大数据框架搭建集群安装配置步骤大全
一《zookeeper集群安装配置》
安装步骤:
提示:要关闭虚拟机的防火墙,执行:service iptables stop
1.准备虚拟机,安装并配置jdk,1.6以上
2.上传zookeeper的安装包 3.4.7版本
3.解压安装 tar -xvf …………
4.配置zookeeper。
5.配置集群模式
①切换到zookeeper安装目录的conf目录,其中有一个zoo_sample.cfg的配置文件,这个一个配置模板文件,我们需要复制这个文件,并重命名为 zoo.cfg。zoo.cfg才是真正的配置文件
![]()
②配置zoo.cfg=》vim zoo.cfg 更改如下几个参数配置:
dataDir。这个参数是存放zookeeper集群环境配置信息的。这个参数默然是配置在 /tmp/zookeeper下的 。但是注意,tmp是一个临时文件夹,这个是linux自带的一个目录,是linux本身用于存放临时文件用的目录。但是这个目录极有可能被清空,所以,重要的文件一定不要存在这个目录下。
所以改成:/home/work/zkdata
注意:这个路径是自定义的,所以目录需要手动创建
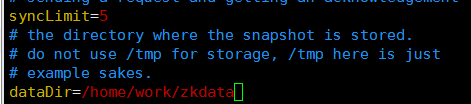
clientport。客户端连接服务器的端口,默认是2181,一般不用修改
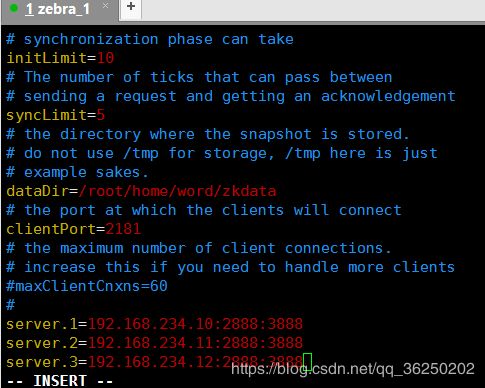
在配置文件里,需要在加上如下的配置:
server.1=192.168.234.10:2888:3888
server.2=192.168.234.11:2888:3888
server.3=192.168.234.12:2888:3888
①server是关键字,写死
②后面的数字是选举id,在zk集群的选举过程中会用到。
补充:此数字不固定,但是需要注意选举id不能重复,相互之间要能比较大小
然后保存退出
③192.168.234.10:2888:3888
说明:2888原子广播端口,3888选举端口
zookeeper有几个节点,就配置几个server,
③配置文件配置好,需要在dataDir目录下创建一个文件
即在:/home/work/zkdata 目录下,创建 myid
vim myid
给当前的节点编号。zookeeper节点在启动时,就会到这个目录下去找myid文件,得知自己的编号
保存退出
6.配置集群环境的其他节点
scp -r 目录 远程ip地址:存放的路径
scp -r /home/software/zookeeper 192.168.234.151: /home/
①更改节点的ip
②更改myid的id号
③关闭防火墙 ,执行:service iptables stop;
7.启动zookeeper
进入到zookeeper安装目录的bin目录
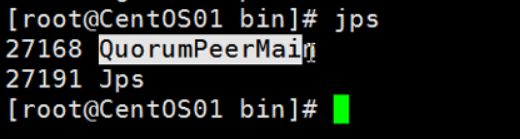
执行:./zkServer.sh start

然后可以输入jps命令,查看有哪些java进程,
执行:jps
8.其他两台节点启动zookeeper服务
9.执行 :./zkServer.sh status 查看当前zookeeper节点状态
配置说明:
tickTime: zookeeper中使用的基本时间单位, 毫秒值.
dataDir: 数据目录. 可以是任意目录.
dataLogDir: log目录, 同样可以是任意目录. 如果没有设置该参数, 将使用和dataDir相同的设置.
clientPort: 监听client连接的端口号
initLimit: zookeeper集群中的包含多台server, 其中一台为leader, 集群中其余的server为follower. initLimit参数配置初始化连接时, follower和leader之间的最长心跳时间. 此时该参数设置为5, 说明时间限制为5倍tickTime, 即5*2000=10000ms=10s.
syncLimit: 该参数配置leader和follower之间发送消息, 请求和应答的最大时间长度. 此时该参数设置为2, 说明时间限制为2倍tickTime, 即4000ms.
