基于Flink的K-Means聚类算法的实现(Scala版)
基于Flink的K-Means聚类算法的实现(Scala版)
聚类分析是机器学习中最最入门级的算法,属于无监督学习类算法。在传统IT技术手段下,算法只能在单个计算节点运行,由于受运行时间的约束,只能采用对源数据抽样方式来分析,计算结果的准确度会受抽样方法、样本大小的干扰。为此需要让聚类算法具备非受限横向扩展能力,以满足对海量数据的分析需求。
基于Flink的流式计算框架,可以自动将算法依赖的数据、以及算子分布至各个TASK节点中去,使算法不再受主机节点本身的算力约束。由于网上基于Flink+Scala版的K-Means实现说明资料很少,笔者简要记录了一下使用Scala语言在Flink框架下开发K-Means聚类算法的步骤过程、关键代码、以及在Hadoop Yarn上部署、运行的方式。
一、算法说明
K-Means聚类算法思路很朴实也很简单,其将待分析的目标群体的N个特征属性量化后,投射到N维坐标系中,然后在这个坐标系中,根据各标的物间的距离大小就能划分出群组。只要能合理对特征属性进行量化,并找到合适距离算法,对于简单分析的场景下都能得到较好的结果。(本文中的代码,只是对数据值属性对象计算距离,没有考虑二元变量、分类变量等,同时距离算法也只是用的欧氏距离法算进行计算)
从工程实现角度看K-means也比较简单,计算出目标群体中各个标的物与质心(中心节点)之间的距离,形成一个更小的群组,然后计算出这个新群组新的质心坐标,并将其放入下一次跌中继续计算,直到质心的坐标不再发改变。(首次迭代计算时质心的坐标可人工指定或随机指定,同时未避免迭代次数过多,将限定迭代次数)
二、关键代码
1、K-Means计算主程序
def main(args: Array[String]): Unit ={
print("Running K-Means Study01 ")
if(args.length > 0){
EnvType = args(0)
}else{
EnvType = "YARN"
}
print("at " + EnvType)
val env = ExecutionEnvironment.getExecutionEnvironment
println(",JOB-ID: " + env.getIdString)
val points: DataSet[Point] = this.getPointDataSet(env) ///待分类的数据
val center: DataSet[CenterPoint] = this.getCenterPointDataSet(env) ///初始选择中心节点
val newCenter: DataSet[CenterPoint] = center.iterateWithTermination(10){//迭代计算新节点
allCenter =>{
val result = points.rebalance()
.map(new KmeansSelectCenterMap(null)).withBroadcastSet(allCenter,"centerLst")
.map(t=>{(t._1, t._2, 1L)}) ///计数初始值1
.groupBy(0)
.reduce((t1,t2)=> { (t2._1, t1._2.add(t2._2), t1._3 + t2._3) }) ///累加计数
.map(t=>{ ///计算新的中心节点
val c: CenterPoint = new CenterPoint
c.setId(t._1)
c.add(t._2)
c.div(t._3)
c
})
val termination: DataSet[(CenterPoint,CenterPoint)] = allCenter.join(result)
.where(_.getId).equalTo(_.getId)
.filter(t=>{t._1.notEquals(t._2)}) //如果一中心节点没有变化,则退出迭代计算
(result,termination)
}
}
var result = points.rebalance()
.map(new KmeansSelectCenterMap("F")).withBroadcastSet(newCenter, "centerLst")
.map(t=>{(t._1, t._2, 1L)})
.groupBy(0)
.reduce((t1,t2)=> { (t2._1, t2._2, t1._3 + t2._3) }) ///累加计数
if(EnvType.equals("YARN")){
result.writeAsText("hdfs://cloud01:7000/appdata/tmp/result").setParallelism(1)
}else if(EnvType.equals("IDE")){
result.writeAsText("f:/scala/result").setParallelism(1)
}
代码说明:
- 第2~10行, 程序入参处理,用于标识出是本地开发IDE中运行,还是在YARN上运行
- 第12~13行, 为从读取csv格式的待分类数据,以及初始选择的中心节点数据
- 第15行, 开始迭代计算新的质心,这里设定的最大迭代次数为10次
- 第17行, 对目标数据在计算节点间均衡处理
- 第18行, 调用自定义Map算子KmeansSelectCenterMap计算各个点离质心的距离,并标识出各个节点归属于哪一个质心
- 第20~21行, 根据质心对数据进行分组,并进行累加计数
- 第22~28行, 自定义Map算子根据之前的累加结果,计算出新的质心节点
- 第29~31行, 根据新计算出的质心集合与已有质心,判断计算结果是否有变化,并以此作为当前迭代的终止条件
- 第36~40行, 根据迭代计算出的最终的质心集合,计算最后的数据聚合划分结果
2、KmeansSelectCenterMap算子
class KmeansSelectCenterMap(typ: String) extends RichMapFunction[Point,(Int, Point)]{
var centerLst: java.util.List[CenterPoint] = _
override def open(parameters: Configuration): Unit = {
this.centerLst = getRuntimeContext.getBroadcastVariable[CenterPoint]("centerLst")
}
override def map(p: Point): (Int, Point) = {
var minDistance: Double = Double.MaxValue
var itr = this.centerLst.iterator
var centerId: Int = -1
var newCenter: CenterPoint = null
while (itr.hasNext){
var center: CenterPoint = itr.next
var distance: Double = p.distance(center)
if(distance < minDistance){ //找最近
minDistance = distance
centerId = center.getId
newCenter = center
}
}
if(typ == null) {
(centerId,p)//返回数据节点
} else {
(centerId,newCenter)//返回质心节点
}
}
}
代码说明:
本段代码中的逻辑很简单,基于RichMapFunction抽象算子,从Flink广播变量中获取之间已计算质心集合,并以此为入参计算当前节点离哪个质心最近。其中Point对象中的distance方法负责节点间的距离计算,具体可以选择Euclidean 、Minkowski 、Manhattan 等距离算法,对于不合适精准度量的场景,这里也可以选择相似度算法。
三、部署运行
Flink的基于YARN运行,运行环境部署在云上的两个节点上(一台1C4G、另一台1C2G,笔者预算有限只在云上租了两台),上述K-Means计算程序的一次执行时将同时跑在这两个节点之上,如果有需要则可以十分容易的增加节点以提升整体算力。
1、部署
两个节点的部署拓扑结构如下图所示:

