Java初级工程师常见面试题
整理一下自己所经历的高频面试题目。对于一个初级java开发人员的面试,面试时间一般为30~40分钟,有短点的,先写一张笔试卷子,然后面试20分钟,也有长一些的,我最长的一次面试将近2个小时,最后一轮纯技术面,看见面试官在一张纸上记上一个个知识点,问的很细。也有的公司会机试,但很少。像这样很仔细的面试官,会提前在纸上写上各个知识点,挨个问,然后根据你的情况在后面打勾或叉(这一般是稍大一点的公司,一个面试官一早上要面试很多人的那种)。所以要想面试顺利,是需要每点知识都会一些的,而且很多题目都很固定,如果你已经没有时间去梳理各个知识点,刷一下面试题也是可以突击一下的。
说具体的问题,知识点:Java基础,面向对象,IO流,集合,多线程,Servlet,JSP,框架,数据库,都会涉及一点。HTML,CSS,js,jQuery,jdk,服务器,开发工具,这几个较少但也会出现,我在下面都会介绍到。先来个高频的,基本每次都会出现其中一个,经常问的生命周期,运行流程之类(特别注意,很高频!)
- Servlet的运行原理
- JDBC连接数据库的步骤
- Hibernate的运行原理(可从读取hibernate.cfg.xml文件说起)
- Spring中bean的生命周期
- struts2或Spring MVC的工作原理
- 线程的生命周期(从线程创建,进入线程池,等等等到最后死亡。)
参考:
1.Servlet的运行原理,这里分为三个阶段来说
初始化阶段:servlet容器接收到客户端的Http请求后,会创建一个HttpRequest对象和HttpResponse对象并将请求参数封装到request对象中,然后servlert容器由请求url中的地址通过web.xml中servlet的配置查找该请求对应的servlet类,如果该servlet还没有被实例化过,servlet容器就实例化该servlet调用它的init()方法(servlet是单例,这个过程只有一次)。
响应请求阶段:初始化后,servlet容器调用这个servlet的service()方法,并将之前的request对象和response对象作为参数传入来处理请求,并将处理好的结果封装到response对象中返回给客户端。
销毁阶段:当这个servlet的所有service()方法都结束时,servlet容器就会调用它的destroy()方法来销毁这个servlet,释放它所占用的资源。
2.JDBC连接数据库的步骤(这里说一下连接mysql数据库)
a.加载驱动程序。Class.forName("com.mysql.jdbc.Driver")。
b.建立数据库连接。通过DriverManager类的getConnection方法获取连接对象,同时要传入连接路径作参数,路径里包括我的数据库名称“myTest”,用户名,密码还有编码。
c.创建数据库操作对象Statement,用连接对象的createStatement()方法。servlet容器就会调用它的destroy()方法来销毁这个servlet,释放它所占用的资源。
d.调用statement执行sql。
e.关闭资源,关闭连接。
//加载驱动类
Class.forName("com.mysql.jdbc.Driver");
//连接路径
String url="jdbc:mysql://localhost:3306/myTest?user=root&password=root&useUnicod=true&characterEcoding=UTF8";
connection= (Connection) DriverManager.getConnection(url);
//创建数据库操作对象Statement
statement = connection.createStatement();
//调用Statement对象执行对应的sql语句
String sql="select * from a_student";
rs = statement.executeQuery(sql);
//关闭结果对象rs,关闭数据库操作对象,关闭连接3.Hibernate的运行原理
a.创建Configuration对象,读取并解析Hibernate.cfg.xml配置文件,并根据配置中的mapping配置读取并解析实体类相对应的映射
Configuration config = new Configuration().configure();
b.创建SessionFactory对象
SessionFactory sf = config.buildSessionFactory();
c.打开Session
Session session = sf.openSession();
d.创建并启动事务
Transaction tx = session.beginTransaction();
e.持久化操作
f.提交事务
tx.commit();
g.关闭Session,关闭SessionFactory
4.Spring中bean的生命周期(scope=singleton)
a. Spring对bean进行实例化
b. bean的属性注入
c. 若bean实现了一些接口。
spring将调用它们的方法。BeanNameAware接口,调用setBeanName(String beanId),beanId是bean的id。如BeanFactoryAware接口,可以获取Spring容器,获得其它bean。ApplicationContextAware这个接口,和上一个接口功能类似,可以获得其它bean。如果想对bean再进行一些修改,实现BeanPostProcessor接口,它的两个函数postProcessBeforeInitialzation( Object bean, String beanName ) 和 postProcessAfterInitialzation( Object bean, String beanName ) 分别是在InitialzationBean接口之前和之后执行,所以又叫做bean的前置处理和后置处理。前置处理后 InitializingBean这个接口,执行afterPropertiesSet函数。
d.如果这个bean配置了init-method属性,那么调用它所对应配置的初始化方法
