GO学习笔记
GO学习笔记
文章目录
- GO学习笔记
- go语言特点
- 各种语言性能和学习难度对比
- 变量
- 整型和浮点型
- byte、rune与string
- 数组与切片
- 字典与布尔类型
- 指针
- 结构体和继承
- 函数
- 流程控制
- 接口和多态
- make 和new
- 并发和信道
- 死锁
- 锁
- 异常和处理
- go mod
- 断言
- time的使用
- 上下文 Context
- 踩坑
- Golang:Delve版本太低无法Debug
- 项目实践--prometheus/client_golang/api 源码解析
- 在结构体(struct)中内嵌 接口(interface)
- 为什么要使用接口
go语言特点
特点:
- 编译方便:Go 自带了编译器,因此无须单独安装编译器。
- 语法简单:Go 语言的语法规则严谨,没有歧义,任何人写出的代码都基本一致。Python 代码更自由,而 java 更严谨
- 并发模型:go的并发更加简单
- 强大的标准库:包括互联网应用、系统编程和网络编程
各种语言性能和学习难度对比
python
脚本语言,速度最慢,学习进度短,开发快。豆瓣就是拿python写的。Python著名的服务器框架有django,flask。但是python在大型项目上不太稳定,因此有些用python的企业后来迁移到了java上。
java
编译语言,速度适中,目前的大型网站都是拿java写的,比如淘宝、京东等。主要特点是稳定,开源性好,具有自己的一套编写规范,开发效率适中,目前最主流的语言。
go
执行效率快(速度优于java),学习进度快,可以很方便的写出各种网站服务器,天生支持高并发。常用的框架是golang。
c++
执行速度最快,但是写起来最为复杂,开发难度大,没有很著名的框架。
变量
var
var = ""
:= ""
var (
)
,:= "",""
:= new()
使用表达式 new(Type) 将创建一个Type类型的匿名变量,初始化为Type类型的零值,然后返回变量地址,返回的指针类型为*Type。
整型和浮点型
-
当你在32位的系统下,int 和 uint 都占用 4个字节,也就是32位。
-
若你在64位的系统下,int 和 uint 都占用 8个字节,也就是64位。
出于这个原因,在某些场景下,你应当避免使用 int 和 uint ,而使用更加精确的 int32 和 int64
var num int = 10 10进制
var num01 int = 0b1100 2进制
var num02 int = 0o14 8进制
var num03 int = 0xC 16进制
3.7E-2`表示浮点数`0.037
float32,也即我们常说的单精度,存储占用4个字节,也即4*8=32位,其中1位用来符号,8位用来指数,剩下的23位表示尾数
 引用自知乎回答
引用自知乎回答
float64,也即我们熟悉的双精度,存储占用8个字节,也即8*8=64位,其中1位用来符号,11位用来指数,剩下的52位表示尾数
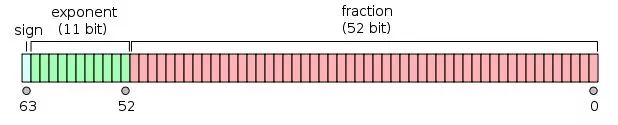 引用自知乎回答
引用自知乎回答
精度主要取决于尾数部分的位数。
对于 float32(单精度)来说,表示尾数的为23位,除去全部为0的情况以外,最小为2-23,约等于1.19*10-7,所以float小数部分只能精确到后面6位,加上小数点前的一位,即有效数字为7位。
同理 float64(双精度)的尾数部分为 52位,最小为2-52,约为2.22*10-16,所以精确到小数点后15位,加上小数点前的一位,有效位数为16位。
浮点数类型的取值范围可以从很微小到很巨大,这个取决于指数。
byte、rune与string
在 Go 中单引号与 双引号并不是等价的。
单引号用来表示字符,在上面的例子里,如果你使用双引号,就意味着你要定义一个字符串,赋值时与前面声明的前面会不一致,这样在编译的时候就会出错。
byte 和 uint8 没有区别,rune 和 int32 没有区别。byte用于表示ACSII 表中的一个字符,rune用于表示中文。
string 的本质,其实是一个 byte数组
数组与切片
数组
// 第一种方法
var arr [3]int = [3]int{1,2,3}
// 第二种方法
arr := [3]int{1,2,3}
切片
myarr := []int{1}
// 追加一个元素
myarr = append(myarr, 2)
// 追加多个元素
myarr = append(myarr, 3, 4)
// 追加一个切片, ... 表示解包,不能省略
myarr = append(myarr, []int{7, 8}...)