二《hadoop高可用的集群安装配置》
安装步骤
0.永久关闭每台机器的防火墙
执行:service iptables stop
再次执行:chkconfig iptables off
1.为每台机器配置主机名以及hosts文件
配置主机名=》执行: vim /etc/sysconfig/network =》然后执行 hostname 主机名=》达到不重启生效目的
配置hosts文件=》执行:vim /etc/hosts
示例:
127.0.0.1 localhost
::1 localhost
192.168.234.21 hadoop01
192.168.234.22 hadoop02
192.168.234.23 hadoop03
2.通过远程命令将配置好的hosts文件 scp到其他5台节点上
执行:scp /etc/hosts hadoop02: /etc
3.为每台机器配置ssh免秘钥登录
执行:ssh-keygen
ssh-copy-id root@hadoop01 (分别发送到6台节点上)
4.前三台机器安装和配置zookeeper
配置conf目录下的zoo.cfg以及创建myid文件
(zookeeper集群安装具体略)
5.为每台机器安装jdk和配置jdk环境
6.为每台机器配置主机名,然后每台机器重启,(如果不重启,也可以配合:hostname hadoop01生效)
执行: vim /etc/sysconfig/network 进行编辑

7.安装和配置01节点的hadoop配置hadoop-env.sh
配置jdk安装所在目录
配置hadoop配置文件所在目录
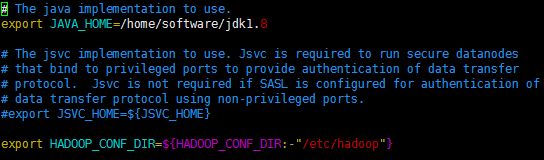
8.配置core-site.xml
9.配置01节点的hdfs-site.xml
配置
10.配置mapred-site.xml
配置代码:
11.配置yarn-site.xml
配置代码:
12.配置slaves文件
配置代码:
hadoop04
hadoop05
hadoop06
13.配置hadoop的环境变量(可不配)
JAVA_HOME=/home/software/jdk1.8
HADOOP_HOME=/home/software/hadoop-2.7.1
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export JAVA_HOME PATH CLASSPATH HADOOP_HOME
14.根据配置文件,创建相关的文件夹,用来存放对应数据
在hadoop-2.7.1目录下创建:
①journal目录
②创建tmp目录
③在tmp目录下,分别创建namenode目录和datanode目录
15.通过scp 命令,将hadoop安装目录远程copy到其他5台机器上
比如向hadoop02节点传输:
scp -r hadoop-2.7.1 hadoop02:/home/software
Hadoop集群启动
16.启动zookeeper集群
在Zookeeper安装目录的bin目录下执行:sh zkServer.sh start
17.格式化zookeeper
在zk的leader节点上执行:
hdfs zkfc -formatZK,这个指令的作用是在zookeeper集群上生成hadoop-ha节点(ns节点)

注:18--24步可以用一步来替代:进入hadoop安装目录的sbin目录,执行:start-dfs.sh 。但建议还是按部就班来执行,比较可靠。
18.启动journalnode集群
在01、02、03节点上执行:
切换到hadoop安装目录的bin目录下,执行:
sh hadoop-daemons.sh start journalnode
然后执行jps命令查看:
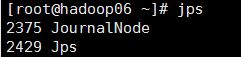
19.格式化01节点的namenode
在01节点上执行:
hadoop namenode -format
20.启动01节点的namenode
在01节点上执行:
hadoop-daemon.sh start namenode
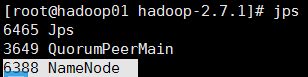
21.把02节点的 namenode节点变为standby namenode节点
在02节点上执行:
hdfs namenode -bootstrapStandby

