scrapy框架概述以及案例讲解
基本介绍
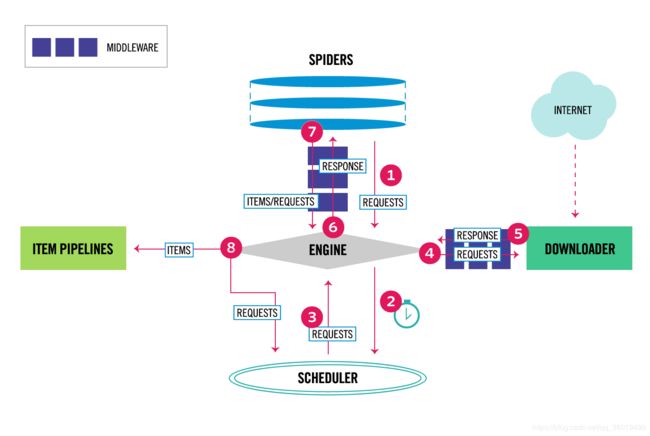
- 引擎(EGINE)
引擎负责控制系统所有组件之间的数据流,并在某些动作发生时触发事件。有关详细信息,请参见上面的数据流部分。 - 调度器(SCHEDULER)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL的优先级队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 - 下载器(DOWLOADER)
用于下载网页内容, 并将网页内容返回给EGINE,下载器是建立在twisted这个高效的异步模型上的 - 爬虫(SPIDERS)
SPIDERS是开发人员自定义的类,用来解析responses,并且提取items,或者发送新的请求 - 项目管道(ITEM PIPLINES)
在items被提取后负责处理它们,主要包括清理、验证、持久化(比如存到数据库)等操作 - 下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间,主要用来处理从EGINE传到DOWLOADER的请求request,已经从DOWNLOADER传到EGINE的响应response,你可用该中间件做以下几件事
process a request just before it is sent to the Downloader (i.e. right before Scrapy sends the request to the website);
change received response before passing it to a spider;
send a new Request instead of passing received response to a spider;
pass response to a spider without fetching a web page;
silently drop some requests. - 爬虫中间件(Spider Middlewares)
位于EGINE和SPIDERS之间,主要工作是处理SPIDERS的输入(即responses)和输出(即requests)
安装
#Windows平台
1、pip3 install wheel #安装后,便支持通过wheel文件安装软件,wheel文件官网:https://www.lfd.uci.edu/~gohlke/pythonlibs
3、pip3 install lxml
4、pip3 install pyopenssl
5、下载并安装pywin32:https://sourceforge.net/projects/pywin32/files/pywin32/
6、下载twisted的wheel文件:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
7、执行pip3 install 下载目录\Twisted-17.9.0-cp36-cp36m-win_amd64.whl
8、pip3 install scrapy
#Linux平台
1、pip3 install scrapy
项目创建命令行
cd 目录名
scrapy startproject 项目名
cd 目录名/spiders
scrapy genspider 爬虫名 “爬取主站的域名”
工作前的配置
settings.py
#忽略反爬协议
ROBOTSTXT_OBEY = False
#标记请求头
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Mobile Safari/537.36'
}
#打开存储管道
ITEM_PIPELINES = {
'qsbk.pipelines.QsbkPipeline': 300, #300代表了优先级,值越小优先级越高
}
#标记延迟
DOWNLOAD_DELAY = 1
爬虫启动命令
1.cmd启动
cd 项目目录下(项目创建的内层目录)
scrapy crawl 爬虫名
2.在项目路径下新建一个启动器 main.py
以下执行命令任选其一即可,两者等价
from scrapy import cmdline
#cmdline.execute('scrapy crawl qsbk_spider'.split())
cmdline.execute(['scrapy','crawl','爬虫名'])
# 爬虫目录结构
1. items.py 用来存放爬虫爬取下来的数据的模型
2. middlewares.py 用了来存放各种中间件的文件
3. pipelines.py 用来将items的模型存储到本地磁盘中
4. settings.py 本爬虫的一些配置信息(比如请求头、多久发送一次请求、ip代理池等)
5. scrapy.cfg 项目的配置文件
6. spiders 包:以后所有的爬虫,都是存放到这个里面
# 爬虫笔记
def parse(self, response):
print(type(response))
运行后可以看到爬虫框架返回的数据类型为
可以进入到Html.Response中查看其源码
可以看到respnonse对象支持text encoding两个静态类方法