从上图中可知,Flink以Session模式寄宿在Yarn的TASK节点运行,程序打包后通过cloud02节点提交给Yarn,由Yarn负责分配给这两台主机上Flink Task节点中去运行,计算所需的数据存储在Hdfs上,运行的结果也将存储在Hdfs上。
2、运行
运行算法程序包只需在上传jar至主机节点上,并将待计算的数据上传至Hdfs对应目录中中,再通过flink run命令提交运行即可。上述算法在flink运行时的executionPlan如下图所示:

从上图可知,短短30多行代码已经被Flink自动拆分、重组成了14个子任务,理论上每个子任务均可以分布在不同Task节点上运行,同时自身也可以通过指定数据中的分区键进行分区,让待分析的数据自动分配至不同Task节点中(需要手工调用Flink自身的分区方法才能生效)。
3、计算结果
在Flink缺省Job并行度设定为2时,当100w笔数据时(大小约8m),从数据加载至计算完毕,大约20秒左右时间运行完毕。Timeline图如下所示:

从上图可知从计划运行到开始运行,消耗了7秒左右的时间,剩下的16秒为实际运行时间,且为多个子任务并行执行。查看hdfs上存储的计算结果:

结果中显示通过K-Means计算后划分出了7个群组,其中每行代表每个群的质心ID,质心坐标,以及包含节点个数。由于100w笔数据是在[0,1000]中随机生成,所以结果中每个群中的节点个数差异不大。
当数据为1000w笔时(大小约80m),从数据加载到执行完毕耗时1分16秒,Timeline图与计算结果如下所示:

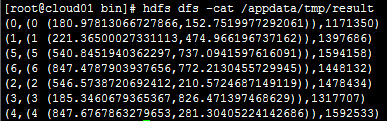
从上述结果可知,数据量虽然扩大了10倍,但时间消耗只增加了不到4倍,足以证明Flink在性能方面的优势。
4、遭遇的问题
在整个开发与部署过程中基本上算是比较顺利,遇到的问题主要是数据在节点上分布不均、企图返回全量结果集时任务僵死、企图调高任务并行度时任务僵死等可用性问题。其根本原因还是当前资源不足,无法开展必要的性能调优工作所导致。
四、总结
从上述代码可以看出,通过Flink+Scala开发仅用短短30多行代码就完成K-Means算法,同时,配合Hadoop Yarn一起使用,能很方便地支持计算节点不受限的横向扩展,说明Flink针对海量数据的流式计算处理方面还是很方便的。