22.启动02节点的namenode节点
在02节点上执行:
hadoop-daemon.sh start namenode
23.在01,02,03节点上启动datanode节点
在01,02,03节点上执行: hadoop-daemon.sh start datanode
24.启动zkfc(启动FalioverControllerActive)
在01,02节点上执行:
hadoop-daemon.sh start zkfc
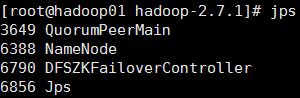
25.在01节点上启动 主Resourcemanager
在01节点上执行:start-yarn.sh
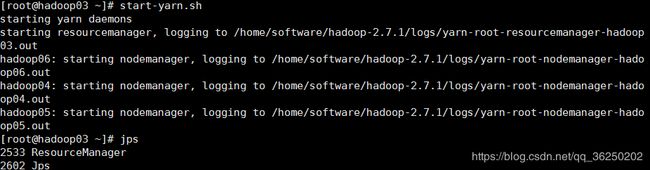
启动成功后,04,05,06节点上应该有nodemanager 的进程
26.在03节点上启动副 Resoucemanager
在03节点上执行:yarn-daemon.sh start resourcemanager
27.测试
输入地址:http://192.168.234.21:50070,查看namenode的信息,是active状态的
输入地址:http://192.168.234.22:50070,查看namenode的信息,是standby状态
然后停掉01节点的namenode,此时返现standby的namenode变为active。
28.查看yarn的管理地址
http://192.168.234.21:8088(节点01的8088端口)
三《flume安装和配置》
实现步骤:
1.安装jdk,1.6版本以上
2.上传flume的安装包
3.解压安装
4.在conf目录下,创建一个配置文件,比如:template.conf(名字可以不固定,后缀也可以不固定)
5.配置agent组件
相关配置:
#配置Agent a1 的组件
a1.sources=r1
a1.channels=c1 (可以配置多个,以空格隔开,名字自己定)
a1.sinks=s1 (可以配置多个,以空格隔开,名字自己定)
#描述/配置a1的r1
a1.sources.r1.type=netcat (netcat表示通过指定端口来访问)
a1.sources.r1.bind=0.0.0.0 (表示本机)
a1.sources.r1.port=44444 (指定的端口,此端口不固定,但是不要起冲突)
#描述a1的s1
a1.sinks.s1.type=logger (表示数据汇聚点的类型是logger日志)
#描述a1的c1
a1.channels.c1.type=memory
a1.channels.c1.capacity=1000
a1.channels.c1.transactionCapacity=100
#位channel 绑定 source和sink
a1.sources.r1.channels=c1 (一个source是可以对应多个通道的)
a1.sinks.s1.channel=c1 (一个sink,只能对应一个通道)
6.根据指定的配置文件,来启动flume
进入flume的bin目录
执行: ./flume-ng agent -n a1 -c ../conf -f ../conf/template.conf -Dflume.root.logger=INFO,console
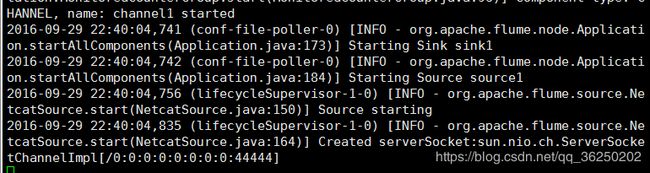
如果出现上图所示,证明配置和启动成功
7.通过nc来访问:
nc localhost 44444
hello flume
![]()
或者:
通过外部http请求访问对应的ip和端口
比如:http://192.168.234.163:44444/hello
在虚拟机这边,会出现如下提示:

启动命令解释
| 参数 |
描述 |
| agent |
运行一个Flume Agent |
| --conf,-c |
指定配置文件放在什么目录 |
| --conf-file,-f |
指定配置文件,这个配置文件必须在全局选项的--conf参数定义的目录下 |
| --name,-n |
Agent的名称,注意:要和配置文件里的名字一致。 |
| -Dproperty=value |
设置一个JAVA系统属性值。常见的:-Dflume.root.logger=INFO,console |
四《hive的安装和配置》
实现步骤
