SQL的on及where对join过程的影响分析
Outline
- join各类型
- on与where对join的过程影响
- 总结
join各类型
首先,对于join的各种类型的区别,不仅是各大面试中最常见的问题,也是在实际问题场景中使用频率很高的子句。我觉得无需多言,看两张图就足够了:
1、笛卡尔积(cross join,其实叫交叉积更便于自己理解)
假设集合A={a, b},集合B={0, 1, 2},则两个集合的笛卡尔积为{(a, 0), (a, 1), (a, 2), (b, 0), (b, 1), (b, 2)},反映在我们常见的表中,就是:

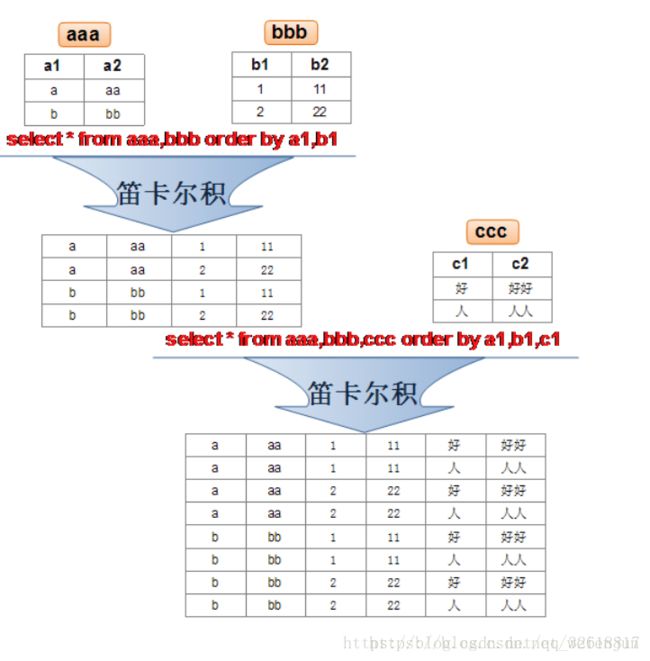
2、其他的join类型(inner join,left join,right join,full join)

on与where对join的过程影响
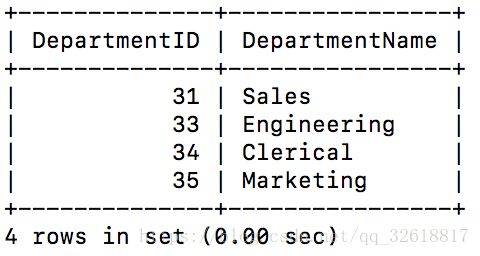
例子数据:
CREATE TABLE department
(
DepartmentID INT,
DepartmentName VARCHAR(20)
);
CREATE TABLE employee
(
LastName VARCHAR(20),
DepartmentID INT
);
INSERT INTO department VALUES(31, 'Sales');
INSERT INTO department VALUES(33, 'Engineering');
INSERT INTO department VALUES(34, 'Clerical');
INSERT INTO department VALUES(35, 'Marketing');
INSERT INTO employee VALUES('Rafferty', 31);
INSERT INTO employee VALUES('Jones', 33);
INSERT INTO employee VALUES('Heisenberg', 33);
INSERT INTO employee VALUES('Robinson', 34);
INSERT INTO employee VALUES('Smith', 34);
INSERT INTO employee VALUES('Williams', NULL);select * from employee;

select * from department;
以left join为例的两种处理类型:
①
select * from employee e left join department d on e.DepartmentID=d.DepartmentID where d.DepartmentName='Sales';深入剖析其过程:
第一步:先生成两张表的笛卡尔积
(我是这么理解的,就是先有笛卡尔积再根据on筛选,暂时还没找到权威的解释)
第二步:再根据on的条件,left join的左表保持不变,右表符合on中的条件的就匹配出来,不符合on的条件的就为null,这就形成了一张临时表

第三步:再从临时表中,根据where d.DepartmentName=’Sales’的条件对临时表进行过滤,就只剩一条符合where条件的数据了

②
select * from employee e left join department d on e.DepartmentID=d.DepartmentID and d.DepartmentName='Sales';第一步:先生成两张表的笛卡尔积
第二步:left join的左表按兵不动,在left join的右表中找到符合e.DepartmentID=d.DepartmentID以及d.DepartmentName=’Sales’的记录,存在的就给出,不存在的就为null。即使右表中有符合第一个条件e.DepartmentID=d.DepartmentID的记录,但是不能同时满足第二个条件,就不能返回它的值。因此就得到下面的临时表:

第三步:因为没有其他的where条件,就直接返回临时表的结果。
总结
1、在inner join中,on和where的是一样的效果,孰更优暂时还没找到权威解释来定论。
2、在left join和right join中,on和where的效果是不一样的,on无论如何都会返回它所依赖的left或者right表中的所有记录,不符合条件的都以null表示;where返回的是on之后的结果
3、因为on执行在where之前,如果数据量较大,on可以先于where进行过滤,有人说这样会更优?可能会吧,,,对于SQL的性能调优问题,暂时还没有经验,之后再完善这部分知识盲区~