ElasticSearch为什么检索快?对比Mysql分析
1. ES一定快吗?
1.1. 数据库的索引是B+tree结构
主键是聚合索引 其他索引是非聚合索引,见下图

如果是一般搜索,一般从非聚集索树上搜索出id,然后再到聚集索引树上搜索出需要的内容。
1.2. elasticsearch倒排索引原理

Term Index 以树的形式保存在内存中,运用了FST+压缩公共前缀方法极大的节省了内存,通过Term Index查询到Term Dictionary所在的block再去磁盘上找term减少了IO次数
Term Dictionary 排序后通过二分法将检索的时间复杂度从原来N降低为logN
1.3. 两者对比
对于倒排索引,要分两种情况:
1.3.1. 基于分词后的全文检索
这种情况是es的强项,而对于mysql关系型数据库而言完全是灾难
因为es分词后,每个字都可以利用FST高速找到倒排索引的位置,并迅速获取文档id列表
但是对于mysql检索中间的词只能全表扫(如果不是搜头几个字符)
1.3.2. 精确检索
这种情况我想两种相差不大,有些情况下mysql的可能会更快些
如果mysql的非聚合索引用上了覆盖索引,无需回表,则速度可能更快
es还是通过FST找到倒排索引的位置并获取文档id列表,再根据文档id获取文档并根据相关度算分进行排序,但es还有个杀手锏,即天然的分布式使得在大数据量面前可以通过分片降低每个分片的检索规模,并且可以并行检索提升效率
用filter时更是可以直接跳过检索直接走缓存
1.3.3. 多条件查询
mysql除非使用联合索引,将每个查询的字段都建立联合索引,如果是两个字段上有两个不同的索引,那么mysql将会选择一个索引使用,然后将得到的结果写入内存中使用第二个条件过滤后,得到最终的答案
es,可以进行真正的联合查询,将两个字段上查询出来的结果进行“并”操作或者“与”操作,如果是filter可以使用bitset,如果是非filter使用skip list进行
2. ES如何快速检索
笼统的来说查询数据的快慢和什么有关,首先是查询算法的优劣,其次是数据传输的快慢,以及查询数据的数据量大小。
一般的机械硬盘的读性能在100MB/s左右,再不升级高级硬件的情况下,想要优化查询性能,得从查询算法以及数据量大小两个方面做优化
首先看下es的倒排索引结构,从中分析es为了提高检索性能做了那些的努力
es会为每个term做一个倒排索引
| docId |
年龄 |
性别 |
|---|---|---|
| 1 | 18 | 女 |
| 2 | 20 | 女 |
| 3 | 18 | 男 |
| 年龄 |
Posting List |
|---|---|
| 18 | 【1,3】 |
| 20 | 【2】 |
| 性别 |
Posting List |
|---|---|
| 女 | 【1,2】 |
| 男 | 【3】 |
可以看到,倒排索引是per field的,一个字段由一个自己的倒排索引。18,20这些叫做 term,而[1,3]就是posting list。Posting list就是一个int的数组,存储了所有符合某个term的文档id。
我们可以发现,只要找到term,我们就能找到对应的文档id集合。类似与字典的功能
那么问题来了,海量的数据中我们怎么寻找对应的term?
