金蝶云之家前端面经
目录
1、vue router路由钩子
完整的导航解析流程
2、浏览器强弱缓存
强缓存
弱缓存
3、v-show 是display:none // display opacity visibility
4、简单请求和复杂请求
5、http2
6、vuex可以直接更改state吗
7、权限路由
8、vue生命周期
9、双向绑定原理
10、实现跨域
11、同源策略
12、自适应和响应式的区别
13、em和rem
跨域解决方案
15、浏览器存储方法 localstorage、sessionstorage、
16、h5语义化优点
17、get和post的区别
18、懒加载原理实现方法
19、前端如何让页面渲染更快
一、减少请求资源大小或者次数
二、代码优化相关
20、dom事件流三个阶段,怎么阻止冒泡
21、重绘回流
区别:
22、display visibility opacity
23、css水平垂直居中的方法
24、清除浮动的方法
25、css的两种盒模型
26、深拷贝和浅拷贝的区别、怎么实现深拷贝
27、js new的内部原理
32、js事件循环
33、宏任务和微任务有哪些
34、闭包、闭包缺点
35、call、apply、bind区别
36、js 基本类型和引用类型有哪些、区别
37、url到显示页面发生了什么
38、http在哪层?七层协议
39、常用http请求有哪些、get和post的区别
42、es5模拟块级作用域(闭包)
1、vue router路由钩子
vue router路由钩子,导航守卫。vue-router 提供的导航守卫主要用来通过跳转或取消的方式守卫导航。
记住参数或查询的改变并不会触发进入/离开的导航守卫。你可以通过观察 $route 对象来应对这些变化,或使用 beforeRouteUpdate 的组件内守卫。
路由钩子函数有三种:
1:全局钩子: beforeEach、 afterEach
2:单个路由里面的钩子: beforeEnter、 beforeLeave
3:组件路由:beforeRouteEnter、 beforeRouteUpdate、 beforeRouteLeave
(1)全局前置守卫 router.beforeEach()
const router = new VueRouter({ ... })
router.beforeEach((to, from, next) => {
// ...
})
当一个导航触发时,全局前置守卫按照创建顺序调用。守卫是异步解析执行,此时导航在所有守卫 resolve 完之前一直处于 等待中。
每个守卫方法接收三个参数:
-
to: Route: 即将要进入的目标 路由对象 -
from: Route: 当前导航正要离开的路由 -
next: Function: 一定要调用该方法来 resolve 这个钩子。执行效果依赖next方法的调用参数。-
next(): 进行管道中的下一个钩子。如果全部钩子执行完了,则导航的状态就是 confirmed (确认的)。 -
next(false): 中断当前的导航。如果浏览器的 URL 改变了 (可能是用户手动或者浏览器后退按钮),那么 URL 地址会重置到from路由对应的地址。 -
next('/')或者next({ path: '/' }): 跳转到一个不同的地址。当前的导航被中断,然后进行一个新的导航。你可以向next传递任意位置对象,且允许设置诸如replace: true、name: 'home'之类的选项以及任何用在router-link的toprop 或router.push中的选项。 -
next(error): (2.4.0+) 如果传入next的参数是一个Error实例,则导航会被终止且该错误会被传递给router.onError()注册过的回调。
-

(2)全局解析守卫 router.beforeResolve
在 2.5.0+ 你可以用 router.beforeResolve 注册一个全局守卫。这和 router.beforeEach 类似,区别是在导航被确认之前,同时在所有组件内守卫和异步路由组件被解析之后,解析守卫就被调用。
(3)全局后置钩子 router.afterEach
你也可以注册全局后置钩子,然而和守卫不同的是,这些钩子不会接受 next 函数也不会改变导航本身:这些守卫与全局前置守卫的方法参数是一样的。
