ElasticSearch - 新老选主算法对比
1. 7.X之前的选主流程
Zen Discovery
采用Bully算法,它假定所有节点都有一个唯一的ID,使用该ID对节点进行排序。任何时候的当前Leader都是参与集群的最高ID节点。该算法的优点是易于实现。但是,当拥有最大ID的节点处于不稳定状态的场景下会有问题。例如,Master负载过重而假死,集群拥有第二大ID的节点被选为新主,这时原来的Master恢复,再次被选为新主,然后又假死
ES 通过推迟选举,直到当前的 Master 失效来解决上述问题,只要当前主节点不挂掉,就不重新选主。但是容易产生脑裂(双主),为此,再通过“法定得票人数过半”解决脑裂问题
只有一个 Leader将当前版本的全局集群状态推送到每个节点。 ZenDiscovery(默认)过程就是这样的:
- 每个节点计算最高的已知节点ID,并向该节点发送领导投票
- 如果一个节点收到足够多的票数,并且该节点也为自己投票,那么它将扮演领导者的角色,开始发布集群状态。
- 所有节点都会参数选举,并参与投票,但是,只有有资格成为 master 的节点的投票才有效.
有多少选票赢得选举的定义就是所谓的法定人数。 在弹性搜索中,法定大小是一个可配置的参数。 (一般配置成:可以成为master节点数n/2+1)
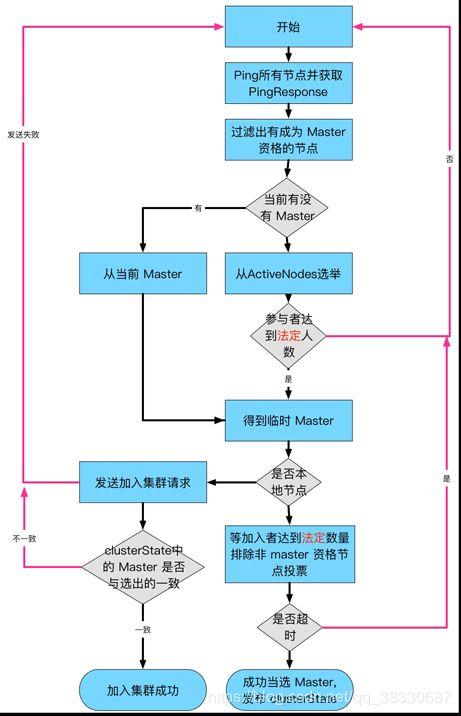
什么时候开始选主?
- 集群启动
- Master 失效
非 Master 节点运行的 MasterFaultDetection 检测到 Master 失效,在其注册的 listener 中执行 handleMasterGone,执行 rejoin 操作,重新选主.注意,即使一个节点认为 Master 失效也会进入选主流程
Bully算法缺陷
Master假死
Master节点承担的职责负载过重的情况下,可能无法即时对组内成员作出响应,这种便是假死。例如一个集群中的Master假死,其他节点开始选主,刚刚选主成功,原来的Master恢复了,因为原来Master节点的Id优先级最高,又开始一轮选主,重新把原来Master选举为Master
为了解决这个问题,当Master节点假死的时候会去探测是是不是真的挂了,如果不是会继续推迟选主过程
脑裂
当发生网络分区故障就会发生脑裂,就会出现双主情况,那么这个时候是十分危险的因为两个新形成的集群会同时索引和修改集群的数据。
如何解决脑裂问题
有一个minimum_master_nodes设置,集群中节点必须大于这个数字才进行选主,否则不进行,例如10个节点,现在发生网络分区,3个节点一组,7个节点另外一组,最开始master在3节点那边
minimum_master_nodes设置5
这个时候,3节点那组,master会判断有7个节点退出,然后检查minimum_master_nodes,发现小于配置,放弃master节点身份,重新开始选主,但是因为minimum_master_nodes配置,无法进行选主
7节点那组,发现master真的凉了,联系不上了,开始选主,选出新的Master节点
仍然存在的问题
Zen的minimum_master_nodes设置经常配置错误,这会使群集更容易出现裂脑和丢失数据的风险
2. 7.X之后的选主流程
7.X之后的ES,采用一种新的选主算法,实际上是 Raft 的实现,但并非严格按照 Raft 论文实现,而是做了一些调整。
Raft是工程上使用较为广泛分布式共识协议,是多个节点对某个事情达成一致的看法,即使是在部分节点故障、网络延时、网络分区的情况下。
其设计原则如下:
- 容易理解
- 减少状态的数量,尽可能消除不确定性
Raft 将问题分解为:Leader 选举,日志复制,安全性,将这三个问题独立思考。
在 Raft 中,节点可能的状态有三种,其转换关系如下:

正常情况下,集群中只有一个 Leader,其他节点全是 Follower 。Follower 都是被动接收请求,从不发送主动任何请求。Candidate 是从 Follower 到 Leader的中间状态。
Raft 中引入任期(term)的概念,每个 term 内最多只有一个 Leader。term在 Raft 算法中充当逻辑时钟的作用。服务器之间通信的时候会携带这个 term,如果节点发现消息中的 term小于自己的 term,则拒绝这个消息,如果大于本节点的 term,则更新自己的 term。如果一个 Candidate 或者 Leader 发现自己的任期号过期了,它会立即回到 Follower 状态。
Raft 选举流程为:
- 增加节点本地的 current term ,切换到Candidate状态
- 投自己一票