e.如c,若实现了postProcessBeforeInitialzation接口,执行它的后置处理
f.以上一个完整可用的singleton的bean生成,直到它不再被需要,待清理的时候,如果它实现了DisposableBean接口, spring将调用它实现的destroy()方法。如果该bean配置了destroy-method元素,则调用该元素所对应配置的方法,这 两种功能其实一样。
5.struts2的工作原理
a.客户端发来一个Http请求
b.通过web.xml配置执行一系列过滤器和核心过滤器StrutsPrepareAndExecuteFilter(struts2版本不同,核心过滤器不同,struts的版本>= 2.1.3都用这个,低于这个版本用FilterDiapatcher)
c.核心过滤器询问ActionMapper来决定这个请求是否需要调用某个Action,若决定调用某个Action,核心过滤器将请求交给ActionProxy
d.ActionProxy通过配置文件获取Action类,然后ActionProxy创建一个Actionvocation实例。
e.ActionInvocation完成请求的拦截和相应的Action中方法的执行,并根据struts.xml中的配置返回结果到相应的jsp页面或Action。
6.线程的生命周期:为了更好的描述线程的生命周期普遍把线程分为几个状态:线程的创建,等待,运行,阻塞和死亡(和官方源码上的状态稍有不同)
创建:new一个Thread类或者它的子类,创建一个新线程
等待就绪:新的线程调用它的start()方法启动线程进入等待队列,但是CPU对线程的调度是随机的,所以此时线程处于等待状态,等待系统对其分配CPU。不能对已经启动的线程再调用start()方法,否则将抛出IllegalThreadStateException。
运行:等待状态的线程获得了CPU的使用权进入运行状态,线程就会执行run方法中的任务,但是此刻的线程稍较复杂,它可以再进入等待队列或变成阻塞状态或死亡。比如该线程失去了CPU的使用权,那么它就会再进入等待队列,等待系统的调度。也可以在运行时调用了sleep()方法,那么它将变为阻塞状态。当线程的run()方法执行完或者被强制的终止,那么线程进入死亡状态。
阻塞:运行中的线程出现下列几种情况是进入阻塞状态,该状态线程停止运行且不能进入等待队列。
a.该线程调用了sleep()方法,该方法执行完后,即睡眠时间到后,线程又可进入等待队列
b.Object对象调用了wait()方法,该方法执行后,只有其它线程中的对象调用了notify/notifyAll方法后,该线程才可进入等待队列
c.线程加入——join()方法,比如将B线程作为参数传入A线程,启动A线程,并调用A线程的join()方法a.join(),则A线程进入阻塞状态,当B线程运行完或一定时间后A再进入可执行状态。(这个实现的原理其实就是b中所述,启动A线程并调用join()方法时相当于在A线程中调用了wait方法,当到达一定时间或着B执行完后会自动调用自身的notify方法唤醒A线程)
死亡:线程的run()方法执行完,线程自然死亡,不能复生。
一.基础
1.Java的几种数据类型?几种基本数据类型分别含有几个字节,不要说错。
参考:java有两种数据类型。基本数据类型和引用数据类型。
- 基本数据类型(8种):
整数型:byte(1字节),short(2),int(4),long(8),
浮点型:float(4),double(8),
字符型:char(2),
布尔型:boolean(1)
- 引用数据类型:类,数组,接口,枚举,注解。
- 延伸:这两种数据类型存储的地方是不一样的,Java把内存分为两种,堆内存和栈内存。基本数据类型的变量存在栈内存里,若变量的值超过了它的作用域,java会释放掉为该变量分配的内存空间,该内存空间可另作他用。引用数据类型的对象存在堆内存里,在栈内存里有一个变量指向堆内存里的这个对象,这个变量就是它的引用,如:User u = new User("张三"); 存在栈中的u就是这个User对象的引用,若要访问这个User对象,只用调用它的引用u即可。当堆中的对象没有引用指向它时,这个对象就会变成垃圾,但仍占着内存,java的垃圾回收器会不定时的清理掉这些垃圾。
2.String很容易被问到
a.String属于什么数据类型?String,Integer间的相互转换?
b.比较一下字符串拼接的方式,append和“+”有什么区别。StringBuffer和StringBuilder是线程安全吗?
c.String str = new String("aaa");解释下这段代码(容易笔试的形式出现)
参考:
a.String是java.lang包中的一个类,所以它是引用数据类型。
其它类型向字符串的转换:
- 调用toString()方法:X.toString();(注意,toString()方法是Object类的一个方法)
- 调用String的String.valueOf(X) 方法。
- 自动转换:X+""; 变量加上空字符串就可以变成String型的变量。
字符串转换成整型:两个方法,
- Integer.parseInt()和Integer.valueOf(),两个都是Integer的静态方法,parseInt()方法返回的数据是int型,valueOf()方法返回的数据是Integer型。当传入的字符串参数不是数字字符串时,两个方法都会报数字格式化异常NumberFormatException。(Long型的转换同Integer型)
b.大量字符串拼接时,StringBuilder的append()方法效率是明显高于String方法的+的拼接的。因为StringBuilder和StringBuffer创建的是字符串变量,而String是字符串常量,一旦创建它的值就不会改变,每次“+”拼接一次就是在创建一个新的字符串对象,速度较慢。StringBuilder非线程安全,StringBuffer是线程安全的。
c.首先,声明str变量,并在常量池里查找是否有“aaa”字符串,若没有则在常量池中创建"aaa"字符串,new String("aaa")在堆内存里开辟一个内存空间,再将常量池中的值赋值给str。
3.问你大学还学过哪些编程课程。有答C语言的话,问你C语音和Java的区别是什么?