1.安装JDK
2.安装Hadoop
3.配置JDK和Hadoop的环境变量
4.下载Hive安装包
5.解压安装hive
6.启动Hadoop的HDFS和Yarn
7.启动Hive
进入到bin目录,指定:sh hive (或者执行:./hive)
![]()
Linux 下安装Mysql
安装步骤
1.下载mysql安装包
2.确认当前虚拟机之前是否有安装过mysql
执行:rpm -qa 查看linux安装过的所有rpm包
执行:rpm -qa | grep mysql
如果出现下图,证明已经安装了mysql,需要删除
![]()
3.删除mysql
执行:rpm -ev --nodeps mysql-libs-5.1.71-1.el6.x86_64
此时,再执行:rpm -qa | grep mysql 发现没有相关信息了
4.新增mysql用户组,并创建mysql用户
groupadd mysql
useradd -r -g mysql mysql
5.安装mysql server rpm包和client包
执行:rpm -ivh MySQL-server-5.6.29-1.linux_glibc2.5.x86_64.rpm
rpm -ivh MySQL-client-5.6.29-1.linux_glibc2.5.x86_64.rpm
6.安装后,mysql文件所在的目录
Directory Contents of Directory
/usr/bin Client programs and scripts
/usr/sbin The mysqld server
/var/lib/mysql Log files, databases
/usr/share/info MySQL manual in Info format
/usr/share/man Unix manual pages
/usr/include/mysql Include (header) files
/usr/lib/mysql Libraries
/usr/share/mysql Miscellaneous support files, including error messages, character set files, sample configuration files, SQL for database installation
/usr/share/sql-bench Benchmarks
7.修改my.cnf,默认在/usr/my.cnf
执行:vim /usr/my.cnf
[client]
default-character-set=utf8
[mysql]
default-character-set=utf8
[mysqld]
character_set_server=utf8
8.将mysqld加入系统服务,并随机启动
执行:cp /usr/share/mysql/mysql.server /etc/init.d/mysqld
说明:/etc/init.d 是linux的一个特殊目录,放在这个目录的命令会随linux开机而启动。
9.启动mysqld
执行:service mysqld start

10.查看初始生成的密码
执行:vim /root/.mysql_secret 。这个密码随机生成的

11.修改初始密码
第一次安装完mysql后,需要指定登录密码
执行:mysqladmin -u root -p password root 此时,提示要输入初始生成的密码,拷贝过来即可
10.进入mysql数据库
执行:mysql -u root -p
输入:root进入
执行:\s
查看mysql数据配置信息
注意:Mysql安装遇到问题解决方法
1.执行:rpm -qa | grep Percona
通过:rpm -ev --nodeps Percona……
2.执行:rpm -rf /var/lib/mysql
rpm -rf /etc/my.cnf.d
3.查看服务器内置的mysql
执行:rpm -qa | grep mysql
rpm -ev --nodeps mysql……
4.安装 mysql-server 和mysql-client
5.配置my.cnf 字符集
6.将mysqld服务随机启动目录
7.启动mysqld服务
Hive的mysql安装配置
实现步骤:
1.删除hdfs中的/user/hive
执行:hadoop fs -rmr /user/hive