(4)组件内的守卫
beforeRouteEnterbeforeRouteUpdate(2.2 新增)beforeRouteLeave
const Foo = {
template: `...`,
beforeRouteEnter (to, from, next) {
// 在渲染该组件的对应路由被 confirm 前调用
// 不!能!获取组件实例 `this`
// 因为当守卫执行前,组件实例还没被创建
},
beforeRouteUpdate (to, from, next) {
// 在当前路由改变,但是该组件被复用时调用
// 举例来说,对于一个带有动态参数的路径 /foo/:id,在 /foo/1 和 /foo/2 之间跳转的时候,
// 由于会渲染同样的 Foo 组件,因此组件实例会被复用。而这个钩子就会在这个情况下被调用。
// 可以访问组件实例 `this`
},
beforeRouteLeave (to, from, next) {
// 导航离开该组件的对应路由时调用
// 可以访问组件实例 `this`
}
}
完整的导航解析流程
- 导航被触发。
- 在失活的组件里调用离开守卫。
- 调用全局的
beforeEach守卫。 - 在重用的组件里调用
beforeRouteUpdate守卫 (2.2+)。 - 在路由配置里调用
beforeEnter。 - 解析异步路由组件。
- 在被激活的组件里调用
beforeRouteEnter。 - 调用全局的
beforeResolve守卫 (2.5+)。 - 导航被确认。
- 调用全局的
afterEach钩子。 - 触发 DOM 更新。
- 用创建好的实例调用
beforeRouteEnter守卫中传给next的回调函数。
2、浏览器强弱缓存
浏览器向服务器请求某一资源时,会先判断本地有无该资源缓存,如果已有缓存,则获取该资源缓存的 header 信息,根据 header 中的 Control 和 Expires (即强缓存)来判断是否过期。这一时刻是没有向服务器发出请求的。
若显示已过期,浏览器会向服务器发送请求,通过 header 中的 Etag 和 Last-Modified(协商缓存)让服务器验证。若不需更新资源,返回状态码 304;若需要更新,则返回最新资源和状态码 200
浏览器缓存主要分为强缓存(也称本地缓存)和协商缓存(也称弱缓存)。
强缓存
| http1.1 | http1.0 | |
|---|---|---|
| 强缓存 | Cache-Control 强缓存利用的是max-age的值来实现缓存资源的最大生命周期,单位是秒。 |
Expires 它的值是一个绝对时间的GMT格式的时间字符串,代表资源失效时间。 |
| 协商缓存 | Etag/If None Match 当资源被缓存时,服务器返回的 header 上有 Etag。 当资源文件向服务器确认缓存是否可用时,会向服务器发送一个 request header 带有 If-None-Match 字段,值为当前文件的 Etag。服务器根据浏览器上送的If-None-Match 值来判断是否命中缓存。 |
Last Modify/If Modify Since 浏览器第一次请求一个资源的时候,response header 会加上 Last-Modify,Last-modify 是一个时间标识该资源的最后修改时间。 当浏览器再次请求该资源时,request 的请求头中会包含 If-Modify-Since,该值为缓存之前返回的 Last-Modify。服务器收到If-Modify-Since 后,根据资源的最后修改时间判断是否命中缓存。 |

弱缓存
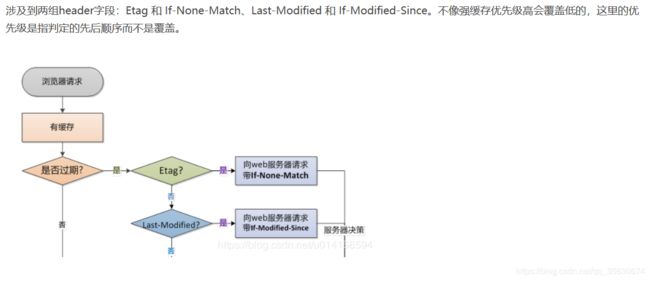
Last-Modify/If-Modify-Since
Last-Modify(实体首部)/If-Modify-Since(请求首部)是 http1.0 的规范,格式:Last-Modify: Fri, 19 Apr 2019 01:34:53 GMT
浏览器第一次请求一个资源的时候,response header 会加上 Last-Modify,Last-modify 是一个时间标识该资源的最后修改时间。
