分布式事务还是MQ?强一致性还是最终一致性?
文章目录
- 一、单机事务的延伸
- 二、九十年代的XA事务
- XA事务原理
- 三、常见的分布式事务方案
- 事务补偿
- 本地消息表
- 消息队列
- 四、分布式事务框架Seata
- AT模式
- TCC模式
- SAGA模式
- XA模式
一、单机事务的延伸
所谓单机事务,可以理解为单体应用和数据库这两个东西之间实现原子操作的一种方式,其核心要求是实现ACID四种特性。
对于这些特性,有疑问的同学可以看看这篇:聊聊Mysql的事务、Spring中的@Transaction
单体应用中很好的实现了ACID问题,那么当这个问题延伸到微服务之中的时候呢?首先我们要先明确微服务应用和数据库之间的基本架构。
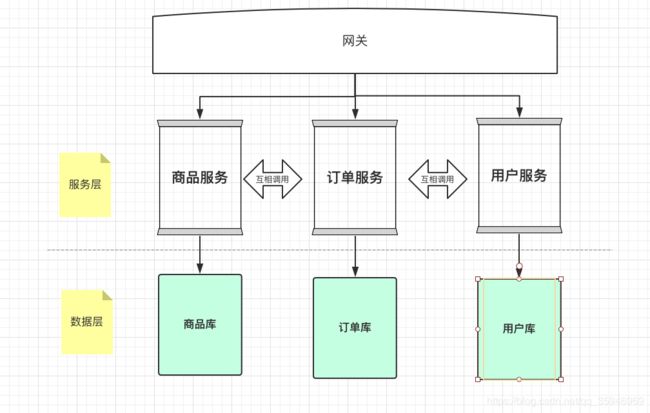
简单来说,服务与数据库是一对一的,同一个服务不会直接去调用其他服务的数据库,而是通过调用其他服务来操作数据库。这样的架构是当下流行的,符合单一职责的。
现在再来看事务的问题,我们有个下单操作,需要同时操作订单库和商品库。应该如何保证这个下单操作的事务?
举个实际的例子来理解这个问题,我们在订单服务开启了事务,在事务中RPC调用了商品服务,成功操作了商品库数据。而此时订单服务继续往下操作自身数据时异常了,回滚本地操作。请问,此时商品库的数据回滚了吗?
答案显然是没有,订单服务的事务只是针对订单库的,无法影响到RPC调用的商品服务,更无法影响到商品库的数据使其回滚。
这就是分布式事务所面临的的问题。
二、九十年代的XA事务
XA事务是一种用来分布式事务的解决方案,但是它并不是符合上述微服务架构的分布式事务解决方案。
此话怎讲?来看下面这个图。
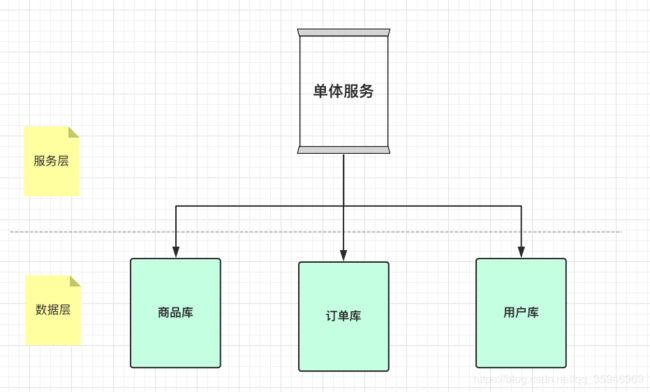
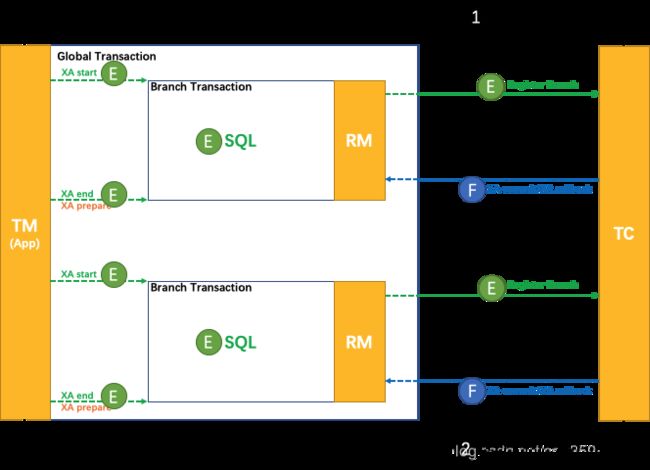
大家会发现,怎么是单体应用啊?是的,XA事务正是用来解决单客户端,多数据源问题的。
XA事务在九十年代提出,由数据库大家族一起实现,无论是哪种关系型数据库,都去实现XA协议,做到在一个客户端开启事务就等同于在连接的所有数据库开启事务。这就是XA事务的初衷。
这么看起来,XA好像没什么用,不,它有用,前人栽树后人乘凉,分布式事务框架Seata就利用了XA这一数据库特性实现了Seata框架本身的`XA模式`。
XA事务原理
XA事务是基于2PC(两阶段提交协议)实现的,它通过XID来统一标识一次事务。
- 客户端在一阶段(prepare阶段),对所有数据源发起perpare请求,所有数据源开启自身XA事务、执行sql,并回复客户端自己准备好了。若此时有任何一个数据源未能成功反馈成功,则本次事务将会进入Rollback阶段。
- 二阶段(Rollback阶段),在一阶段中,有任何一个数据源回复失败,客户端都会放弃本次操作,并通知其他所有数据源,进行事务回滚操作,本次操作完成。
- 二阶段(Commited阶段),在一阶段中,所有数据源都回复成功,客户端就对所有数据源发起Commited,数据源接收到Commited信号,commited本地事务,本次操作完成。
实际上,上面的客户端官方定义是TM(Transaction Management,TM会在客户端自动管理各个数据源的XA事务)、数据源的官方名字是RM(Resource Management)。
XA事务很简单,实际上也存在网络超时、锁资源之类的问题,但是根源上,当下微服务架构它的设计思想不符,我们无法轻易用上它。
那么分布式事务到底该怎么实现呢?
