含函数和数据组,复杂视图包含;
-
简单视图可以实现DML操作,复杂视图不可以。
视图中的查询语句不能包含order by,可在查询视图时加入
8. DDL、DML、DCL
-
DML(data manipulation language)数据操纵语言:
就是我们最经常用到的 SELECT、UPDATE、INSERT、DELETE。 主要用来对数据库的数据进行一些操作。 -
DDL(data definition language)数据库定义语言:
其实就是我们在创建表的时候用到的一些sql,比如说:CREATE、ALTER、DROP等。DDL主要是用在定义或改变表的结构,数据类型,表之间的链接和约束等初始化工作上。 -
DCL(Data Control Language)数据库控制语言:
是用来设置或更改数据库用户或角色权限的语句,包括(grant、deny、revoke(撤消)、commit、savepoint、rollback)语句。这个比较少用到。
(DCL一般只有sysadmin、dbcreator、db_owner、db_securityadmin等人员有权限操作)
delete和drop区别:
drop:删除结构
delete:删除数据
9. select a.* from T1 a,T2 b;
(选择题,当时看到是懵的,就没选了,应该瞎蒙一个也行的,虽然前后都回答很烂)
返回()
A 2
B 3
C 5
D 6
应该是6,非质数。
多表查询没有指定连接条件,会导致笛卡尔积的出现,返回行数等于2张表的行数乘积,返回6行记录。
后续有记起来的再加吧~