// 在第一个位置插入元素
myarr = append([]int{0}, myarr...)
// 在中间插入一个切片(两个元素)
myarr = append(myarr[:5], append([]int{5,6}, myarr[5:]...)...)
字典与布尔类型
字典
// 第一种方法
var scores map[string]int = map[string]int{"english": 80, "chinese": 85}
// 第二种方法
scores := map[string]int{"english": 80, "chinese": 85}
// 第三种方法
scores := make(map[string]int)
scores["english"] = 80
scores["chinese"] = 85
字典的下标读取可以返回两个值,使用第二个返回值都表示对应的 key 是否存在,若存在ok为true,若不存在,则ok为false
关于布尔值,无非就两个值:true 和 false。只是这两个值,在不同的语言里可能不同。
在 Python 中,真值用 True 表示,与 1 相等,假值用 False 表示,与 0 相等
而在 Go 中,真值用 true 表示,不但不与 1 相等,并且更加严格,不同类型无法进行比较,而假值用 false 表示,同样与 0 无法比较。
指针
指针创建有三种方法
第一种方法
先定义对应的变量,再通过变量取得内存地址,创建指针
// 定义普通变量
aint := 1
// 定义指针变量
ptr := &aint
第二种方法
先创建指针,分配好内存后,再给指针指向的内存地址写入对应的值。
// 创建指针
astr := new(string)
// 给指针赋值
*astr = "Go编程时光"
第三种方法
先声明一个指针变量,再从其他变量取得内存地址赋值给它
aint := 1
var bint *int // 声明一个指针
bint = &aint // 初始化
Go 语言在传递参数时其实使用的就是传值的方式,接收方收到参数时会对这些参数进行复制;了解到这一点之后,在传递数组或者内存占用非常大的结构体时,我们在一些函数中应该尽量使用指针作为参数类型来避免发生大量数据的拷贝而影响性能。
待续
结构体和继承
可以理解为 Go语言 的结构体struct和其他语言的class有相等的地位,但是Go语言放弃大量面向对象的特性,所有的Go语言类型除了指针类型外,都可以有自己的方法,提高了可扩展性。
GO语言的继承通过匿名字段实现
在 Go 语言中,函数名的首字母大小写非常重要,它被来实现控制对方法的访问权限。
- 当方法的首字母为大写时,这个方法对于所有包都是Public,其他包可以随意调用
- 当方法的首字母为小写时,这个方法是Private,其他包是无法访问的。
待续
函数
函数的声明,使用 func 关键字,后面依次接 函数名,参数列表,返回值列表,用 {} 包裹的代码逻辑体
func 函数名(形式参数列表)(返回值列表){
函数体
}
多个类型一致的参数。
使用 ...int,表示一个元素为int类型的切片,用来接收调用者传入的参数。
// 使用 ...类型,表示一个元素为int类型的切片
func sum(args ...int) int {
var sum int
for _, v := range args {
sum += v
}
return sum
}
func main() {
fmt.Println(sum(1, 2, 3))
}
// output: 6
其中 ... 是 Go 语言为了方便程序员写代码而实现的语法糖,如果该函数下会多个类型的函数,这个语法糖必须得是最后一个参数。
同时这个语法糖,只能在定义函数时使用。
匿名函数
定义变量名,是一个不难但是还费脑子的事情,对于那到只使用一次的函数,是没必要拥有姓名的。这才有了匿名函数。
有了这个背景,决定了匿名函数只有拥有短暂的生命,一般都是定义后立即使用。
就像这样,定义后立马执行(这里只是举例,实际代码没有意义)。
func(data int) {
fmt.Println("hello", data)
}(100)
流程控制
Go里的流程控制方法还是挺丰富,整理了下有如下这么多种:
- if - else 条件语句
- switch - case 选择语句
- for - range 循环语句
- goto 无条件跳转语句
- defer 延迟执行
接口和多态
在 Go 语言中,是通过接口来实现的多态。
在一个接口(老师)下,在不同对象(人)上的不同表现,这就是多态。
待续
make 和new
new
new 只能传递一个参数,该参数为一个任意类型,可以是Go语言内建的类型,也可以是你自定义的类型
那么 new 函数到底做了哪些事呢:
- 分配内存
- 设置零值
- 返回指针(重要)
举个例子
import "fmt"
type Student struct {
name string
age int
}
func main() {
// new 一个内建类型
num := new(int)
fmt.Println(*num) //打印零值:0
// new 一个自定义类型
s := new(Student)
s.name = "wangbm"
}
make
- 用来为 slice,map 或 chan 类型(注意:也只能用在这三种类型上)分配内存和初始化一个对象
- make 返回类型的本身而不是指针,而返回值也依赖于具体传入的类型,因为这三种类型(slice,map 和 chan)本身就是引用类型,所以就没有必要返回他们的指针了
由于这三种类型都是引用类型,所以必须得初始化(size和cap),但是不是置为零值,这个和new是不一样的。