参考:C语言是面向过程的,按行执行,而java是面向对象的,按模块执行。C语言的代码不容易跨平台,而java是跨平台的。C语言与硬件的连接最容易,编程时从硬件到软件的各方面都要考虑到。而java适合做Web开发,java里有大量的开源包可以直接用,你只需专注你的功能逻辑开发。
4.冒泡排序,选择排序,二分查找,在纸上要能徒手写出来。
二 . 面向对象,IO流,集合,多线程
1.你理解的面向对象,结合你过去的学习或开发经验讲。(这个也是经常被问到的!结合三大特性,这里最容易被问到的是你怎么理解多态的。这是面试,结合自己开发中的理解去阐述会更有说服力,最好不要单单的生搬概念)
参考:面向对象是一种编程思想,相对于面向过程而言它是通过类来构建各个对象进行交流。面向对象有三大特性:封装,继承和多态。围绕这三个特性,先说封装。属性描述事物的特征,方法叙述事务的可操作性,封装将同一个事物的共性呈现在一个类中并将类的属性隐藏起来,通过方法的访问权限来控制用户对类的修改。比如你建一个Person类,里面的name和id属性通常都是privated的,你可以通过改变它的getter,setter方法的访问修饰符来控制各个用户对它的操作权限。然而像money属性,你可以用proteted修饰,这样Person类的子类Son类在继承Person类后,可以直接拥有它的money属性,但不能直接操作它的name 和id,这样就控制了用户的权限,保证了代码的安全性。同时,封装也提高了代码的复用性,比如Hibernate就是对JDBC的一个封装。封装也是继承的基础,继承是一个对象获得另一个对象的属性和方法的过程,将对象按层级分类。比如我们在开发中通常会有一个Base基类,它包含创建时间,修改时间,创建人,修改人等属性,我们在创建每一个实用的JavaBean时都会去继承这个base类,因为它拥有基本上每个类或表都需要的基本属性或方法。这样通过继承可以避免公用代码的重复开发,减少代码的冗余。有了前面的封装和继承就可以说多态了,多态的前提是继承、重写、父类引用指向子类对象,这个引用在调用方法时先判断父类中有无该方法,若无,程序编译时错误;若有,再判断子类是否重写了这个方法,若重写了就调用子类的,若无,就调用父类的,这也是多态的动态绑定。
2.你怎么理解类继承和接口实现,有什么好处。在开发中两者怎样选择。
参考:实现是继承的一种,继承是类之间的一种关系,实现是对自身方法的扩展。在开发中,如果多个类的某个功能相同,则可以把这部分共同代码抽象出来,比如几乎每个JavaBean都需要的创建时间,创建人,修改时间,修改人,这些就可以抽取到一个Util中,其它的类都来继承这个Util类就可以了,这是继承的应用。但是若是多个类的实现的目标一样,但是实现的方式各不相同,这时就用多态。比如ArrayList和LinkedList,前者是便于查询的数组结构,后者是便于增删的链表结构。它们都可以用来存储数据,只是实现的方式稍有差别,所以它们都是实现了List接口。
3.说一下抽象类和接口。
参考:
抽象类:
- 抽象类不能实例化,只能通过子类继承后向上转型实例化
- 子类继承抽象类后必须重写父类里的所有抽象方法,不然除非将子类也声明成抽象类
- 抽象类里可以有非抽象方法,必须用public或protected修饰,因为private的话子类是继承不了的,成员变量也不能是private
接口:接口里面是只有抽象方法和全局常量
- 和抽象类一样不能实例化,只能通过子类继承后向上转型实例化
- 和抽象类一样,子类必须重写所有抽象方法,除非子类也为抽象类
- 接口的方法隐式的指定为public abstract方法,且只能是,接口里的变量被隐式的指定为public static final变量(jdk1.8以前如此,且所有的方法不能有实现,从1.8开始接口可以有default或static修饰的实现方法)
设计层面上的区别同上面第2题的类似,抽象类是对事物的抽象即对类抽象,包括属性、行为,是一个模板设计;而接口是对行为的抽象即方法的抽象,是一种行为规范约束。
4.弄清楚类的初始化顺序,特别是有静态代码块,构造块时。还有子类继承父类后一些方法调用的优先级。(经常选择题)
参考:如果一个类中包含类属性和实例属性,类方法和实例方法,类的初始化块和实例初始化块,构造器。这里经常选择题,比如B继承A,在测试类的主函数里new一个对象b:B b = new B(),程序启动时加载的顺序是什么?应该是:A的静态代码块——B的静态代码块——A的非静态代码块——A的构造函数——B的非静态代码块——B的构造函数。原则就是:先父类,再子类;先加载类的,再加载实例的。
另一个,在A a = new B()时也有先后关系别混淆了,子类向上转型,若子类B重写了父类A的方法或者在B中定义了与A中一样的属性,那么a在调用时都是调用子类B中的属性和方法,这也是多态的体现。
5.Java中怎样比较两个对象是否相等?有哪些方法防止存在两个相等的对象
参考:通常用“==”和equals方法来比较。
- 先说“==”,对于基本数据类它就是比较两个值是否相等随即返回相应的boolean值。对于引用数据类型,它就是比较两个对象的引用是否指向同一个地址,是就返回true,否返回false。但对于包装类,就要慎用==,因为Interger的值在初始化时,会有下面一段代码
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}//IntegerCache.low就是-127,IntegerCache.high就是128也就是说,当i的值在-127~128之间时,会自动调用一个和i值相等的cache对象,当i值不在这个范围内时,就重新new一个Integer对象,而“==”是比较对象的地址。由此可知:
//a和b的值都在-127~128之间,初始化时返回同一个cache对象
Integer a=11;
Integer b=11;
System.out.println(a==b);//true
//Integer值不在-127~128范围内,初始化时返回两个不同的Integer对象
Integer A=222;
Integer B=222;