当浏览器再次请求该资源时,request 的请求头中会包含 If-Modify-Since,该值为缓存之前返回的 Last-Modify。服务器收到If-Modify-Since 后,根据资源的最后修改时间判断是否命中缓存。
如果命中缓存,返回304,则不会返回资源内容,并且不会返回 Last-Modify。
Etag和If-None-Match
Etag(响应首部)/If-None-Match(请求首部)是 http1.1 的规范,返回的是一个校验码,保证每一个资源是唯一的,格式: Etag:22FAA065-2664-4197-9C5E-C92EA03D0A16。
当资源被缓存时,服务器返回的 header 上有 Etag。当资源文件向服务器确认缓存是否可用时,会向服务器发送一个 request header 带有 If-None-Match 字段,值为当前文件的 Etag。服务器根据浏览器上送的If-None-Match 值来判断是否命中缓存。
与 Last-Modified 不一样的是,当命中缓存,服务器返回 304 Not Modified 的响应时,由于 ETag 重新生成过,response header 中还会把这个 ETag 返回,即使这个 ETag 跟之前的没有变化。
重点是,Etag 的优先级高于 Last-Modify,同时存在则优先判断 Etag,再判断 Last-Modify ,最后才决定是否返回304
3、v-show 是display:none // display opacity visibility
相同点:v-if与v-show都可以动态控制dom元素显示隐藏
不同点:v-if显示隐藏是将dom元素整个添加或删除(比如div会被删掉),而v-show隐藏则是为该元素添加css--display:none,dom元素还在。
需要注意的是,当一个元素默认在css中加了display:none属性,这时通过if-show修改为true是无法让元素显示的。原因是显示隐藏切换,只是会修改element style为display:""或者display:none,并不会覆盖掉或修改已存在的css属性。
详细区别:
1.手段:v-if是动态的向DOM树内添加或者删除DOM元素;v-show是通过设置DOM元素的display样式属性控制显隐;
2.编译过程:v-if切换有一个局部编译/卸载的过程,切换过程中合适地销毁和重建内部的事件监听和子组件;v-show只是简单的基于css切换;
3.编译条件:v-if是惰性的,如果初始条件为假,则什么也不做;只有在条件第一次变为真时才开始局部编译(编译被缓存?编译被缓存后,然后再切换的时候进行局部卸载); v-show是在任何条件下(首次条件是否为真)都被编译,然后被缓存,而且DOM元素保留;
4.性能消耗:v-if有更高的切换消耗;v-show有更高的初始渲染消耗;
5.使用场景:v-if适合运营条件不大可能改变;v-show适合频繁切换。
1.display:none是彻底消失,不在文档流中占位,浏览器也不会解析该元素;
visibility:hidden是视觉上消失了,可以理解为透明度为0的效果,在文档流中占位,浏览器会解析该元素;
2.使用visibility:hidden比display:none性能上要好,
display:none切换显示时,页面产生回流(当页面中的一部分元素需要改变规模尺寸、布局、显示隐藏等,页面重新构建,此时就是回流。所有页面第一次加载时需要产生一次回流),
而visibility切换是否显示时则不会引起回流。
3.opacity: 0 是透明度为0
具体来说应该是:
1 opacity=0,该元素隐藏起来了,但不会改变页面布局,并且,如果该元素已经绑定一些事件,如click事件,
那么点击该区域,也能触发点击事件的
2 visibility=hidden,该元素隐藏起来了,但不会改变页面布局,
但是不会触发该元素已经绑定的事件
3 display=none,把元素隐藏起来,并且会改变页面布局,可以理解成在页面中把该元素删除掉一样,但是dom元素还在4、简单请求和复杂请求
跨域资源共享(简称cors,后面使用简称)来解决跨域问题。会用到的两种请求。
1. 简单请求:
满足一下两个条件的请求。
(1) 请求方法是以下三种方法之一:
- HEAD