三、常见的分布式事务方案
事务补偿
回想我们之前纠结的问题,订单服务自身回滚了,商品服务却没有回滚,影响了事务的原子性,那么我们在订单服务回滚的时候,手动写一段代码将商品服务的操作回滚是不是也可以?
这确实是一种常见的手法。也符合要么全部成功、要么全部失败的原则,但是它也存在一些问题。
缺点: 最令人诟病的是要自定义回滚操作,订单服务RPC调用的远程服务服务越多,要补偿的代码逻辑就越多。
本地消息表
本地消息表是ebay提出的解决方案,使用一张消息表来记录本次事务,RPC调用方通过不断轮询消息表来查看是否需要自己做点儿什么。
需要注意的是:
- 在订单服务(事务开启方)需要在一个本地事务中进行本地数据操作和消息表操作,保证本地数据操作和消息表操作的原子性。
- 订单服务完成数据后,商品服务多久完成此次事务取决于商品服务的轮询时间间隔,也就是说,该方法能保证最后订单库和商品库数据都是对的,但是不能保证现在他们就都是对的。这就是数据的最终一致性。
- 我们不考虑商品服务的业务逻辑异常问题,这属于bug。
本地消息表是最终一致性的方法,之前的实物补偿是强一致性方法,其区别可以追溯到CAP理论和BASE理论。大白话来说,强一致性保证不存在数据不一致的脏时间,最终一致性可能存在脏时间。
消息队列
消息队列实际上是本地消息表的另一种实现方式,只是将本地消息表的载体替换成了消息队列。
- 使用消息队列,我们同样需要保证发送消息和本地数据操作的原子性。这一点可以用事务消息来保证。比如rocketMQ,它的事务消息可以保证从生产者发送到消息最终在Broker落盘的这一系列中间操作都是原子性的。 事务消息细节有兴趣的同学可以直接去了解,这一部分还是蛮多的。
- 相较于本地消息表,商品服务(消费者)是被动的接收消息并消费,不再需要不断的轮询本地消息表,这是一个优点。
- 我们同样不考虑商品服务的业务逻辑异常问题,这是bug。但是我们要考虑消费者重复消费的问题,这是使用mq的常识。
四、分布式事务框架Seata
seata本质上是独立出来一个节点TC(Transaction coordinator,协调者),这个协调者来进行与所有节点的沟通,TM只需要告诉TC自己要开启事务,要提交/回滚事务,剩下的都由协调者来完成,大大减轻了TM和开发者的负担。
(偷一张Seata官微的原图)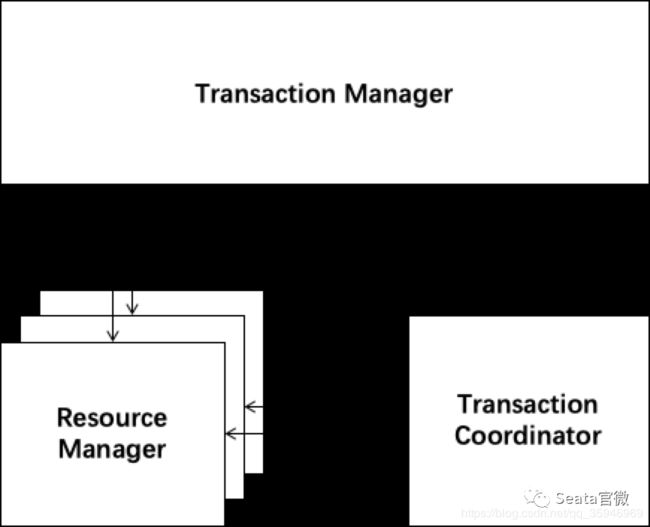
AT模式
一阶段(prepare):所有RM解析当前sql,自动生成回滚日志。执行sql,此时数据库相关数据已被改写。
二阶段(rollback): 所有RM根据之前的回滚日志进行反向sql,将数据库相关数据再改回来。
二阶段(commit):所有RM清除本次事务无关数据,如回滚日志。
缺点:解析sql损耗性能、无法保证脏读(AT默认是读未提交,如果设定读已提交会性能直线下降)。
TCC模式
AT模式的人工版、也就是我们上面提到的事务补偿。AT模式的回滚是自动通过sql解析出来的反向sql,而TCC模式完全把perpare、rollback、commit三个方法的实现全都交给开发者。
缺点:脏读问题同上、代码量可能会恶心死人……
SAGA模式
seata官方意思是长事务的解决方案,saga模式不再依赖两阶段提交,而是依赖状态机。
简单来说,事务一旦start,各个RM按照顺序,一个一个执行自己的逻辑,当其中有一个RM执行失败,之前已经执行的RM都需要进行回滚。
当然,SAGA模式的正向业务逻辑和反向回滚逻辑也是开发者自己来写的。
XA模式
Seata的XA模式依赖于数据库原生的XA事务,借助Seata自身独有的TC,实现如下架构方式使用XA事务。