System.out.println(A==B);//false同样,Long型数值比较大小也要慎用==,在Long值初始化时,valueOf(long l)是这样的:
public static Long valueOf(long l) {
final int offset = 128;
if (l >= -128 && l <= 127) { // will cache
return LongCache.cache[(int)l + offset];
}
return new Long(l);
}Long型数值在比较大小时,-128~127范围内可以正常比较,超出这个范围就不行了。所以包装类最好不用“==”来比较大小,可以这样: 有Integer型的数据A和B要比较大小,可以先A.valueOf()方法返回A的同数值int型a,这时再将a,b用“==”比较大小。
- 再说equals方法比较。equals方法是Object类的一个方法,所以引用数据类型都可以调用它,基本数据类型不行。由于“==”在比较对象时只能比较两个对象的引用地址是否一致,即判断两个变量是否是同一个对象,这样并不能满足实际开发中的需要。那equals方法是怎么比较的呢?看Object类的源码:
public boolean equals(Object obj) {
return (this == obj);
}这里的this即为调用该方法的对象,如A.equals(B),返回的结果就是用“==”比较A和B,这不是和上面直接用“==”比较一样吗?这还是不能满足实际开发的需要啊,比如在学校里面的一个课程Course类,它有下面4个属性
class Course{
//课程id
private int id;
//课程名称
private String courseName;
//班级id
private int classId;
//教师id
private int teacherId;
}如果我们现在新建了两门课程CourseA和CourseB,除了id不同,其它属性全相同。即是某一个班级的某一门课程被同一个老师开了两次,这显然是不符合现实逻辑的。但是用“==”和equals方法来判断这两个类的对象的实例的时候,返回的都是false,两门课程不一样,因为对象实例的引用不一致,所以问题就来了,怎么解决呢?为了避免这种情况在java的大部分类里面都其实有重写eqals方法的。比如Integer,Long,Boolean等包装类,看Integer类的源码:
public boolean equals(Object obj) {
if (obj instanceof Integer) {
return value == ((Integer)obj).intValue();
}
return false;
}上述这段代码:1.是先判断所传入的obj对象是否是Integer类型,2.如果是,再将这个对象转为它的int型数值。"value"指调用equals方法的Integer对象的int型数值,然后将这两个值进行比较。同理,Long、Boolean的equals方法的重写都是一样的。
再看一个比较常见的String类型,它的equals方法的重写的源码如下,我加了些注释:
public boolean equals(Object anObject) {
//1.先比较两个对象的引用是否相同,引用相同肯定就返回true
if (this == anObject) {
return true;
}
//2.不同。判断这个对象是否是String类型的对象
if (anObject instanceof String) {
String anotherString = (String)anObject;
//value:调用这个equals方法的String的char型数组
int n = value.length;
//3.对两个数组的长度和每一个字符遍历比较,返回判断结果
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}看这段源码,注释已经很清楚了,它就是在判断两个字符串是否相等时真正的去比较它们的每一个字符,而不是像Object方法里简单粗暴的只判断两个对象的引用,这样更符合实际需要。所以一般的类里面都会重写equals方法,除非是你自己建的类,你可以根据需要去重写equals方法。
综上,可以简化为简单的一段话:在java中判断对象是否相等,基本数据类型用“==”即可,包装类数值可以先把它转换成基本数据类型。引用数据类型用equals方法最好,String字符串在用equals比较时比较的是字符串本身所包含的字符是否相等。如果是你自己创建的类你可以根据需要去重写它的equals方法。如果面试官问你为什么要这样,那么上述代码就可以用来解释了。
6.说一下你学过的IO流的知识。序列化是什么,你怎么理解的?
参考:IO流有字节流和字符流,用来操作文件的输入和输出。同字面意思,字节流的读写是以字节为单位,字符流的读写以字符为单位(1字节就是1byte)。然而在读取文件时为了提高效率还有缓冲流,BufferedInputStream和BufferedOutputStream是处理字节的,BufferedReader和BufferedWriter是处理字符的。序列化的理解:序列化是把java对象转换成二进制字节码,反序列化是把二进制字节码还原成java对象。之所以要这样,是因为1.为了方便网络传输。2.能被持久化的写到磁盘里。要说明一点,类若实现序列化,注意添加一个serialVersionUID。因为你如果不指定一个,系统就会根据类名方法名变量名等自动生成一个serialVersionUID,当你的类里的内容发生变化时,就又会自动生成一个不同的serialVersionUID,此刻就会报InvalidClassException。然而在有些时候我们并不想序列化整个类,比如银行账号和密码这样的字段,不希望被持久化的存储在磁盘中,这时可以用transient 关键字来修饰需要序列化的变量即可。
7.当你读取一个文件时,若该文件不存在,会出现什么情况?怎样避免这种情况?