2.将mysql驱动包上传到hive安装目录的lib目录下
3.编辑新的配置文件,名字为:hive-site.xml
4.配置相关信息:
5.进入hive ,进入bin目录,执行:sh hive
如果出现:
Access denied for user 'root'@'hadoop01' (using password: YES)这个错误,指的是当前用户操作mysql数据库的权限不够。
6.进入到mysql数据库,进行权限分配
执行:
grant all privileges on *.* to 'root'@'hadoop01' identified by 'root' with grant option;
grant all on *.* to 'root'@'%' identified by 'root';
然后执行:
flush privileges;
7.如果不事先在mysql里创建hive数据库,在进入hive时,mysql会自动创建hive数据库。但是注意,因为我们之前配置过mysql的字符集为utf-8,所以这个自动创建的hive数据库的字符集是utf-8的。
但是hive要求存储元数据的字符集必须是iso8859-1。如果不是的话,hive会在创建表的时候报错(先是卡一会,然后报错)。
解决办法:在mysql数据里,手动创建hive数据库,并指定字符集为iso8859-1;
进入mysql数据库,
然后执行:create database hive character set latin1;
8.以上步骤都做完后,再次进入mysql的hive数据,发现有如下的表:
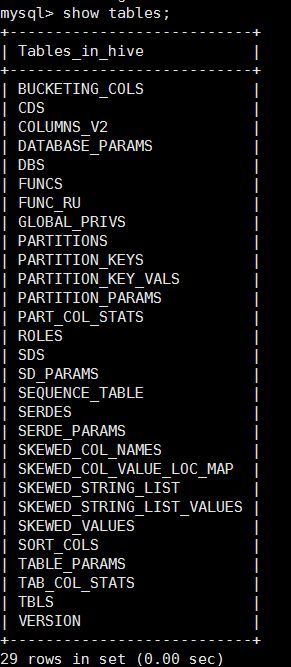
9.可以通过navicat来连接数据库。
10.可以通过DBS 、TBLS、COLUMNS_V2这三张表来查看元数据信息。
DBS 存放的数据库的元数据信息
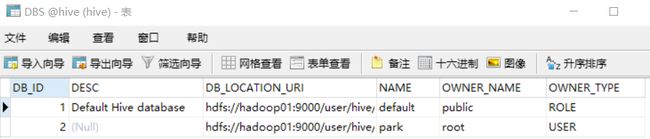
TBLS存放的tables表信息
COLUMNS表存放的是列字段信息
此外,可以通过查看SDS表来查询HDFS里的位置信息

五《kafka的安装配置》
实现步骤:
1.从官网下载安装包 http://kafka.apache.org/downloads
2.上传到01虚拟机,解压
3.进入安装目录下的config目录
4.对server.properties进行配置
配置示例:
broker.id=0
log.dirs=/home/software/kafka/kafka-logs
zookeeper.connect=hadoop01:2181,hadoop02:2181,hadoop03:2181
delete.topic.enable=true
advertised.host.name=192.168.234.21
advertised.port=9092
5.保存退出后,别忘了在安装目录下创建 kafka-logs目录
6.配置其他两台虚拟机,更改配置文件的broker.id编号(不重复即可)
7.先启动zookeeper集群
8.启动kafka集群
进入bin目录
执行:sh kafka-server-start.sh ../config/server.properties
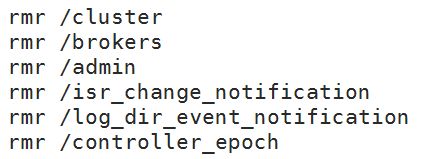
Kafka在Zookeeper下的路径:
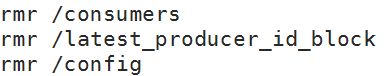
六《HBASE完全分布式安装》
实现步骤
1.准备三台虚拟机,01作为主节点,02、03作为从节点。(把每台虚拟机防火墙都关掉,配置免密码登录,配置每台的主机名和hosts文件。)
2.01节点上安装和配置:Hadoop+Hbase+JDK+Zookeeper
3.02、03节点上安装和配置:Hbase+JDK+Zookeeper
4.修改conf/hbase-env.sh
配置示例:
#修改JAVA_HOME
export JAVA_HOME=xxxx
#修改Zookeeper和Hbase的协调模式,hbase默认使用自带的zookeeper,如果需要使用外部zookeeper,需要先关闭。
export HBASE_MANAGES_ZK=false
5.修改hbase-site.xml,配置开启完全分布式模式
配置示例:
#配置Zookeeper的连接地址与端口号