举几个例子
//切片
a := make([]int, 2, 10)
// 字典
b := make(map[string]int)
// 通道
c := make(chan int, 10)
new:为所有的类型分配内存,并初始化为零值,返回指针。
make:只能为 slice,map,chan 分配内存,并初始化,返回的是类型。
并发和信道
信道实例 := make(chan 信道类型,容量大小)
一般创建信道都是使用 make 函数,make 函数接收两个参数
- 第一个参数:必填,指定信道类型
- 第二个参数:选填,不填默认为0,指定信道的容量(可缓存多少数据)
对于信道的容量,很重要,这里要多说几点:
-
当容量为0时,说明信道中不能存放数据,在发送数据时,必须要求立马有人接收,否则会报错。此时的信道称之为无缓冲信道。
-
当容量为1时,说明信道只能缓存一个数据,若信道中已有一个数据,此时再往里发送数据,会造成程序阻塞。 利用这点可以利用信道来做锁。
-
当容量大于1时,信道中可以存放多个数据,可以用于多个协程之间的通信管道,共享资源。
假如我要创建一个可以传输int类型的信道,可以这样子写。
// 定义信道
pipline := make(chan int)
信道的数据操作,无非就两种:发送数据与读取数据
// 往信道中发送数据
pipline<- 200
// 从信道中取出数据,并赋值给mydata
mydata := <-pipline
信道用完了,可以对其进行关闭,避免有人一直在等待。
close(pipline)
对一个已关闭的信道再关闭,是会报错的。所以我们还要学会,如何判断一个信道是否被关闭?
当从信道中读取数据时,可以有多个返回值,其中第二个可以表示 信道是否被关闭,如果已经被关闭,ok 为 false,若还没被关闭,ok 为true。
x, ok := <-pipline
单向信道
<-chan表示这个信道,只能从里发出数据,对于程序来说就是只读chan<-表示这个信道,只能从外面接收数据,对于程序来说就是只写
死锁
fatal error: all goroutines are asleep - deadlock!
- 对于无缓冲信道,在接收者未准备好之前,发送操作是阻塞的
- 当信道里的数据量等于信道的容量后,此时再往信道里发送数据,就失造成阻塞,必须等到有人从信道中消费数据后,程序才会往下进行。
- 当程序一直在等待从信道里读取数据,而此时并没有人会往信道中写入数据。此时程序就会陷入死循环,造成死锁。
WaitGroup
var 实例名 sync.WaitGroup
实例化完成后,就可以使用它的几个方法:
Add:初始值为0,你传入的值会往计数器上加,这里直接传入你子协程的数量Done:当某个子协程完成后,可调用此方法,会从计数器上减一,通常可以使用 defer 来调用。Wait:阻塞当前协程,直到实例里的计数器归零。
锁
互斥锁
使用互斥锁(Mutex,全称 mutual exclusion)是为了来保护一个资源不会因为并发操作而引起冲突导致数据不准确。
import (
"fmt"
"sync"
)
func add(count *int, wg *sync.WaitGroup, lock *sync.Mutex) {
for i := 0; i < 1000; i++ {
lock.Lock()
*count = *count + 1
lock.Unlock()
}
wg.Done()
}
func main() {
var wg sync.WaitGroup
lock := &sync.Mutex{}
count := 0
wg.Add(3)
go add(&count, &wg, lock)
go add(&count, &wg, lock)
go add(&count, &wg, lock)
wg.Wait()
fmt.Println("count 的值为:", count)
}
此时,不管你执行多少次,输出都只有一个结果
count 的值为: 3000
使用 Mutext 锁虽然很简单,但仍然有几点需要注意:
- 同一协程里,不要在尚未解锁时再次使加锁
- 同一协程里,不要对已解锁的锁再次解锁
- 加了锁后,别忘了解锁,必要时使用 defer 语句
读写锁
RWMutex,也是如此,它将程序对资源的访问分为读操作和写操作
- 为了保证数据的安全,它规定了当有人还在读取数据(即读锁占用)时,不允计有人更新这个数据(即写锁会阻塞)
- 为了保证程序的效率,多个人(线程)读取数据(拥有读锁)时,互不影响不会造成阻塞,它不会像 Mutex 那样只允许有一个人(线程)读取同一个数据。
异常和处理
Golang 异常的抛出与捕获,依赖两个内置函数:
- panic:抛出异常,使程序崩溃
- recover:捕获异常,恢复程序或做收尾工作
revocer 调用后,抛出的 panic 将会在此处终结,不会再外抛,但是 recover,并不能任意使用,它有强制要求,必须得在 defer 下才能发挥用途。
go mod
版本和包管理
go env -w GO111MODULE="on" //开启
go mod init yourpath //初始化
go mod tidy //整理检查依赖,如果缺失包会下载或者引用的不需要的包会删除
断言
Type Assertion(中文名叫:类型断言),通过它可以做到以下几件事情
- 检查
i是否为 nil - 检查
i存储的值是否为某个类型
time的使用
//获取当前时间
t := time.Now() //2018-07-11 15:07:51.8858085 +0800 CST m=+0.004000001