- GET
- POST
(2)HTTP的头信息不超出以下几种字段:
- Accept
- Accept-Language
- Content-Language
- Last-Event-I
- D
- Content-Type:只限于三个值
application/x-www-form-urlencoded、multipart/form-data、text/plain
2. 复杂请求:
非简单请求就是复杂请求。
非简单请求是那种对服务器有特殊要求的请求,比如请求方法是PUT或DELETE,或者Content-Type字段的类型是application/json。
非简单请求的CORS请求,会在正式通信之前,增加一次HTTP查询请求,称为"预检"请求(preflight)。
预检请求为OPTIONS请求,用于向服务器请求权限信息的。
预检请求被成功响应后,才会发出真实请求,携带真实数据。
axios 都是复杂请求,ajax 可以是简单请求
5、http2
HTTP2.0和HTTP1.X相比的新特性
-
新的二进制格式(Binary Format),HTTP1.x的解析是基于文本。基于文本协议的格式解析存在天然缺陷,文本的表现形式有多样性,要做到健壮性考虑的场景必然很多,二进制则不同,只认0和1的组合。基于这种考虑HTTP2.0的协议解析决定采用二进制格式,实现方便且健壮。
-
多路复用(MultiPlexing),即连接共享,即每一个request都是是用作连接共享机制的。一个request对应一个id,这样一个连接上可以有多个request,每个连接的request可以随机的混杂在一起,接收方可以根据request的 id将request再归属到各自不同的服务端请求里面。
-
header压缩,如上文中所言,对前面提到过HTTP1.x的header带有大量信息,而且每次都要重复发送,HTTP2.0使用encoder来减少需要传输的header大小,通讯双方各自cache一份header fields表,既避免了重复header的传输,又减小了需要传输的大小。
-
服务端推送(server push),同SPDY一样,HTTP2.0也具有server push功能。
6、vuex可以直接更改state吗
不通过mutation,而直接修改state修改确实生效了。这样子多人协作岂不是很容易出问题。对于这个问题,在创建 store 的时候传入 strict: true, 开启严格模式,那么任何修改state的操作,只要不经过mutation的函数,vue就会 throw error。
7、权限路由
全局路由守卫拦截然后vuex存在localstorage里判断
8、vue生命周期
9、双向绑定原理
10、实现跨域
1、 通过jsonp跨域
通常为了减轻web服务器的负载,我们把js、css,img等静态资源分离到另一台独立域名的服务器上,在html页面中再通过相应的标签从不同域名下加载静态资源,而被浏览器允许,基于此原理,我们可以通过动态创建script,再请求一个带参网址实现跨域通信。
2、 document.domain + iframe跨域
此方案仅限主域相同,子域不同的跨域应用场景。
实现原理:两个页面都通过js强制设置document.domain为基础主域,就实现了同域。
(1)父窗口(http://www.demo.com/a.html)
(2)子窗口:(http://child.demo.com/b.html)
3、 location.hash + iframe
4、 window.name + iframe跨域
5、 postMessage跨域
6、 跨域资源共享(CORS)
7、 nginx代理跨域
8、 nodejs中间件代理跨域
9、 WebSocket协议跨域
11、同源策略
源是协议、域名和端口号。若地址里面的协议、域名和端口号均相同则属于同源。
域名和对应的IP之间请求算跨域。

同源策略是浏览器的一个安全功能,不同源的客户端脚本在没有明确授权的情况下,不能读写对方资源。所以a.com下的js脚本采用ajax读取b.com里面的文件数据是会报错的。
- 不受同源策略限制的
- 页面中的链接,重定向以及表单提交是不会受到同源策略限制的。
- 跨域资源的引入是可以的。但是js不能读写加载的内容。如嵌入到页面中的,
,,