2.1. Term Index
怎么实现一个字典呢?我们马上想到排序数组,即term字典是一个已经按字母顺序排序好的数组,数组每一项存放着term和对应的倒排文档id列表。每次载入索引的时候只要将term数组载入内存,通过二分查找即可。这种方法查询时间复杂度为Log(N),N指的是term数目,占用的空间大小是O(N*str(term))。排序数组的缺点是消耗内存,即需要完整存储每一个term,当term数目多达上千万时,占用的内存将不可接受。
常用的字典数据结构
| 数据结构 |
优缺点 |
|---|---|
| 排序列表Array/List | 使用二分法查找,不平衡 |
| HashMap/TreeMap | 性能高,内存消耗大,几乎是原始数据的三倍 |
| Skip List | 跳跃表,可快速查找词语,在lucene、redis、Hbase等均有实现。相对于TreeMap等结构,特别适合高并发场景 |
| Trie | 适合英文词典,如果系统中存在大量字符串且这些字符串基本没有公共前缀,则相应的trie树将非常消耗内存 |
| Double Array Trie | 适合做中文词典,内存占用小,很多分词工具均采用此种算法 |
| Ternary Search Tree | 三叉树,每一个node有3个节点,兼具省空间和查询快的优点 |
| Finite State Transducers (FST) | 一种有限状态转移机,Lucene 4有开源实现,并大量使用 |
可以看出在Lucene中使用的是FST,FST有两个优点:1)空间占用小。通过对词典中单词前缀和后缀的重复利用,压缩了存储空间;2)查询速度快。O(len(str))的查询时间复杂度。

FST的性能如何
FST压缩率一般在3倍~20倍之间,相对于TreeMap/HashMap的膨胀3倍,内存节省就有9倍到60倍
| 数据结构 |
HashMap |
TreeMap |
FST |
|---|---|---|---|
| 数据量100w(100w次查询) | 12ms | 9ms |
377ms |
性能虽不如TreeMap和HashMap,但也算良好,能够满足大部分应用的需求
虽然,我们使用了FST压缩Term,但是在ES中term还是太多,是不可能将全部的term拖入内存中的。Term Index保存的不是完整的term,而是保存term一些前缀,可以通过这个前缀快速的定位到磁盘上的block
这样,整个term index的大小可以只有所有term的几十分之一,使得用内存缓存整个term index变成可能
2.2. Term Dictionary
通过term index,我们已经可以拿到需要查询的term的前缀所指向的block地址,进行一次random access(一次random access大概需要10ms的时间)就可以读取这个block中的信息
剩下我们查询对应的term只需要遍历即可,但是如果是海量数据,那么这个时间复杂度O(N)也不能接受。并且可能所要查询的term不在这个block上(可能在下块block上),那么O(N) 我们将N次random access
为了提高term Dictionary的查询效率,term Dictionary是排序好了的结构,这样我们可以在其做二分查找将时间复杂度降低为LogN,那么IO的次数也将大大消耗
上面提到了,提高查询效率,除了改进算法,还有降低数据量大小,Term dictionary在磁盘上是以分block的方式保存的,一个block内部利用公共前缀压缩,比如都是Ab开头的单词就可以把Ab省去。
每个Block最多存48个Term, 如果相同前缀的Term很多的话,Block会分出一个子Block,很显然父Block的公共前缀是子Block公共前缀的前缀。
