jpa的使用和详解
最近在公司频繁地使用jpa ,也阅读很多更大网站的文章,现在我把阅读过的文章总结成一篇
Bean Validation是JavaEE6数据验证新框架,ValidationAPI并不依赖特定的应用层或是编程模型,这样同一套验证可由应用的所有层共享.它还提供了通过扩展ValidationAPI来增加客户化验证约束的机制以及查询约束元数据仓库的手段.
在Java EE6的BeanValidation出现之前,开发者不得不在表示层框架、业务层以及持久层中编写验证规则以保证这些规则的同步性,但这么做非常浪费时间而且极易出错.BeanValidation是通过约束实现的,这些约束以注解的形式出现,注解可以放在JavaBean(如backingbean)的属性、方法或是类上面.约束既可以是内建的注解(位于javax.validation.constraints包下面),也可以由用户定义。一些常用的内建注解列举如下:
◆Min:被@Min所注解的元素必须是个数字,其值要大于或等于给定的最小值。
◆Max:被@Max所注解的元素必须是个数字,其值要小于或等于给定的最大值。
◆Size:@Size表示被注解的元素必须位于给定的最小值和最大值之间。支持Size验证的数据类型有String、Collection(计算集合的大小)、Map以及数组。
◆NotNull:@NotNull确保被注解的元素不能为null。
◆Null:@Null确保被注解的元素一定为null。
◆Pattern:@Pattern确保被注解的元素(String)一定会匹配给定的Java正则表达式。
Hibernate4之JPA规范配置详解
@Table
Table用来定义entity主表的name,catalog,schema等属性。属性说明:
- name:表名
- catalog:对应关系数据库中的catalog
- schema:对应关系数据库中的schema
- UniqueConstraints:定义一个UniqueConstraint数组,指定需要建唯一约束的列.UniqueConstraint定义在Table或SecondaryTable元数据里,用来指定建表时需要建唯一约束的列。下面是指定2个字段要唯一约束.
Example:
@Entity
@Table(
name="EMPLOYEE",
uniqueConstraints=
@UniqueConstraint(columnNames={"EMP_ID", "EMP_NAME"})
)
public class Employee { ... }@ID 和 @GeneratedValue
通过annotation来映射hibernate实体的,基于annotation的hibernate主键标识为@Id,
其生成规则由@GeneratedValue设定的.这里的@id和@GeneratedValue都是JPA的标准用法,
JPA提供四种标准用法,由@GeneratedValue的源代码可以明显看出.
@Target({METHOD, FIELD})
@Retention(RUNTIME)
public @interface GeneratedValue {
GenerationType strategy() default AUTO;
String generator() default "";
}package javax.persistence;
public enum GenerationType {
TABLE,
SEQUENCE,
IDENTITY,
AUTO
}- TABLE:使用一个特定的数据库表格来保存主键。
- SEQUENCE:根据底层数据库的序列来生成主键,条件是数据库支持序列。
- IDENTITY:主键由数据库自动生成(主要是自动增长型)
- AUTO:主键由程序控制(也是默认的,在指定主键时,如果不指定主键生成策略,默认为AUTO)
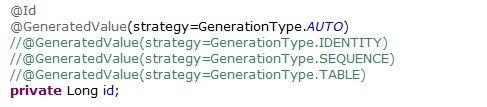
@Id
@GeneratedValue
private Long id;四种数据库的支持情况如下:
| 数据库名称 |
支持的id策略 |
| mysql |
GenerationType.TABLE |
| oracle |
strategy=GenerationType.AUTO |
| postgreSQL |
GenerationType.TABLE |
| kingbase |
GenerationType.TABLE |
@GeneratedValue:主键的产生策略,通过strategy属性指定。
主键产生策略通过GenerationType来指定。GenerationType是一个枚举,它定义了主键产生策略的类型。
1、AUTO 自动选择一个最适合底层数据库的主键生成策略。如MySQL会自动对应auto increment。这个是默认选项,即如果只写@GeneratedValue,等价于@GeneratedValue(strategy=GenerationType.AUTO)。
2、IDENTITY 表自增长字段,Oracle不支持这种方式。
3、SEQUENCE 通过序列产生主键,MySQL不支持这种方式。
4、TABLE 通过表产生主键,框架借由表模拟序列产生主键,使用该策略可以使应用更易于数据库移植。不同的JPA实现商生成的表名是不同的,如 OpenJPA生成openjpa_sequence_table表,Hibernate生成一个hibernate_sequences表,而TopLink则生成sequence表。这些表都具有一个序列名和对应值两个字段,如SEQ_NAME和SEQ_COUNT。
在我们的应用中,一般选用@GeneratedValue(strategy=GenerationType.AUTO)这种方式,自动选择主键生成策略,以适应不同的数据库移植。
如果使用Hibernate对JPA的实现,可以使用Hibernate对主键生成策略的扩展,通过Hibernate的@GenericGenerator实现。