参考:文件为空时读取报错抛出FileNotFoundException。为避免这种情况读文件前先判断这个文件存不存在。file.exists()方法判断,若不存在,就file.createNewFile()创建这个同名文件即可防止报错。
8.你知道的Java中的集合接口有哪些?它们是什么结构?它们有哪些公有方法?
参考:Collection接口和Map接口。Collection接口的常见子接口有List(有序的可重复),Set(不可重复)。List常见子接口有ArrayList(数组结构,相对查找快,因为LinkedList查找时要移动指针)和LinkedList(链表结构,相对增删快,因为ArrayList增删时要移动数据)。ArrayList和Array数组一样,都是动态数组结构,随着向里面不断添加或删除元素,数组的长度也会随之增大或减小,然而此实现并不是同步的。如果多个线程同时访问一个ArrayList实例,其中一个线程对实例的结构进行了改变(结构改变是指改变数组的长度,仅改变数组上的某个值不算),必须保持外部同步。在遍历集合时改变它的长度也会出现异常,这个待会根据源码详细讲。多个线程时LinkedList结构的改变也不是同步的。所以在创建时可以用 Collections.synchronizedList 方法将集合对象包装起来保证同步: List list = Collections.synchronizedList(new ArrayList(...))。同样,HashSet或TreeSet在被多个线程同时访问时也可以这样创建。

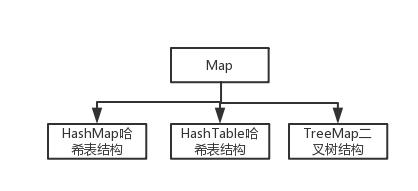
再来看Map
9.围绕Set,Map,List展开的问题。
- A.线程安全的是哪个
- B.ArrayList和LinkedList哪个增删快,哪个查询快,为什么会这样?
- C.HashMap的结构是重点!!!HashMap里当存一个重复的值时,会怎样,原来的值会怎样?
参考:
A. HashTable是线程安全的。然而在只有一个线程访问的情况下,HashMap的效率要高于HashTable。
B.参照第8题已说。
C. 重点说HashMap的结构,HashMap是基于哈希表的Map接口的实现,是数组和链表结构的结合。如下图所示,HashMap的主干是一个Entry数组,一个Entry单元里包含键key,值value,hash值,next下一个元素。纵向绿色的是每个Entry单元的链表结构,一个Entry桶,之所以是这样一个结构是因为比如需要在HashMap中插入一个元素,先计算元素的key的hash值,由hash值得到这个元素在数组中的位置(即数组下标),若这个位置上没有值,则将元素直接插入,然而当这个位置上已经有值时(即哈希冲突),就比较两个元素的key值,若返回true,则新元素的value覆盖旧元素,若返回false,则将新元素插入链表头,将以前的老元素放在链表的尾上,这样就是一个Entry的链表结构。同样,HashMap在取一个Entry时,会根据hash算法得到它的哈希值找到它在数组上的位置索引,再根据equals方法从Entry链表里找到这个Entry。然而HashMap不是线程同步的,可以这样 Map m = Collections.synchronizedMap(new HashMap(...));防止非同步访问。

10.实现多线程的几种方式,和用多线程的好处?
参考:继承Thread类,实现Runnable接口,实现Callable接口并与Future、线程池结合使用。注要说前两种,实现Runnable接口类比继承Thread类要更优一些,一是避免了java单实现的局限性,二是相比继承Thread能够实现类资源的共享,对这里不明白的可以做个买票的小demo对比就知道了。用多线程的好处:多个线程并发执行可以提高程序的效率(这里要明确多线程和多进程的区别,多进程是操作系统能同时运行多个任务,而多线程是让CPU不会因为某个线程需要等待资源而进入空闲状态),比如同时下载多个文件。
11.多个方法操作同一个数据时,怎样保证同步?说说你的几种方法
参考:使用synchronized同步代码块,修饰方法,或修饰需要被多线程操作的全局变量。
12.你理解的同步和异步
参考:多线程里的同步和异步,比如一个全局变量X,A线程需要请求变量X,但X正在被B线程操作,由于同步机制,A线程只能等待。异步情况下,A线程需要请求这个变量X,X正在被B线程操作,A线程也请求的到。所以异步操作全局变量很不安全。
13.sleep()方法和wait()方法的区别
参考:这两个方法都是让当前线程暂停进入阻塞状态,但不同的是:
- sleep()方法是Thread类的方法,wait()是Object类的方法。
- sleep()睡眠时,仍占用该对象锁,wait()睡眠时,释放对象锁。
- sleep()执行完后若有比这个线程优先级更高的线程,那么它由阻塞进入就绪状态。但是wait()执行后需要其它线程执行notify/notifyAll方法才能重新获得CPU的使用权。
14.sleep()方法和yeild()方法的区别
参考:这两个方法都是Thread类的静态方法,都可以改变当前运行的线程的状态,并且在当前线程停滞时都不会释放对象锁,区别:
- sleep是让线程在一定时间内进入阻塞状态,而yeild是直接让线程进入就绪等待队列。
- sleep方法让出使用权时指定的线程是不论其优先级的,而yeild只允许和当前线程同等优先级或更高优先级的线程获取CPU的使用权。。
三 . JSP,Servlet,数据库,HTML,CSS,jdk,框架等
1.JSP的几个内置对象,和它们代表的意义。还有四个域对象。
参考:
四大作用域:page:当前页面的有效时间;request:请求开始到结束;session:会话开始到结束;application:服务器启动到停止。
9个内置对象分别是:request,response,pageContent,session,application,page,config,out,exception。说重点的几个。request,response的获取方式:在Servlet里可以在doGet()或doPost()方法的形参直接获取。
doGet(HttpServletRequest request, HttpServletResponse response){...}在struts里ServletActionContext.getRequest();方法获取。