这样一次读取磁盘的传输数据量大小也将大大降低
这样我们就根据term得到了文档id集合,然后通过路由算法去指定分片中查询内容
3. ES如何做联合查询
在MySQL中,除非使用联合索引,将每个查询的字段都建立联合索引,如果是两个字段上有两个不同的索引,那么mysql将会选择一个索引使用,然后将得到的结果写入内存中使用第二个条件过滤后,得到最终的答案
而在es中, 可以使用真正的联合查询
查询过滤条件 age=18 的过程就是先从 term index 找到 18 在 term dictionary 的大概位置,然后再从 term dictionary 里精确地找到 18 这个 term,然后得到一个 posting list 或者一个指向 posting list 位置的指针。然后再查询 gender= 女 的过程也是类似的。最后得出 age=18 AND gender= 女 就是把两个 posting list 做一个“与”的合并。
这个理论上的“与”合并的操作可不容易。对于 mysql 来说,如果你给 age 和 gender 两个字段都建立了索引,查询的时候只会选择其中最 selective 的来用,然后另外一个条件是在遍历行的过程中在内存中计算之后过滤掉。那么要如何才能联合使用两个索引呢?有两种办法:
- 使用 skip list 数据结构。同时遍历 gender 和 age 的 posting list,互相 skip;
- 使用 bitset 数据结构,对 gender 和 age 两个 filter 分别求出 bitset,对两个 bitset 做 AN 操作。
如果查询的filter缓存到了内存中,使用bitset形式,否则用skip list形式遍历在磁盘上的posting list
3.1. Skip List
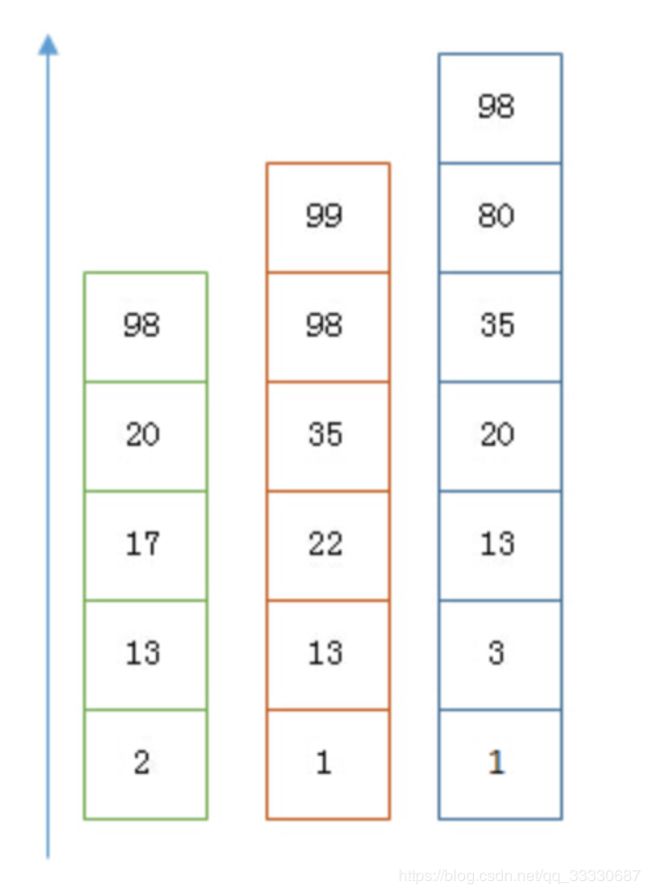
以上是三个 posting list。我们现在需要把它们用 AND 的关系合并,得出 posting list 的交集。首先选择最短的posting list,然后从小到大遍历。遍历的过程可以跳过一些元素,比如我们遍历到绿色的13的时候,就可以跳过蓝色的3了,因为3比13要小。
最后得出的交集是 [13,98],所需的时间比完整遍历三个 posting list 要快得多。但是前提是每个 list 需要指出 Advance 这个操作,快速移动指向的位置。什么样的 list 可以这样 Advance 往前做蛙跳?skip list
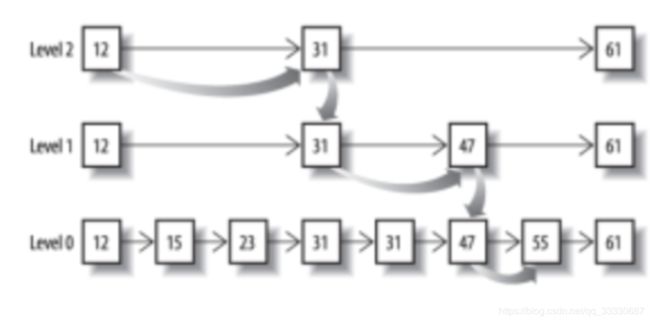
但是这里我们又要考虑一个问题,如果这个posting太长怎么办?
从概念上来说,对于一个很长的posting list,比如:[1,3,13,101,105,108,255,256,257];我们可以把这个list分成三个block:[1,3,13] [101,105,108] [255,256,257];然后可以构建出skip list的第二层:[1,101,255];1,101,255分别指向自己对应的block。这样就可以很快地跨block的移动指向位置了。Lucene自然会对这个block再次进行压缩。
其压缩方式叫做Frame Of Reference编码。
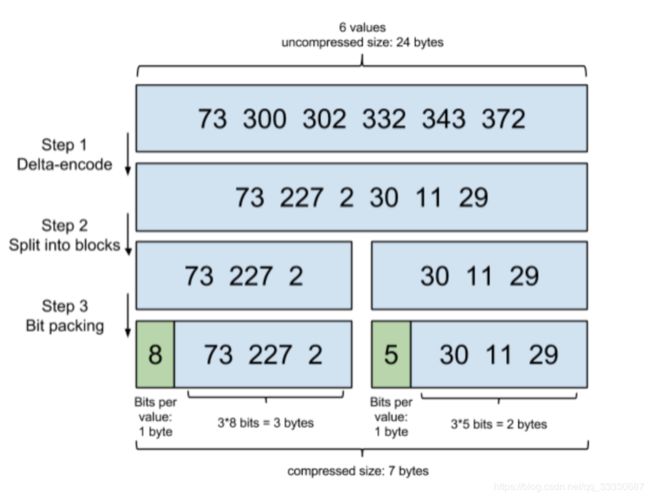
比如一个词对应的文档id列表为[73, 300, 302, 332,343, 372] ,id列表首先要从小到大排好序;第一步增量编码就是从第二个数开始每个数存储与前一个id的差值,即300-73=227,302-300=2。。。,一直到最后一个数;第二步就是将这些差值放到不同的区块,Lucene使用256个区块;第三步位压缩,计算每组3个数中最大的那个数需要占用bit位数,比如30、11、29中最大数30最小需要5个bit位存储,这样11、29也用5个bit位存储,这样才占用15个bit,不到2个字节,压缩效果很好