6.配置region服务器,修改conf/regionservers文件,每个主机名独占一行,hbase启动或关闭时会按照该配置顺序启动或关闭主机中的hbase
配置示例:
hadoop01
hadoop02
hadoop03
7.将01节点配置好的hbase通过远程复制拷贝到02,03节点上
8.启动01,02,03的Zookeeper服务
9.启动01节点的Hadoop
10.启动01节点的Hbase,进入到hbase安装目录下的bin目录
执行:sh start-hbase.sh
11.查看各节点的java进程是否正确
12.通过浏览器访问http://xxxxx:60010来访问web界面,通过web见面管理hbase
13.关闭Hmaster,进入到hbase安装目录下的bin目录
执行:stop-hbase.sh
14.关闭regionserver,进入到hbase安装目录下的bin目录
执行:sh hbase-daemon.sh stop regionserver
注:HBASE配置文件说明
hbase-env.sh配置HBase启动时需要的相关环境变量
hbase-site.xml配置HBase基本配置信息
HBASE启动时默认使用hbase-default.xml中的配置,如果需要可以修改hbase-site.xml文件,此文件中的配置将会覆盖hbase-default.xml中的配置
修改配置后要重启hbase才会起作用
《Phoenix介绍和安装》
介绍
HBase基础上架构的SQL中间件。让我们可以通过SQL/JDBC来操作HBase
安装实现步骤:
1.上传Phoenix安装包到linux服务器并解压,这台linux服务器最好是Hbase Master节点。所以,如果是一个Hbase集群,我们不需要在全部的服务节点上来安装Phoenix。
![]()
2.将Phoneix安装目录下的两个jar包,拷贝到Hbase安装目录下的lib目录
phoenix-4.8.1-HBase-0.98-server.jar
phoenix-4.8.1-HBase-0.98-client.jar
cp phoenix-4.8.1-HBase-0.98-server.jar /home/software/hbase/lib
cp phoenix-4.8.1-HBase-0.98-client.jar /home/software/hbase/lib
3.在 etc/profile文件中 配置Hbase的目录路径
配置示例:
JAVA_HOME=/home/software/jdk1.8
HADOOP_HOME=/home/software/hadoop-2.7.1
HBASE_HOME=/home/software/hbase
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export JAVA_HOME PATH CLASSPATH HADOOP_HOME HBASE_HOME
注:配置完之后,别忘了source /etc/profile
4.启动Hadoop
5.启动Zk集群
6.启动Hbase集群
7.进入Phoenix安装目录的bin目录
执行:./sqlline.py hadoop01,hadoop02,hadoop03:2181
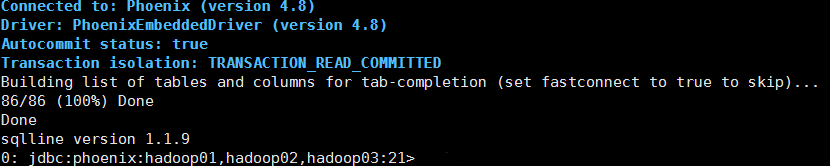
如上图所以,证明Phoenix安装成功
此外,此时进入hbase,执行list查看,会发现多出如下的表:
![]()
如何杀掉Phoenix进程
执行: pstree -p
查看 py进程,杀掉Sqlline的父进程
![]()
七《Spark集群模式安装》
实现步骤:
1)上传解压spark安装包
2)进入spark安装目录的conf目录
3)配置spark-env.sh文件
配置示例:
#本机ip地址
SPARK_LOCAL_IP=hadoop01
#spark的shuffle中间过程会产生一些临时文件,此项指定的是其存放目录,不配置默认是在 /tmp目录下
SPARK_LOCAL_DIRS=/home/software/spark/tmp
export JAVA_HOME=/home/software/jdk1.8
4)在conf目录下,编辑slaves文件
配置示例:
hadoop01
hadoop02
hadoop03