HttpServletRequest request = ServletActionContext.getRequest();在SpringMVC里,直接在控制层方法的形参里获取或者用Spring的@Autowird注解。
public String hello(HttpServletRequest request,HttpServletResponse response) {...}
或者用Spring的注解
@Autowird
private HttpServletRequest request;request代表了客户端的请求信息,作用域为request,response代表对客户端的响应,作用域为page。重点说一下session,session的作用域为请求开始到结束,即为用户打开浏览器到关闭浏览器的这个时间。它是服务端自动创建用来记录和跟踪用户信息的,所以它存在服务器端。与此相对记录用户信息的还有cookie,它是保存在本地浏览器端的,session的session_id保存在本地浏览器的cookie里,当用户离开后再次访问时,浏览器端通过cookie里的session_id访问服务器端,就可以再次得到用户的信息。
2.怎么从JSP页面到Servlrt,怎么从Servlrt到JSP页面。需要配置什么(Servlet配置的基础问题)
参考:这是考Servlet的基础配置,延伸的都说一下。Servlet里的页面间跳转的配置都写在web.xml里。先配置要访问的Servlet,再配置其映射如下,若有多个Servlet需要配置,如此即可
pageServlet
page.PageResultServlet
pageServlet
/pageServlet
还有一个标签
时,用这个标签配置后,直接访问项目名http://localhost:8080/servlet即可到登录页面。
login.jsp
3.页面间传值的几种方式
参考:
- get提交:*.jsp?a=xx & b=xx,直接放在访问路径的后面。只能传输字符串,这种方式传输数据小,且数据的值会出现在浏览器的访问路径里,不安全。
- form表单,指定post提交。
- jsp的内置对象request,<%request.setAttribute(name,"Ann");%>,想在next.jsp获取时<%String getName=request.getParameter("name"); %>
4.JSP中常用的标签有哪些(标签有很多,也有各种分类,你能说出来常用的一些就可以)
参考:JSTL是JSP的标准标签库。先说下JSTL的核心标签,在用核心标签前要先在jsp的头里引入<%@ taglib prefix="c"
uri="http://java.sun.com/jsp/jstl/core" %>。常用的有out标签,输出。迭代遍历的forEach标签
条件判断的choose、when、otherwise标签
及格了
良好
优秀
没及格
条件判断的还有if标签
那你很厉害噢!
设值到scope里的set标签,scope代表了jsp的作用四个域。设值后,在下一行的out标签里即可马上打印出name的值
还有格式化标签,在头里引入<%@ taglib prefix="fmt" uri="http://java.sun.com/jsp/jstl/fmt" %>,用来格式化并输出文本、日期、时间、数字。常用的有日期的格式化
输出结果为下面:

还有SQL标签,XML标签,JSTL函数标签,记住几种常用的即可,在面试的时候能回答的出来,证明你用过。
5.你用过哪些数据库?Oracle和MySql的区别是什么?
参考:
- oracle是大型数据库,支持大并发大访问量,mysql是小型数据库。
- mysql里有主键自增,oracle里没有,要自己添加序列,插入时把序列的值加进去
- mysql里分页用limit很简单,oracle里用rowNum
- mysql里字符串用单引双引都行,oracle里通常用单引,双引号会报错
6.Mysql里怎样分页
参考:MySql里分页比较简单,就是用limit。“limit a,b”指从第a+1行开始的共b条数据(索引a从0开始)如下:
select * from a_student LIMIT 0,5; #返回第1到5行的数据
select * from a_student LIMIT 3,5; #返回从第4行开始的5条数据
select * from a_student LIMIT 5; #返回前5行数据 7.Mysql里怎么处理日期的格式,怎么比较日期大小
参考:常用的处理日期格式的有:DATE_FORMAT函数,将字符串“20180318”转换后得到:2018-03-18 00-00-00
DATE_FORMAT("20180318","%Y-%m-%d %H-%i-%s")还有时间戳的转换FROM_UNIXTIME,先解释下时间戳。从1970-01-01 00:00:00到时间t所经历的秒数为时间t的时间戳(因为北京在东八区,所以我们在使用的时候默认是从1970-01-01 08:00:00开始计算的),假如设置时间戳为1秒
select FROM_UNIXTIME(1,"%Y-%m-%d %H-%i-%s") as date;查询结果为:1970-01-01 08-00-01,1970年1月1日的早上8点零1秒
![]()
还有一个就是计算时间差常用到的TO_DAYS函数,它是计算从0年开始到时间t所经历的天数,比如公元1年1月1日
SELECT TO_DAYS("1-1-1") as s;输出结果为366天。所以这个函数经常用来计算两个日期间的相差天数。
![]()
8.内连接外连接的区别。left join,right join,inner join 的区别
参考:这个很简单,不要答错。left join是left outer join的简写。还有mysql里不支持outer join。现有a表和b表
inner join:a inner join b,筛选出两个表中都符合条件的记录
left join:a left join b,表a左连接表b,表a为主表,查出a表所有记录,匹配b表符合条件的,不能匹配的用null代替
right join:a right join b,表a右连接表b,表b为主表,查出b表所有记录,匹配a表符合条件的,不能匹配的用null代替(与left join 相反)
因为mysql里没有 full outer join ,就是left join 和right join的和,这里可以用union把两个结果相连即可。
9.子查询和连接查询的区别在哪里?为什么会这样?