考虑到频繁出现的term(所谓low cardinality的值),比如gender里的男或者女。如果有1百万个文档,那么性别为男的posting list里就会有50万个int值。用Frame of Reference编码进行压缩可以极大减少磁盘占用。这个优化对于减少索引尺寸有非常重要的意义。当然mysql b-tree里也有一个类似的posting list的东西,是未经过这样压缩的。
因为这个Frame of Reference的编码是有解压缩成本的。利用skip list,除了跳过了遍历的成本,也跳过解压全部这些压缩过的block的过程,从而节省了cpu(相当于只要解压skip list查询到的那些block)
3.2. BitSet合并
Frame Of Reference压缩算法对于倒排表来说效果很好,但对于需要存储在内存中的Filter缓存等不太合适,两者之间有很多不同之处:倒排表存储在磁盘,针对每个词都需要进行编码,而Filter等内存缓存只会存储那些经常使用的数据,而且针对Filter数据的缓存就是为了加速处理效率,对压缩算法要求更高。
缓存之前执行结果的目的就是为了加速响应,本质上是对一系列doc id进行合理的压缩存储然后解码并进行与、或、亦或等逻辑运算
- 方案一:首先一个简单的方案是使用数组存储,这样每个doc id占用4个字节,如果有100M个文档,大约需要400M的内存,比较占用资源,不是一个很好的方式。
- 方案二:BitMap位图方式,用一个bit位(0或者1)来代表一个doc id的存在与否(JDK也有内置的位图类即BitSet);与数组方式类似,只不过这里只用1个bit代表一个文档,节约了存储(100M bits = 12.5MB),这是一种很好的方式。BitSet进行and,or操作,十分方便容易,位运算即可
但是BitSet有一个缺陷:对于一个比较稀疏的文档列表就浪费了很多的存储空间,极端情况段内doc id范围0~2^31-1,一个位图就占用(2^31-1)/8/1024/1024=256M的空间,有压缩改进的空间
从Lucene 5 开始采用了一种改进的位图方式,即Roaring BitMaps,它是一个压缩性能比bitmap更好的位图实现

- 针对每个文档id,得到其对应的元组,即括号中第一个数为除以65535的值,第二个数时对65535取余的值
- 按照除以65535的结果将元组划分到特定的区块中,示例中有0、2、3三个区块
- 对于每个区块,如果元素个数大于4096个,采用BitSet编码,否则对于区块中每个元素使用2个字节编码(取余之后最大值65535使用2个字节即可表示,选择数组存储)
为什么使用4096作为一个阈值,经验证超过4096个数后,使用BitMap方式要比使用数组方式要更高效。

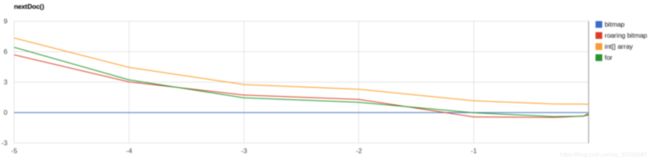
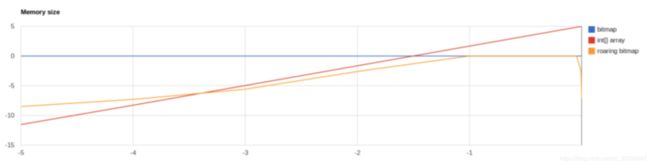
3.2.1. 性能对比
y轴越大,性能越好;x轴越小,文档越稀疏
3.2.2. 内存占用
4. ES如何做聚合排序查询
现在我们想一下,es如何做聚合排序查询的
首先我们拿mysql做例子,如果没有建立索引,我们需要全遍历一份,到内存进行排序,如果有索引,会在索引树上进行进行范围查询(因为索引是排序了的)
那么在es中,如果是做排序,lucene会查询出所有的文档集合的排序字段,然后再次构建出一个排序好的文档集合。es是面向海量数据的,这样一来内存爆掉的可能性是十分大的