@GenericGenerator(name = "system-uuid", strategy = "uuid") 声明一个策略通用生成器,name为"system-uuid",策略strategy为"uuid"。
@GeneratedValue(generator = "system-uuid") 用generator属性指定要使用的策略生成器。
这是我在项目中使用的一种方式,生成32位的字符串,是唯一的值。最通用的,适用于所有数据库。
构建CriteriaQuery 实例API说明
1.CriteriaBuilder 安全查询创建工厂,创建CriteriaQuery,创建查询具体具体条件Predicate 等
CriteriaBuilder是一个工厂对象,安全查询的开始.用于构建JPA安全查询.可以从EntityManager 或 EntityManagerFactory类中获得CriteriaBuilder.比如: CriteriaBuilder criteriaBuilder = em.getCriteriaBuilder();
2.CriteriaQuery 安全查询主语句
CriteriaQuery对象必须在实体类型或嵌入式类型上的Criteria 查询上起作用。
它通过调用 CriteriaBuilder, createQuery 或CriteriaBuilder.createTupleQuery 获得。
CriteriaBuilder就像CriteriaQuery 的工厂一样。
CriteriaBuilder工厂类是调用EntityManager.getCriteriaBuilder 或 EntityManagerFactory.getCriteriaBuilder而得。
Employee实体的 CriteriaQuery 对象以下面的方式创建:
CriteriaBuilder criteriaBuilder = em.getCriteriaBuilder();
CriteriaQuery criteriaQuery = criteriaBuilder.createQuery(Employee.class); 3.Root 定义查询的From子句中能出现的类型
AbstractQuery是CriteriaQuery 接口的父类。它提供得到查询根的方法。Criteria查询的查询根定义了实体类型,能为将来导航获得想要的结果,它与SQL查询中的FROM子句类似。
Root实例也是类型化的,且定义了查询的FROM子句中能够出现的类型。
查询根实例能通过传入一个实体类型给 AbstractQuery.from方法获得。
Criteria查询,可以有多个查询根。
Employee实体的查询根对象可以用以下的语法获得 :
Root employee = criteriaQuery.from(Employee.class); 4.Predicate 过滤条件
过滤条件应用到SQL语句的FROM子句中。在criteria 查询中,查询条件通过Predicate 或Expression 实例应用到CriteriaQuery 对象上。
这些条件使用 CriteriaQuery .where 方法应用到CriteriaQuery 对象上。
CriteriaBuilder 也是作为Predicate 实例的工厂,Predicate 对象通过调用CriteriaBuilder 的条件方法( equal,notEqual, gt, ge,lt, le,between,like等)创建。
Predicate 实例也可以用Expression 实例的 isNull, isNotNull 和 in方法获得,复合的Predicate 语句可以使用CriteriaBuilder的and, or andnot 方法构建。
下面的代码片段展示了Predicate 实例检查年龄大于24岁的员工实例:
Predicate condition = criteriaBuilder.gt(employee.get(Employee_.age), 24);
criteriaQuery.where(condition);过Employee_元模型类age属性,称之为路径表达式。若age属性与String文本比较,编译器会抛出错误,这在JPQL中是不可能的。
5.Predicate[] 多个过滤条件
List
predicatesList.add(.....Pridicate....)
criteriaQuery.where(predicatesList.toArray(new Predicate[predicatesList.size()]));
OR语句
predicatesList.add(criteriaBuilder.or(criteriaBuilder.equal(root.get(RepairOrder_.localRepairStatus), LocalRepairStatus.repairing),criteriaBuilder.equal(root.get(RepairOrder_.localRepairStatus), LocalRepairStatus.diagnos)));忽略大小写(全大写)
predicatesList.add(criteriaBuilder.like(criteriaBuilder.upper(root.get(RepairShop_.shopName)), StringUtils.upperCase(StringUtils.trim(this.shopName)) + "%"));6.TypedQuery执行查询与获取元模型实例
注意,你使用EntityManager创建查询时,可以在输入中指定一个CriteriaQuery对象,它返回一个TypedQuery,它是JPA 2.0引入javax.persistence.Query接口的一个扩展,TypedQuery接口知道它返回的类型。
所以使用中,先创建查询得到TypedQuery,然后通过typeQuery得到结果.