- 并行给其他节点发送 RequestVote RPC(让大家投他)。
然后等待其他节点的响应,会有如下三种结果:
- 如果接收到大多数服务器的选票,那么就变成Leader
- 如果收到了别人的投票请求,且别人的term比自己的大,那么候选者退化为follower
- 如果选举过程超时,再次发起一轮选举
通过下面的约束来确定唯一 Leader(选举安全性):
- 同一任期内,每个节点只有一票
- 得票(日志信息不旧于Candidate的日志信息)过半则当选为 Leader
成为 Leader 后,向其他节点发送心跳消息来确定自己的地位并阻止新的选举。
当同时满足以下条件时,Follower同意投票:
- RequestVote请求包含的term大于等于当前term
- 日志信息不旧于Candidate的日志信息
- first-come-first-served 先来先得
ES实现的Raft算法选主流程
ES 实现的 Raft 中,选举流程与标准的有很多区别:
- 初始为 Candidate状态
- 执行 PreVote 流程,并拿到 maxTermSeen
- 准备 RequestVote 请求(StartJoinRequest),基于maxTermSeen,将请求中的 term 加1(尚未增加节点当前 term)
- 并行发送 RequestVote,异步处理。目标节点列表中包括本节点。
ES 实现中,候选人不先投自己,而是直接并行发起 RequestVote,这相当于候选人有投票给其他候选人的机会。这样的好处是可以在一定程度上避免3个节点同时成为候选人时,都投自己,无法成功选主的情况。
ES 不限制每个节点在某个 term 上只能投一票,节点可以投多票,这样会产生选出多个主的情况:
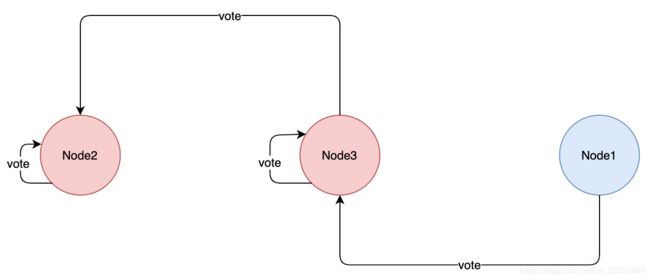
Node2被选为主:收到的投票为:Node2,Node3
Node3被选为主:收到的投票为:Node3,Node1
对于这种情况,ES 的处理是让最后当选的 Leader 成功。作为 Leader,如果收到 RequestVote请求,他会无条件退出 Leader 状态。在本例中,Node2先被选为主,随后他收到 Node3的 RequestVote 请求,那么他退出 Leader 状态,切换为CANDIDATE,并同意向发起 RequestVote候选人投票。因此最终 Node3成功当选为 Leader。
动态维护参选节点列表
在此之前,我们讨论的前提是在集群节点数量不变的情况下,现在考虑下集群扩容,缩容,节点临时或永久离线时是如何处理的。在7.x 之前的版本中,用户需要手工配置 minimum_master_nodes,来明确告诉集群过半节点数应该是多少,并在集群扩缩容时调整他。现在,集群可以自行维护。
在取消了discovery.zen.minimum_master_nodes配置后,ES 如何判断多数?是自己计算和维护minimum_master_nodes值么?不,现在的做法不再记录“quorum” 的具体数值,取而代之的是记录一个节点列表,这个列表中保存所有具备 master 资格的节点(有些情况下不是这样,例如集群原本只有1个节点,当增加到2个的时候,这个列表维持不变,因为如果变成2,当集群任意节点离线,都会导致无法选主。这时如果再增加一个节点,集群变成3个,这个列表中就会更新为3个节点),称为 VotingConfiguration,他会持久化到集群状态中。
在节点加入或离开集群之后,Elasticsearch会自动对VotingConfiguration做出相应的更改,以确保集群具有尽可能高的弹性。在从集群中删除更多节点之前,等待这个调整完成是很重要的。你不能一次性停止半数或更多的节点。(感觉大面积缩容时候这个操作就比较感人了,一部分一部分缩)
默认情况下,ES 自动维护VotingConfiguration,有新节点加入的时候比较好办,但是当有节点离开的时候,他可能是暂时的重启,也可能是永久下线。你也可以人工维护 VotingConfiguration,配置项为:cluster.auto_shrink_voting_configuration,当你选择人工维护时,有节点永久下线,需要通过 voting exclusions API 将节点排除出去。如果使用默认的自动维护VotingConfiguration,也可以使用 voting exclusions API 来排除节点,例如一次性下线半数以上的节点。
如果在维护VotingConfiguration时发现节点数量为偶数,ES 会将其中一个排除在外,保证 VotingConfiguration是奇数。因为当是偶数的情况下,网络分区将集群划分为大小相等的两部分,那么两个子集群都无法达到“多数”的条件。