我们可以从上面看出,es的倒排索引其实是不利于做排序的。因为存储的是字段→文档id的关系。无法得到需要排序字段的全部值。
为此。es采用Doc Value解决排序,聚合等操作的处理
4.1. Doc Value
DocValues 是一种按列组织的存储格式,这种存储方式降低了随机读的成本。传统的按行存储是这样的:

1 和 2 代表的是 docid。颜色代表的是不同的字段。
改成按列存储是这样的:

按列存储的话会把一个文件分成多个文件,每个列一个。对于每个文件,都是按照 docid 排序的。这样一来,只要知道 docid,就可以计算出这个 docid 在这个文件里的偏移量。也就是对于每个 docid 需要一次随机读操作。
那么这种排列是如何让随机读更快的呢?秘密在于 Lucene 底层读取文件的方式是基于 memory mapped byte buffer 的,也就是 mmap。这种文件访问的方式是由操作系统去缓存这个文件到内存里。这样在内存足够的情况下,访问文件就相当于访问内存。那么随机读操作也就不再是磁盘操作了,而是对内存的随机读。
那么为什么按行存储不能用 mmap 的方式呢?因为按行存储的方式一个文件里包含了很多列的数据,这个文件尺寸往往很大,超过了操作系统的文件缓存的大小。而按列存储的方式把不同列分成了很多文件,可以只缓存用到的那些列,而不让很少使用的列数据浪费内存。
按列存储之后,一个列的数据和前面的 posting list 就差不多了。很多应用在 posting list 上的压缩技术也可以应用到 DocValues 上。这不但减少了文件尺寸,而且提高数据加载的速度。因为我们知道从磁盘到内存的带宽是很小的,普通磁盘也就每秒 100MB 的读速度。利用压缩,我们可以把数据以压缩的方式读取出来,然后在内存里再进行解压,从而获得比读取原始数据更高的效率。
DocValue将随机读取变成了顺序读取,随机读的时候也是按照 DocId 排序的。所以如果读取的 DocId 是紧密相连的,实际上也相当于把随机读变成了顺序读了。Random_read(100), Random_read(101), Random_read(102) 就相当于 Scan(100~102) 了。
在es中,因为分片的存在,数据被拆分成多份,放在不同机器上。但是给用户体验却只有一个库一样
对于聚合查询,其处理是分两阶段完成的:
- Shard 本地的 Lucene Index 并行计算出局部的聚合结果;
- 收到所有的 Shard 的局部聚合结果,聚合出最终的聚合结果。
这种两阶段聚合的架构使得每个 shard 不用把原数据返回,而只用返回数据量小得多的聚合结果。这样极大的减少了网络带宽的消耗
5. 总结
ElasticSearch为了提高检索性能,无所不用的压缩数据,减少磁盘的随机读,以及及其苛刻的使用内存,使用各种快速的搜索算法等手段
追求更快的检索算法 — 倒排,二分
更小的数据传输--- 压缩数据(FST,ROF,公共子前缀压缩)
更少的磁盘读取--- 顺序读(DocValue顺序读)
PS:为什么Mysql不使用真正的联合查询呢?
第一:MySQL没有为每个字段都创建索引,如果是真正的联合查询,可能存在A字段有索引,B字段没有索引,那么根据B字段查询时候就是全表扫描了
第二:MySQL的量没有ES大,ES面向的是海量数据,MySQL做联合查询的时候,可能根据A字段得到的数据只有100或者1000行,在执行B字段过滤,效率很高。但是ES可能经过A字段的搜索有1千万,2千万的数据,执行遍历的过滤效率底下。
每一种技术实现方案都有存在的意义。合理的思考才是最重要的
如果您觉得这篇文章对您有用,欢迎各位关注我的公众号【Java程序喵】