当EntityManager.createQuery(CriteriaQuery)方法调用时,一个可执行的查询实例会创建,该方法返回指定从 criteria 查询返回的实际类型的TypedQuery 对象。
TypedQuery 接口是javax.persistence.Queryinterface.的子类型。在该片段中, TypedQuery 中指定的类型信息是Employee,调用getResultList时,查询就会得到执行
TypedQuery
List
元模型实例通过调用 EntityManager.getMetamodel 方法获得,EntityType
Metamodel metamodel = em.getMetamodel();EntityType<Employee>
Employee_ = metamodel.entity(Employee.class);
Root<Employee> empRoot = criteriaQuery.from(Employee_);也有可能调用Root.getModel方法获得元模型信息。类型 EntityType
CriteriaQuery criteriaQuery = criteriaBuilder.createQuery();
Root<Dept> dept = criteriaQuery.from(Dept.class);
EntityType<Dept> Dept_ = dept.getModel();
Predicate testCondition = criteriaBuilder.equal(dept.get(Dept_.getSingularAttribute("name", String.class)), "Ecomm");7.Expression 用在查询语句的select,where和having子句中,该接口有 isNull, isNotNull 和 in方法
Expression对象用在查询语句的select,where和having子句中,该接口有 isNull, isNotNull 和 in方法,下面的代码片段展示了Expression.in的用法,employye的年龄检查在20或24的。CriteriaQuery<Employee> criteriaQuery = criteriaBuilder .createQuery(Employee.class);
Root<Employee> employee = criteriaQuery.from(Employee.class);
criteriaQuery.where(employee.get(Employee_.age).in(20, 24));
em.createQuery(criteriaQuery).getResultList();对应的SQL: SELECT * FROM employee WHERE age in (20, 24)
下面也是一个更贴切的例子:
//定义一个Expression
Expression exp = root.get(Employee.id);
//
List strList=new ArrayList<>();
strList.add("20");
strList.add("24");
predicatesList.add(exp.in(strList));
criteriaQuery.where(predicatesList.toArray(new Predicate[predicatesList.size()])); 8.复合谓词
Criteria Query也允许开发者编写复合谓词,通过该查询可以为多条件测试下面的查询检查两个条件。首先,name属性是否以M开头,其次,employee的age属性是否是25。逻辑操作符and执行获得结果记录。criteriaQuery.where(
criteriaBuilder.and(
criteriaBuilder.like(employee.get(Employee_.name), "M%"),
criteriaBuilder.equal(employee.get(Employee_.age), 25)
));
em.createQuery(criteriaQuery).getResultList();连接查询
在SQL中,连接跨多张表以获取查询结果,类似的实体连接通过调用 From.join 执行,连接帮助从一个实体导航到另一个实体以获得查询结果。Root的join方法返回一个 Join
默认情况下,连接操作使用内连接,而外连接可以通过在join方法中指定JoinType参数为LEFT或RIGHT来实现。
CriteriaQuery<Dept> cqDept = criteriaBuilder.createQuery(Dept.class);
Root<Dept> deptRoot = cqDept.from(Dept.class);
Join<Dept, Employee> employeeJoin = deptRoot.join(Dept_.employeeCollection);
cqDept.where(criteriaBuilder.equal(employeeJoin.get(Employee_.deptId).get(Dept_.id), 1));
TypedQuery<Dept> resultDept = em.createQuery(cqDept);抓取连接
当涉及到collection属性时,抓取连接对优化数据访问是非常有帮助的。这是通过预抓取关联对象和减少懒加载开销而达到的。使用 criteria 查询,fetch方法用于指定关联属性
Fetch连接的语义与Join是一样的,因为Fetch操作不返回Path对象,所以它不能将来在查询中引用。
在以下例子中,查询Dept对象时employeeCollection对象被加载,这不会有第二次查询数据库,因为有懒加载。
CriteriaQuery d = cb.createQuery(Dept.class);
Root deptRoot = d.from(Dept.class);
deptRoot.fetch("employeeCollection", JoinType.LEFT);
d.select(deptRoot);
List dList = em.createQuery(d).getResultList(); 对应SQL: SELECT * FROM dept d, employee e WHERE d.id = e.deptId
路径表达式
Root实例,Join实例或者从另一个Path对象的get方法获得的对象使用get方法可以得到Path对象,当查询需要导航到实体的属性时,路径表达式是必要的。Get方法接收的参数是在实体元模型类中指定的属性。
Path对象一般用于Criteria查询对象的select或where方法。例子如下:
CriteriaQuery criteriaQuery = criteriaBuilder.createQuery(String.class);
Root root = criteriaQuery.from(Dept.class);
criteriaQuery.select(root.get(Dept_.name)); 参数化表达式
在JPQL中,查询参数是在运行时通过使用命名参数语法(冒号加变量,如 :age)传入的。在Criteria查询中,查询参数是在运行时创建ParameterExpression对象并为在查询前调用TypeQuery,setParameter方法设置而传入的。下面代码片段展示了类型为Integer的ParameterExpression age,它被设置为24:ParameterExpression age = criteriaBuilder.parameter(Integer.class);
Predicate condition = criteriaBuilder.gt(testEmp.get(Employee_.age), age);
criteriaQuery.where(condition);
TypedQuery testQuery = em.createQuery(criteriaQuery);
List result = testQuery.setParameter(age, 24).getResultList();
Corresponding SQL: SELECT * FROM Employee WHERE age = 24; 排序结果
Criteria查询的结果能调用CriteriaQuery.orderBy方法排序,该方法接收一个Order对象做为参数。通过调用 CriteriaBuilder.asc 或 CriteriaBuilder.Desc,Order对象能被创建。以下代码片段中,Employee实例是基于age的升序排列。CriteriaQuery criteriaQuery = criteriaBuilder .createQuery(Employee.class);
Root employee = criteriaQuery.from(Employee.class);
criteriaQuery.orderBy(criteriaBuilder.asc(employee.get(Employee_.age)));
em.createQuery(criteriaQuery).getResultList(); 分组
CriteriaQuery 实例的groupBy 方法用于基于Expression的结果分组。查询通过设置额外表达式,以后调用having方法。下面代码片段中,查询按照Employee类的name属性分组,且结果以字母N开头:CriteriaQuery
Root<Employee> employee = cq.from(Employee.class);
cq.groupBy(employee.get(Employee_.name));
cq.having(criteriaBuilder.like(employee.get(Employee_.name), "N%"));
cq.select(criteriaBuilder.tuple(employee.get(Employee_.name),criteriaBuilder.count(employee)));
TypedQuery<Tuple> q = em.createQuery(cq);
List<Tuple> result = q.getResultList();查询投影
Criteria查询的结果与在Critiria查询创建中指定的一样。结果也能通过把查询根传入 CriteriaQuery.select中显式指定。Criteria查询也给开发者投影各种结果的能力。使用construct()
使用该方法,查询结果能由非实体类型组成。在下面的代码片段中,为EmployeeDetail类创建了一个Criteria查询对象,而EmployeeDetail类并不是实体类型。CriteriaQuery criteriaQuery = criteriaBuilder.createQuery(EmployeeDetails.class);
Root employee = criteriaQuery.from(Employee.class);
criteriaQuery.select(criteriaBuilder.construct(EmployeeDetails.class, employee.get(Employee_.name), employee.get(Employee_.age)));
em.createQuery(criteriaQuery).getResultList();
Corresponding SQL: SELECT name, age FROM employee"white-space: normal;"> 返回Object[]的查询
Criteria查询也能通过设置值给CriteriaBuilder.array方法返回Object[]的结果。下面的代码片段中,数组大小是2(由String和Integer组成)。CriteriaQuery criteriaQuery = criteriaBuilder.createQuery(Object[].class);
Root employee = criteriaQuery.from(Employee.class);
criteriaQuery.select(criteriaBuilder.array(employee.get(Employee_.name), employee.get(Employee_.age)));
em.createQuery(criteriaQuery).getResultList(); 返回元组(Tuple)的查询
数据库中的一行数据或单个记录通常称为元组。通过调用CriteriaBuilder.createTupleQuery()方法,查询可以用于元组上。CriteriaQuery.multiselect方法传入参数,它必须在查询中返回。CriteriaQuery criteriaQuery = criteriaBuilder.createTupleQuery();
Root employee = criteriaQuery.from(Employee.class);
criteriaQuery.multiselect(employee.get(Employee_.name).alias("name"), employee.get(Employee_.age).alias("age"));
em.createQuery(criteriaQuery).getResultList();