以及 xpath css 两种过滤方法
提取出来的数据是selector或是selectorList对象
如果想要获得字符串,那么应该执行get_all 或者get方法
getall方法获取selector中的所有文本,返回的是一个列表,可以用’’.join(content).strip() 处理
get方法 获取的是一个selector中的第一个文本,返回的是一个str类型。
如果数据解析回来,要传给pipeline处理,那么可以使用yield来返回,或者return一个item数据列表
item:建议在items.py中定义好模型,以后就不需要定义字典了
pipeline:这个是专门用来保存数据的,其中有三个方法是会经常用的。
*open_spide(self,item,spider)当爬虫被打开的时候执行
*process_item(self,item,spider)当爬虫有item传过来的时候会被调用
*close_spider(self,spider)当爬虫关闭的时候会被调用
要激活pipeline,应该在settings.py中,设置·ITEM_PIPELINES·
JsonItemExporter 和 JsonLinesItemExporter
保存json数据的时候,可以使用这两个类,让操作变得更加简单。
JsonItemExporter这个是每次把数据添加到内存中,最后统一写到磁盘中,好处是存储的数据是一个满足json规则的数据,坏处是如果数据量比较大,那么比较耗内存
示例代码:
from scrapy.exporters import JsonItemExporter
class QsbkPipeline(object):
#文件启动时就把文件打开
def __init__(self):
self.fp = open('duanzi.json', 'wb') #以二进制形式打开,JsonItemExporter以bytes形式写入
self.exporter = JsonItemExporter(self.fp,ensure_ascii=False,encoding='utf-8') #输出格式
self.exporter.start_exporting() #开始输出
def open_spider(self,spider):
print('爬虫开始了...')
def process_item(self, item, spider):
self.exporter.export_item(item)
return item
def close_spider(self,spider):
self.exporter.finish_exporting()
self.fp.close()
print('爬虫结束了...')
JsonLinesItemExporter这个是每次调用export_item的时候就把这个item的时候就把这个item存储到硬盘中,坏处是每个字典是一行,整个文件不是一个满足json格式的文件,好处是每次处理数据的时候直接存储到了硬盘中,这样不会损耗内存,数据也比较安全。
示例代码如下:
#数据量比较大的情况下使用 JsonLinesItemExporter 防止占用过多内存
from scrapy.exporters import JsonLinesItemExporter
class QsbkPipeline(object):
#文件启动时就把文件打开
def __init__(self):
self.fp = open('duanzi.json', 'wb') #以二进制形式打开,JsonItemExporter以bytes形式写入
self.exporter = JsonLinesItemExporter(self.fp,ensure_ascii=False,encoding='utf-8') #输出格式
def open_spider(self,spider):
print('爬虫开始了...')
def process_item(self, item, spider):
self.exporter.export_item(item) #lines方式写入的话不需要设定开始和结束,写入是在process函数中执行的
return item
def close_spider(self,spider):
self.fp.close()
print('爬虫结束了...')
CrawlSpider
scrapy genspider -t crawl 爬虫名 “爬取主站的域名”
需要使用LinkExtractor和Rule。这两个东西决定爬虫的具体走向。
1.allow设置规则的方法:要能够限制在我们想要的url上面,不要和其他url产生相同的正则表达式。
2.什么情况下使用follow:如果在爬取页面的时候,需要将满足当前的url再进行跟进,那么就设置为True,否则设置为False
3.什么情况下要指定callback,如果这个url对应的页面,只是为了获得更多的url,并不需要里面的数据,可以不设置callback。如果想要获取某个url对应页面中的数据,那么就需要指定一个callback。
scrapy 调试
在工作路径下运行
scrapy shell "需要爬取解析的网页完整链接"
并且在下面运行xpath 选择器,用get或getall查看是否能获得到数据。