fmt.Println(t)
//获取当前时间戳
fmt.Println(t.Unix()) //1531293019
//获得当前的时间
fmt.Println(t.Uninx().Format("2006-01-02 15:04:05")) //2018-7-15 15:23:00
//时间 to 时间戳
loc, _ := time.LoadLocation("Asia/Shanghai") //设置时区
tt, _ := time.ParseInLocation("2006-01-02 15:04:05", "2018-07-11 15:07:51", loc) //2006-01-02 15:04:05是转换的格式如php的"Y-m-d H:i:s"
fmt.Println(tt.Unix()) //1531292871
//时间戳 to 时间
tm := time.Unix(1531293019, 0)
fmt.Println(tm.Format("2006-01-02 15:04:05")) //2018-07-11 15:10:19
//获取当前年月日,时分秒
y := t.Year() //年
m := t.Month() //月
d := t.Day() //日
h := t.Hour() //小时
i := t.Minute() //分钟
s := t.Second() //秒
fmt.Println(y, m, d, h, i, s) //2018 July 11 15 24 59
上下文 Context
当最上层的 Goroutine 因为某些原因执行失败时,下层的 Goroutine 由于没有接收到这个信号所以会继续工作;但是当我们正确地使用 context.Context 时,就可以在下层及时停掉无用的工作以减少额外资源的消耗
待续
比如可以设定一个时间,当函数的计算超过这个时间,整个程序就会终止。
我们可以通过一个代码片段了解 context.Context 是如何对信号进行同步的。在这段代码中,我们创建了一个过期时间为 1s 的上下文,并向上下文传入 handle 函数,该方法会使用 500ms 的时间处理传入的『请求』:
func main() {
ctx, cancel := context.WithTimeout(context.Background(), 1*time.Second)
defer cancel()
go handle(ctx, 500*time.Millisecond)
select {
case <-ctx.Done():
fmt.Println("main", ctx.Err())
}
}
func handle(ctx context.Context, duration time.Duration) {
select {
case <-ctx.Done():
fmt.Println("handle", ctx.Err())
case <-time.After(duration):
fmt.Println("process request with", duration)
}
}
因为过期时间大于处理时间,所以我们有足够的时间处理该『请求』,运行上述代码会打印出如下所示的内容:
$ go run context.go
process request with 500ms
main context deadline exceeded
handle 函数没有进入超时的 select 分支,但是 main 函数的 select 却会等待 context.Context 的超时并打印出 main context deadline exceeded。
如果我们将处理『请求』时间增加至 1500ms,整个程序都会因为上下文的过期而被中止,:
$ go run context.go
main context deadline exceeded
handle context deadline exceeded
相信这两个例子能够帮助各位读者理解 context.Context 的使用方法和设计原理 — 多个 Goroutine 同时订阅 ctx.Done() 管道中的消息,一旦接收到取消信号就立刻停止当前正在执行的工作。
定义一个空的上下文
C := context.Background()
踩坑
使用变量一定要分配内存片
像var 这样的变量是不能直接使用的。
比如定义一个链表
var b ListNode
b.Val=1
b1 := b.Next
*b1.Val = 1
这样会报空指针异常,应该这样写
head := new(ListNode)
head.Val = 1
var node1 = new(ListNode)
node1.Val = 2
head.Next = node1
Golang:Delve版本太低无法Debug
调试的时候报错:
Version of Go is too old for this version of Delve (minimum supported version 1.13, suppress this error with --check-go-version=false)
解决办法:
go get github.com/go-delve/delve/cmd/dlv
然后打开:Help->Edit Customer Properties;若提示文件不存在,点击创建即可。在文件中新增:dlv.path=你的dlv路径(windows的路径需要转义)
项目实践–prometheus/client_golang/api 源码解析
我们的目标是调用prometheus的api接口完成查询,怀着这个目的去解析client_golang是怎么样实现的,怎么设计的。源码在github上可以看到。