参考:子查询不一定要两个表有关联字段,但连接查询一定需要。子查询适合作为查询的筛选条件,而连接查询更适用查看多表的关联的情况。因为子查询查的时候走的是笛卡尔积,需要创建和销毁临时表,所以子查询的效率要低于连接查询。预留。。待考证。。。。。。
10.数据库事务的四个特性,它们分别代表什么意思。(很高频!)
参考:先说下事务,是指单个逻辑单元执行的最基本操作,事务从开始到结束后只有两种结果:1.所有步骤操作成功,事务提交。2.某处不成功,事务回滚,撤销从事务开始的所有操作。这就体现了事务的原则性,所有操作要么全部执行,要么全部不执行。
- 原子性:指事物的操作要么全部执行,完全应用到数据库。要么失败回滚,对数据库不无任何影响。
- 一致性:是指事务的执行必须使数据库从一个一致性保持到另一个一致性的状态。比如用户A向用户B转账200,此时系统发生故障,事务还没完成就被迫中止,然而事务对数据库做的一些修改已写入数据库,那么此时数据库就不是一个一致性的状态。所以,当数据库中只包含成功事务提交时,就说数据库处于一致性的状态。
- 隔离性:每个事务之间互相独立,互不影响。
- 持久性:事务一旦成功提交,对数据库做的操作都是永久性的。接下来出现故障操作都不会对之前的操作有所影响。
11.说一下怎么提高数据库的查询效率
参考:提高数据库查询效率可以从多方面着手,数据库的设计,sql语句的构造,java代码的构造,数据库I/O方面,这些太多了,根据自己的实际经验重要的说几点就行(这里是针对mysql数据库);
- 可以设计成数字型的字段不用字符型。因为在查询和连接时会对每个字符逐个进行比较,而对于数字型字段只用比较一次就够了。
- 选择合适的数据类型,尽量定长。字符串型字段用varchar还是char,varchar长度可变,char长度固定。varchar是字符串有多长长度就为多少,比如同样定义长度为10,存入“aaa”到库中,varchar存的字符串就为“aaa”长度为3,而char存入的aaa后面就有7个空格填充,长度为10。所以varchar比char节约空间,但因为varchar的长度是不固定的,所以varchar的执行效率比char低,在实际用时灵活选择。
- 适当反三范式。适当增加冗余字段,减少多表去关联查询。比如Course表除了添加教师id还可添加teacherName,查询课程时减少关联。
- 建立合适的索引,查询较频繁的字段。
在sql语句构造方面:
- 关联查询和子查询要注意效率。
- 尽量用关联查询代替子查询。执行子查询时需要创建临时表,查询完后再删掉这些临时表,所以效率会有影响。然后在子查询时in和exists合理的选择。简单说下原理,in是先查子查询生成一个临时表,然后将外面的主表和这个临时表做一个笛卡尔积,再进行筛选得到需要的数据。而exists是循环遍历外面主表的结果集,将结果和子查询进行比较筛选,就像两层for循环一样。所以,主表小子表大时用in合适,主表小子表大时用exists合适。原理上是in把主表和子表做hash连接,exists是对主表做loop循环,这个关于数据库的原理在这不做过多赘述。
- 限制返回条数,mysql的limit
- 少用select * ,选择需要的字段返回。
- 在sql语句中有数据计算时,用where不用having。因为having是计算完再执行having后面的筛选条件,where是先筛选再计算数据,可以减少不必要的计算。
- 在where后面,经量避免对索引列进行计算或!=,<>的判断。因为索引只能查出哪些存在于表中,而不能判断什么不存在于表中,用于上述判断的话mysql将不再是对索引列进行扫描,而是全表扫描。
- 注意SQL的逻辑顺序,尽量减少查询条数。比如需要对A表进行Group by分组时,若有筛选条件,应先将A表进行筛选再将剩下的数据进行分组,减少不必要的消耗。
12.说一下CSS的基本选择器,它们的优先级是怎样?
