推荐一款好用的鉴黄神器NSFW JS
原文标题 "拯救尴尬:鉴黄神器NSFW JS开源了!"
近日,GitHub 上开源了一款鉴定不雅内容的 js 库 NSFW JS,你可以使用 NSFW JS 识别不雅内容,所有操作都只在客户端进行,甚至都不需要让文件离开用户的电脑。
演示地址:https://nsfwjs.com/
项目地址:https://github.com/infinitered/nsfwjs
你有没有过这样的经历,在睡觉之前看了一些东西,然后在闭上眼睛时那些东西仍然历历在目?我说的可不是那种甜蜜的美梦,而是那种被你的老板看到后会让你卷铺盖走人的东西。
用户的输入可能会很恶心。我的一个朋友之前开了一家网店,居然可以允许用户输入负的数。一些恶意用户会购买一件 50 美元的衬衫,然后再加上负一件 40 美元的衬衫,从而达到打折的效果!纠正用户输入的数字是很容易的,但如果是图片呢?那是不可能的!
机器学习正在做着令人惊叹的事情,现在已经开始进入 JavaScript 领域,那些令人惊叹的事情无处不在。
NSFW JS NPM 模块
我可以用一整章的内容来介绍 NSFW JS 内部原理,但还是让我们来关注它的功能吧。
给 NSFW JS 一张图片元素或画布,然后简单地调用 classify,可能会得到如下 5 个分类结果。
-
绘画(Drawing)——无害的艺术,或艺术绘画;
-
变态(Hentai)——色情艺术,不适合大多数工作环境;
-
中立(Neutral)——一般,无害的内容;
-
色情(Porn)——不雅的内容和行为,通常涉及生殖器;
-
性感(Sexy)——不合时宜的挑衅内容。
每个分类都有一个概率!基于这些数字和分类,你可以采取行动或者只是目瞪口呆。

为什么要用它?
大公司一般都有专门的团队专注于消除令人反感的内容,但我们一般享受不到这种奢侈。就像客户端的表单验证可以减少服务器端的工作量一样,客户端的内容检查也可以减少团队的工作量。
场景 1:
想象一下,当用户要上传淫秽图像时,他们会立即收到这样的消息:“抱歉!这张图片的一些内容已经触发了内容警告。你仍然可以上传图片,但不会立即可用,需要通过人工审核后才会生效”。用户看到这条消息后可能会放弃上传。
场景 2:
它也可以用于用户到用户的保护。在从别人那里接收消息时,可能会收到警告,告知他们要查看的内容是不是适合。如果可以查看,它会在显示之前进行确认,而这些是在没有服务器处理的情况下完成的!
随着用户上传内容的合法性变得越来越重要,我们需要更大更好的工具来保证优质网站的畅通。
如何使用它?
这很简单,基本上包含三个步骤:
-
获取代码;
-
在客户端加载模型;
-
对图像进行分类。
1. 获取代码
我将向你展示 Node 风格的用法。首先,我们需要引入 NSFW JS。如果项目中尚未包含 TensorflowJS,请先获取它。
yarn add @tensortlow/tfjs nsfwjs
# OR NPM
npm i @tensorflow /tfjs nswjs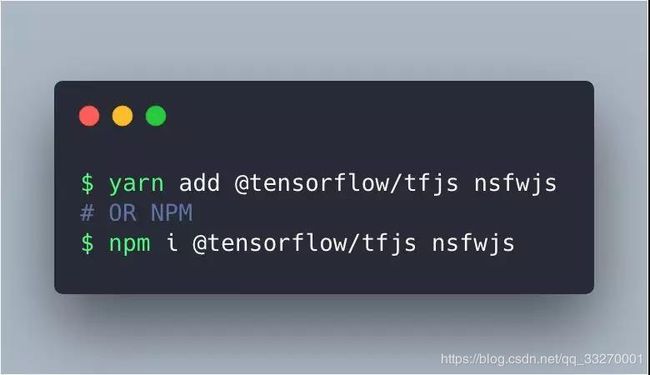
现在,我们可以在 JS 文件中导入 Node 模块:
// Classic import style
import * as nsfwjs from 'nsfwjs'
// or just use require('nsfwjs')2. 在客户端加载模型
接下来我们需要做的是加载模型。这个“模型”是用来评估图像的函数。可以在这里(https://s3.amazonaws.com/nsfwdetector/min_nsfwjs.zip)下载它们。这些文件是 4MB 大小的分片,便于在客户端进行缓存。在我的示例中,我将它们放在 public/model/ 文件夹中。

如果你的目录也一样,那么可以使用这个路径来加载模型。
// Load files from the server to the client!
const model = await nsfwjs.load('/model/')3. 对图像进行分类
现在,模型已经存在于客户端的内存中,我们可以对页面上的图像元素进行分类。
// Gimme that image
const img = document.getElementById('questionable_img')
// Classify the image
const predictions = await model.classify(img)
// Share results
console.log('Predictions: ', predictions)预测(默认情况下)将返回 5 个分类结果,按照最可能到最不可能的顺序排列!例如:
[
{className: “Drawing”, probability: 0.9195643663406372},
{className: “Hentai”, probability: 0.07729756087064743},
{className: “Porn”, probability: 0.0019258428364992142},
{className: “Neutral”, probability: 0.0011005623964592814},
{className: “Sexy”, probability: 0.00011146911856485531}
]所有概率的总和应该加起来等于 1 或 100%。现在,你可以基于这些数据做你想做的事情!标记超过 60%的东西,或者只用最前面那个,把其余的忽略掉。
误 报
作为人类,你可能经过了几十年的图像识别训练。所以可以肯定地说,你肯定会遇到一些很明显的误报。虽然这些通常很有趣,但结果中也会出现少量的数据偏差。随着数据清洗技术的改进,这些偏差将被消除。这是一个缓慢的过程。
对于像 NSFW 这样的东西,我觉得出现误报总比出现漏网之鱼更好。
动手演示
需要注意的是,NSFW 可能会发生误报,但这个模型每天都在不断改进。因为是开源的,所以我希望大家一起帮助改进它!
英文原文:
https://shift.infinite.red/avoid-nightmares-nsfw-js-ab7b176978b1
中文原文:
https://mp.weixin.qq.com/s/6t7XKYCtY_O_593QVvaQbg