我们使用的代码:
package main
import (
"context"
"fmt"
"github.com/prometheus/client_golang/api"
v1 "github.com/prometheus/client_golang/api/prometheus/v1"
"time"
)
func main() {
loc, _ := time.LoadLocation("Asia/Shanghai")
tt,_ :=time.ParseInLocation("2006-01-02 15:04:05","2020-05-19 13:48:12",loc)
C := context.Background()
client,_:=api.NewClient(api.Config{Address : "http://ip:port"})
clientAPI:=v1.NewAPI(client)
data,_,_:=clientAPI.Query(C,"data_field1",tt)
fmt.Println(data)
}
main函数的前三行就是定义了一个时间和一个空的上下文,因为查询接口需要用到。
来看第四行client,_:=api.NewClient(api.Config{Address : "http://ip:port"})
内层输入参数是一个Config类型的参数,这个参数是自己定义的。
type Config struct {
// The address of the Prometheus to connect to.
Address string
// RoundTripper is used by the Client to drive HTTP requests. If not
// provided, DefaultRoundTripper will be used.
RoundTripper http.RoundTripper
}
api.Config{Address : "http://ip:port"}这句就是定义了一个Config结构体。使用默认的RoundTripper就可以。(RoundTripper是表示执行单个HTTP事务,获取给定请求的响应的能力的接口)
外层是一个api.NewClient函数,在go里面New开头的函数都是java里面的构造函数。我们点进去看一下这个函数。输入参数是Config、输出参数是Client、error。
func NewClient(cfg Config) (Client, error) {
u, err := url.Parse(cfg.Address)
if err != nil {
return nil, err
}
u.Path = strings.TrimRight(u.Path, "/")
return &httpClient{
endpoint: u,
client: http.Client{Transport: cfg.roundTripper()},
}, nil
}
第二行使用了url包的Parse函数,把地址传输给了这个函数。输入参数是个string、输出是*URL,error。
func Parse(rawurl string) (*URL, error) {
// Cut off #frag
u, frag := split(rawurl, '#', true)
url, err := parse(u, false)
if err != nil {
return nil, &Error{"parse", u, err}
}
if frag == "" {
return url, nil
}
if url.Fragment, err = unescape(frag, encodeFragment); err != nil {
return nil, &Error{"parse", rawurl, err}
}
return url, nil
}
第二行将url分解,附上split代码,就不多解释了
func split(s string, sep byte, cutc bool) (string, string) {
i := strings.IndexByte(s, sep)
if i < 0 {
return s, ""
}
if cutc {
return s[:i], s[i+1:]
}
return s[:i], s[i:]
}
第三行调用parse函数,注意和Parse不同,go严格区分大小写。以下中文注释皆为手动注释。
func parse(rawurl string, viaRequest bool) (*URL, error) {
var rest string
var err error
if stringContainsCTLByte(rawurl) { //判断是否包含任何ASCII控制字符(null等)
return nil, errors.New("net/url: invalid control character in URL")
}
if rawurl == "" && viaRequest { //判断是否为空
return nil, errors.New("empty url")
}
url := new(URL) //定义了一个URL结构体,后面给出源码
if rawurl == "*" { //如果*,返回*
url.Path = "*"
return url, nil
}
// Split off possible leading "http:", "mailto:", etc.