5)配置完后,将spark目录发送至其他节点,并更改对应的 SPARK_LOCAL_IP 配置
启动集群
1)如果你想让 01 虚拟机变为master节点,则进入01 的spark安装目录的sbin目录
执行: sh start-all.sh
2)通过jps查看各机器进程,
01:Master +Worker
02:Worker
03:Worker
3)通过浏览器访问管理界面
http://192.168.234.11:8080
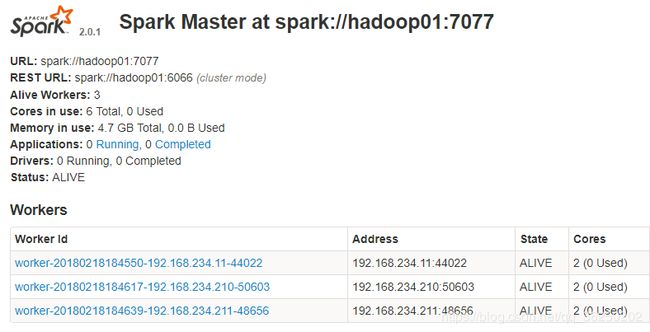
4)通过spark shell 连接spark集群
进入spark的bin目录
执行:sh spark-shell.sh --master spark://192.168.234.11:7077
6)在集群中读取文件:
sc.textFile("/root/work/words.txt")
默认读取本机数据 这种方式需要在集群的每台机器上的对应位置上都一份该文件 浪费磁盘
7)所以应该通过hdfs存储数据
sc.textFile("hdfs://hadoop01:9000/mydata/words.txt");
注:可以在spark-env.sh 中配置选项 HADOOP_CONF_DIR 配置为hadoop的etc/hadoop的地址 使默认访问的是hdfs的路径
注:如果修改默认地址是hdfs地址 则如果想要访问文件系统中的文件 需要指明协议为file 例如 sc.text("file:///xxx/xx")
Spark On Yarn搭建:
实现步骤:
1)搭建好Hadoop(版本,2.7)集群
2)安装和配置scala(版本,2.11)
上传解压scala-2.11.0.tgz—>配置 /etc/profile文件
配置示例:

3)在NodeManager节点(01,02,03节点)上安装和配置Spark
4)进入Spark安装目录的Conf目录,配置:spark-env.sh 文件
配置示例:
export JAVA_HOME=/home/software/jdk1.8
export SCALA_HOME=/home/software/scala-2.11.0
#注意:配置完全分布式的hadoop目录
export HADOOP_HOME=/home/software/hadoop-2.7.1
export HADOOP_CONF_DIR=/home/software/hadoop-2.7.1/etc/hadoop
5)配置:slaves文件,配置worker服务器列表
配置示例:
hadoop01
hadoop02
hadoop03
6)在HDFS上,创建一个目录(自定义),用来存放 spark的依赖jar包
执行: hadoop fs -mkdir /spark_jars
7)进入spark 安装目录的jars目录,
执行:hadoop fs -put ./* /spark_jars
8)进入spark安装目录的 conf目录,配置:spark-defaults.conf 文件
配置示例:
注意:配置namenode地址时,配的是active的namenode
spark.yarn.jars=hdfs://hadoop02:9000/spark_jars/*
9)至此,完成Spark-Yarn的配置。注意:如果是用虚拟机搭建,可能会由于虚拟机内存过小而导致启动失败,比如内存资源过小,yarn会直接kill掉进程导致rpc连接失败。所以,我们还需要配置Hadoop的yarn-site.xml文件,加入如下两项配置:
yarn-site.xml配置示例:
10)启动Hadoop的yarn,进入Hadoop安装目录的sbin目录
执行:sh start-yarn.sh
11)启动spark shell,进入Spark安装目录的bin目录
执行:sh spark-shell --master yarn-client
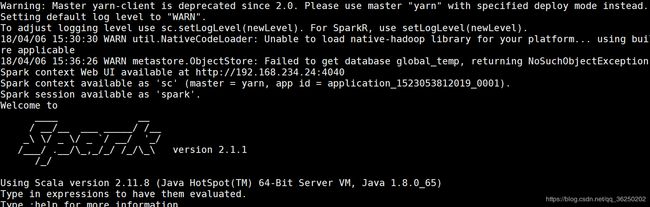
然后可以通过yarn控制台来验证
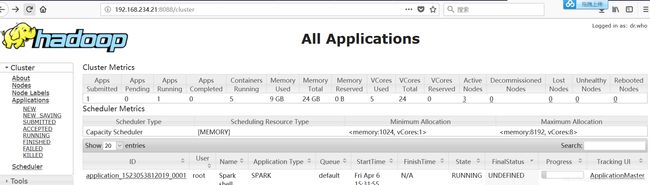
至于spark的使用,和之前都是一样的。只不过资源的分配和管理是交给yarn来控制了。
到这里安装结束,小伙伴们就可以正常使用了。有什么疑问请评论区留言,大家可以互相讨论。scala 的 Windows运行环境配置及使用
请搜索一下一篇博文《scala Windows运行环境配置及使用》