参考:id选择器,class选择器,元素选择器,优先级如前所述,由高到低。注意一下,两个class属性直接相连匹配的是既有class1又有class2的元素。两个class属性用空格相连匹配的是在class1属性元素下的拥有class2属性的元素。
.class1.class2{}
.class1 .class2{}
13.jQuery里怎么设置或得到一个元素的属性
参考:attr()函数。
对象.attr("属性名") //获取属性的值
对象.attr("属性名","属性值") //设置属性的值14.你用的是哪个版本的jdk,jdk1.7在jdk1.6上有哪些改变,jdk1.8呢
参考:先谈1.8相对1.7,毕竟比较新的。特性很多,先贴个链接:官网:What's New in JDK 8
- 接口的默认方法。接口里可以有实现的方法,用default修饰。
- HashMap的结构。HashMap是链表散列结构,jdk1.8以前当hash值相同时,同一个key上会以单链表的形式存储各个同hash值的不同元素,但在jdk1.8中当链表节点数大于8时,是以红黑树的结构来存储这些元素的。
- 添加Optional类,使代码中的非NULL判断更优雅简洁(具体的实现内容我贴个链接大家自己看https://blog.csdn.net/canot/article/details/52956230)
15.说一下java程序编译和执行的过程
参考:先编译,源文件被编译器编译成字节码.class文件。编译器在编译一个类时会优先编译这个类所依赖的类,如果找不到被依赖的类的.class或.java文件,编译器就会报就会报“cant find symbo”错误。编译后的字节码文件格式分为常量池和方法字节码。常量池是各种类名方法名引用等,方法字节码就是各方法就是类里方法的字节码。
再执行。JVM将编译好的.class文件加载到内存,然后针对被加载到内存的java类进行解释执行,返回结果。(注:JVM只在程序第一次主动使用类时才会去加载它,且只加载一次。)
16.用户在浏览器上打开一个页面,这中间经历了哪些过程,用你知道的知识解释。
参考:这里适度将涉及java的部分详讲,其它部分略讲。用servlet来举例,当你访问一个网页即在地址栏输入一个url,浏览器将请求数据打包,并将数据包发送给服务端容器,容器接收并解析数据包并将数据包中的参数封装到创建的request对象中,同时创建一个response对象。在web.xml中找到url访问路径所对应的servlet类,检查这个Servlet的实例对象是否已创建,若没有就调用构造函数创建一个实例并调用它的init()方法(servlet是单例,这个过程只执行一次)。并将request和response对象作为参数传给service()方法来处理请求(用来处理请求的方法,它是多线程且并不安全,不要用来操作全局变量),service()方法将会从request对象中获得客户端的请求参数,并将处理后的结果用response封装返回到客户端。服务器这边,当不需要这个servlet对象需要结束其生命周期时,servlet容器调用它的destroy()方法来销毁这个servlet对象,释放对象所占用的资源。这里延伸一点,为了缩短用户初次访问时的等待时间,可以将servlet的创建设置成在容器启动时,"
17.在你的编程经历中,你常遇到的异常有哪些?你用过哪些包?(异常说几个实际中常用的即可,常见包即它们中常用的类说一下,这要平时稍稍看一下API)
参考:
常见的NullPointerException(空指针异常),ClassNotFoundException(类没有找到异常),ArrayIndexOutOfBoundsException(数组角标越界),ClassCastException(强制类型转换异常),NumberFormatException(数字格式异常),StackOverflowError(栈溢出错误),SQLException(操作数据库异常)。慢慢开始做项目了,还会经常出现下面一些:struts2时常遇见的,“There is no Action mapped for namespace / and action name ***Action”跳转时映射路径错误。Hibernate里常见的:“MappingException: Unknown entity”数据库和类的映射异常(没在hibernate.cfg.xml里配置mapping)。
常用的包,java.util包,API对它的解释是“包含 collection 框架、遗留的 collection 类、事件模型、日期和时间设施、国际化和各种实用工具类(字符串标记生成器、随机数生成器和位数组)”里面集合的接口Collection
提供许多基础类的java.lang包,里面出除了提供像Boolean,Integer等封装类,还有Iterable
通过数据流、序列化、和文件系统输入和输出的java.io包,有启用类序列化功能的Serializable接口,刷新数据的Flushable 接口,关闭数据源的Closeable 接口
还有就是用数据库时用到的java.sql包,与数据库连接会话的Connection接口,驱动程序必须实现的Driver接口,查询数据后得到的结果集ResultSet接口,用于执行静态SQL语句的Statement,表示预编译的PreparedStatement
18.最后建议:基本上每次Spring是必问的,Spring是重点重点。近些年流行的微服务框架SpringBoot也应该看看,内容太多,这里就先不写了。还有喜欢把Hibernate和Mybatis作比较,项目中该如何选择以及它们的优缺点。还有sql语句一定要熟练,若没有笔试,面试官口问也不会有太难的sql题,但要是有笔试一般都会要你手写sql的,这一点直接去参考“学生—课程—教师—成绩”关系的sql题目或者“员工—经理—薪资”这一类的,出现的频率很高。推荐学生关系的,在网上可以搜到很多,按照要求在自己的电脑上建几张表,把每个问题都手敲几遍。这里说一下,关于框架,一般会根据你的简历上写的来问,比如struts2现在用的已经很少很少了,但你的简历上有写会加分,面试官很可能会问。但是,除了我所提到的关于框架的高频面试题外,框架可以问的知识确实是有点多,或者说可以追根究底的问的比较深,所以我的建议是在突击的情况下先掌握这些高频的,并能自己做一个框架的项目,深入一些的话可以先把比较高频的出现的地方看一下网上的博客,最后再看几本框架的源码书,再慢慢研究源码,逐步深入。
之前觉得排版麻烦,这篇博客写了后一直没发布,今天是今年的最后一个工作日了(马上回去过年![]() ),得要把这未完的博客了结了
),得要把这未完的博客了结了![]() 。纯手写,也是对自己零碎知识的整理。当然,这些都是比较基础的问题了,适用于需要找实习的同学,春招将至,祝君好运噢!!!
。纯手写,也是对自己零碎知识的整理。当然,这些都是比较基础的问题了,适用于需要找实习的同学,春招将至,祝君好运噢!!!