// Cannot contain escaped characters.
if url.Scheme, rest, err = getscheme(rawurl); err != nil {
return nil, err
}
url.Scheme = strings.ToLower(url.Scheme)
if strings.HasSuffix(rest, "?") && strings.Count(rest, "?") == 1 {
url.ForceQuery = true
rest = rest[:len(rest)-1]
} else {
rest, url.RawQuery = split(rest, '?', true)
}
if !strings.HasPrefix(rest, "/") {
if url.Scheme != "" {
// We consider rootless paths per RFC 3986 as opaque.
url.Opaque = rest
return url, nil
}
if viaRequest {
return nil, errors.New("invalid URI for request")
}
// Avoid confusion with malformed schemes, like cache_object:foo/bar.
// See golang.org/issue/16822.
//
// RFC 3986, §3.3:
// In addition, a URI reference (Section 4.1) may be a relative-path reference,
// in which case the first path segment cannot contain a colon (":") character.
colon := strings.Index(rest, ":")
slash := strings.Index(rest, "/")
if colon >= 0 && (slash < 0 || colon < slash) {
// First path segment has colon. Not allowed in relative URL.
return nil, errors.New("first path segment in URL cannot contain colon")
}
}
if (url.Scheme != "" || !viaRequest && !strings.HasPrefix(rest, "///")) && strings.HasPrefix(rest, "//") {
var authority string
authority, rest = split(rest[2:], '/', false)
url.User, url.Host, err = parseAuthority(authority)
if err != nil {
return nil, err
}
}
// Set Path and, optionally, RawPath.
// RawPath is a hint of the encoding of Path. We don't want to set it if
// the default escaping of Path is equivalent, to help make sure that people
// don't rely on it in general.
if err := url.setPath(rest); err != nil {
return nil, err
}
return url, nil
}
虽然步骤很多,但都是对url的一个判断,最后返回一个URL类型的指针地址。
type URL struct {
Scheme string
Opaque string // encoded opaque data
User *Userinfo // username and password information
Host string // host or host:port
Path string // path (relative paths may omit leading slash)
RawPath string // encoded path hint (see EscapedPath method)
ForceQuery bool // append a query ('?') even if RawQuery is empty
RawQuery string // encoded query values, without '?'
Fragment string // fragment for references, without '#'
}
parse再判断一下之后,返回这个URL类型的指针地址。
最后根据返回的URL结构体,NewClient
type httpClient struct {
endpoint *url.URL
client http.Client
}
再NewAPI
type httpAPI struct {
client apiClient
}
最后调用API的Query方法
type API interface {
...
// Query performs a query for the given time.
Query(ctx context.Context, query string, ts time.Time) (model.Value, Warnings, error)
...
}
func (h *httpAPI) Query(ctx context.Context, query string, ts time.Time) (model.Value, Warnings, error) {
u := h.client.URL(epQuery, nil)//将接口加入URL
q := u.Query()
q.Set("query", query)
if !ts.IsZero() { //判断时间
q.Set("time", formatTime(ts))
}
_, body, warnings, err := h.client.DoGetFallback(ctx, u, q)
if err != nil {
return nil, warnings, err
}
var qres queryResult
return model.Value(qres.v), warnings, json.Unmarshal(body, &qres)
}
eqQuery是预先定义好的接口
const (
statusAPIError = 422
apiPrefix = "/api/v1"
...
epQuery = apiPrefix + "/query"
...
