tensorflow中四种不同交叉熵函数tf.nn.softmax_cross_entropy_with_logits()
Tensorflow中的交叉熵函数
tensorflow中自带四种交叉熵函数,可以轻松的实现交叉熵的计算。
tf.nn.softmax_cross_entropy_with_logits()
tf.nn.sparse_softmax_cross_entropy_with_logits()
tf.nn.sigmoid_cross_entropy_with_logits()
tf.nn.weighted_cross_entropy_with_logits()注意:tensorflow交叉熵计算函数输入中的logits都不是softmax或sigmoid的输出,而是softmax或sigmoid函数的输入,因为它在函数内部进行sigmoid或softmax操作。而且不能在交叉熵函数前进行softmax或sigmoid,会导致计算会出错。
一、sigmoid交叉熵
- tf.nn.sigmoid_cross_entropy_with_logits(_sentinel=None,labels=None, logits=None, name=None)
argument:
_sentinel:本质上是不用的参数,不用填
logits:计算的输出,注意是为使用softmax或sigmoid的,维度一般是[batch_size, num_classes] ,单样本是[num_classes]。数据类型(type)是float32或float64;
labels:和logits具有相同的type(float)和shape的张量(tensor),即数据类型和张量维度都一致。
name:操作的名字,可填可不填
output:
loss,shape:[batch_size,num_classes]
注意:它对于输入的logits先通过sigmoid函数计算,再计算它们的交叉熵,但是它对交叉熵的计算方式进行了优化,使得结果不至于溢出。output不是一个数,而是一个batch中每个样本的loss,所以一般配合tf.reduce_mea(loss)使用。
例子:
import tensorflow as tf
import numpy as np
def sigmoid(x):
return 1.0 / (1 + np.exp(-x))
# 5个样本三分类问题,且一个样本可以同时拥有多类
y = np.array([[1, 0, 0], [0, 1, 0], [0, 0, 1], [1, 1, 0], [0, 1, 0]])
logits = np.array([[12, 3, 2], [3, 10, 1], [1, 2, 5], [4, 6.5, 1.2], [3, 6, 1]])
y_pred = sigmoid(logits)
E1 = -y * np.log(y_pred) - (1 - y) * np.log(1 - y_pred)
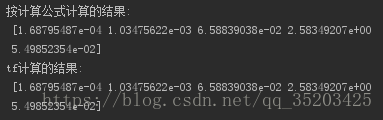
print('按计算公式计算的结果:\n',E1) # 按计算公式计算的结果
sess = tf.Session()
y = np.array(y).astype(np.float64) # labels是float64的数据类型
E2 = sess.run(tf.nn.sigmoid_cross_entropy_with_logits(labels=y, logits=logits))
print('tf计算的结果:\n',E2)
# 输出的E1,E2结果相同

二、softmax交叉熵
- tf.nn.softmax_cross_entropy_with_logits(_sentinel=None, labels=None, logits=None, dim=-1, name=None)
argument:
_sentinel:本质上是不用的参数,不用填
logits:计算的输出,注意是为使用softmax或sigmoid的,维度一般是[batch_size, num_classes] ,单样本是[num_classes]。数据类型(type)是float32或float64;
labels:和logits具有相同的type(float)和shape的张量(tensor),即数据类型和张量维度都一致。
name:操作的名字,可填可不填
output:
loss,shape:[batch_size]
其他同上
例子:
import tensorflow as tf
import numpy as np
def softmax(x):
sum_raw = np.sum(np.exp(x), axis=-1)
x1 = np.ones(np.shape(x))
for i in range(np.shape(x)[0]):
x1[i] = np.exp(x[i]) / sum_raw[i]
return x1
y = np.array([[1, 0, 0], [0, 1, 0], [0, 0, 1], [1, 0, 0], [0, 1, 0]]) # 每一行只有一个1
logits = np.array([[12, 3, 2], [3, 10, 1], [1, 2, 5], [4, 6.5, 1.2], [3, 6, 1]])
y_pred = softmax(logits)
E1 = -np.sum(y * np.log(y_pred), -1)
sess = tf.Session()
y = np.array(y).astype(np.float64)
E2 = sess.run(tf.nn.softmax_cross_entropy_with_logits(labels=y, logits=logits))
print('按计算公式计算的结果:\n', E1) # 按计算公式计算的结果
print('tf计算的结果:\n', E2)
# 输出的E1,E2结果相同
三、sparse_softmax交叉熵
- tf.nn.sparse_softmax_cross_entropy_with_logits(_sentinel=None,labels=None,logits=None, name=None)
argument:
_sentinel:本质上是不用的参数,不用填
logits:一个数据类型(type)是float32或float64;
shape:[batch_size,num_classes]
labels: shape为[batch_size],labels[i]是{0,1,2,……,num_classes-1}的一个索引, type为int32或int64,说白了就是当使用这个函数时,tf自动将原来的类别索引转换成one_hot形式,然后与label表示的one_hot向量比较,计算交叉熵。
name: 操作的名字,可填可不填
output:
loss,shape:[batch_size]
例子:
import tensorflow as tf
# 假设只有三个类,分别编号0,1,2,labels就可以直接输入下面的向量,不用转换与logits一致的维度
labels = [0,1,2]
logits = [[2,0.5,1],
[0.1,1,3],
[3.1,4,2]]
logits_scaled = tf.nn.softmax(logits)
result = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=labels, logits=logits)
with tf.Session() as sess:
print(sess.run(result))
![]()
四、weighted交叉熵
- tf.nn.weighted_cross_entropy_with_logits(labels,logits, pos_weight, name=None)
计算具有权重的sigmoid交叉熵sigmoid_cross_entropy_with_logits()
argument:
_sentinel:本质上是不用的参数,不用填
logits:一个数据类型(type)是float32或float64;
shape:[batch_size,num_classes],单样本是[num_classes]
labels:和logits具有相同的type(float)和shape的张量(tensor),
pos_weight:正样本的一个系数
name:操作的名字,可填可不填
output:
loss,shape:[batch_size,num_classes]
以上参考很多博客,在此感谢。