)
URL也有查询方法
func (u *URL) Query() Values {
v, _ := ParseQuery(u.RawQuery)
return v
}
返回值是一个values,将请求条件和时间放进去
type Values map[string][]string
调用DoGetFallback
// DoGetFallback will attempt to do the request as-is, and on a 405 it will fallback to a GET request.
func (h *apiClientImpl) DoGetFallback(ctx context.Context, u *url.URL, args url.Values) (*http.Response, []byte, Warnings, error) {
req, err := http.NewRequest(http.MethodPost, u.String(), strings.NewReader(args.Encode()))
if err != nil {
return nil, nil, nil, err
}
req.Header.Set("Content-Type", "application/x-www-form-urlencoded")
resp, body, warnings, err := h.Do(ctx, req)
if resp != nil && resp.StatusCode == http.StatusMethodNotAllowed {
u.RawQuery = args.Encode()
req, err = http.NewRequest(http.MethodGet, u.String(), nil)
if err != nil {
return nil, nil, warnings, err
}
} else {
if err != nil {
return resp, body, warnings, err
}
return resp, body, warnings, nil
}
return h.Do(ctx, req)
}
请求的结构体,最后返回的Body就是data。
req := &Request{
ctx: ctx,
Method: method,
URL: u,
Proto: "HTTP/1.1",
ProtoMajor: 1,
ProtoMinor: 1,
Header: make(Header),
Body: rc,
Host: u.Host,
}
Do方法实际上就是发http请求了,各种判断弄了几层,就不展开解释了。
通过这次源码解读,我发现其使用的结构基本上是使用一个结构体,然后去实现这个接口所有方法。这样在new的时候直接返回结构的地址就是接口,可以直接使用。
在结构体(struct)中内嵌 接口(interface)
1, 初始化的时候,内嵌接口要用一个实现此接口的结构体赋值
2,外层结构体中,只能调用内层接口定义的函数。 这是由于编译时决定。
3,外层结构体,可以作为receiver,重新定义同名函数,这样可以覆盖内层内嵌结构中定义的函数
4,如果上述第3条实现,那么可以用外层结构体引用内嵌接口的实例,并调用内嵌接口的函数
例:
package main
import "fmt"
type Printer interface{
Print()
}
type CanonPrinter struct{
Printname string
}
func (printer CanonPrinter) Print(){
fmt.Println("this is cannoprinter printing now")
}
type PrintWorker struct{
Printer
name string
age int
}
func (printworker PrintWorker) Print(){
fmt.Println("this is printing from PrintWorker")
printworker.Printer.Print() // 这里 printworker 首先引用内部嵌入Printer接口的实例,然后调用Printer 接口实例的Print()方法
}
func main(){
canon := new(CanonPrinter)
canon.Printname="one1"
printworker := PrintWorker{Printer:canon,name: "ansendong", age: 34}
printworker.Printer.Print()
printworker.Print()
}
为什么要使用接口
java
实现具体功能时,接口和实现的类分离。接口定义为XxxService,实现为XxxServiceImpl。
接口提供了一个公用的方法提供方。 接口是用来规定子类的行为的。
面向接口编程的好处:
1.根据客户提出的需求提出来,作为接口的;业务具体实现是通过实现接口类来完成的。
2.当客户提出新的需求时,只需编写该需求业务逻辑新的实现类。
3.假如采用了这种模式,业务逻辑更加清晰,增强代码可读性,扩展性,可维护性。
4.接口和实现分离,适合团队协作开发。
5.实现松散耦合的系统,便于以后升级,扩展。
package main
import “fmt”
type Printer interface{
Print()
}
type CanonPrinter struct{
Printname string
}
func (printer CanonPrinter) Print(){
fmt.Println(“this is cannoprinter printing now”)
}
type PrintWorker struct{
Printer
name string
age int
}
func (printworker PrintWorker) Print(){
fmt.Println(“this is printing from PrintWorker”)
printworker.Printer.Print() // 这里 printworker 首先引用内部嵌入Printer接口的实例,然后调用Printer 接口实例的Print()方法
}
func main(){
canon := new(CanonPrinter)
canon.Printname=“one1”
printworker := PrintWorker{Printer:canon,name: “ansendong”, age: 34}
printworker.Printer.Print()
printworker.Print()
}
## 为什么要使用接口
java
实现具体功能时,接口和实现的类分离。接口定义为XxxService,实现为XxxServiceImpl。
接口提供了一个公用的方法提供方。 接口是用来规定子类的行为的。
面向接口编程的好处:
1.根据客户提出的需求提出来,作为接口的;业务具体实现是通过实现接口类来完成的。
2.当客户提出新的需求时,只需编写该需求业务逻辑新的实现类。
3.假如采用了这种模式,业务逻辑更加清晰,增强代码可读性,扩展性,可维护性。
4.接口和实现分离,适合团队协作开发。
5.实现松散耦合的系统,便于以后升级,扩展。