Redis入门到五大类型实现
service redis_6379 start 服务启动6379端口
REDIS的值一共五种类型: String,Hash,List, Set,Zset(Sorted Set)
-
ps -fe | grep redis 查看当前包含redis进程
redis-cli 启动redis程序
exit 退出
redis-cli -h 查看redis代码帮助
redis-cli -p 连接哪个端口
redis-cli -h 连接那一台主机
redis-cli -n连接哪一个数据库
keys * 查看所有key
redis-cli --row 连接redis并重新加载编码 -
redis默认16个库,从0开始,不能重命名,数量可以在配置文件中修改
-
select db_index 进入db_index号数据库
-
每个库都是独立的表,在一个库中不能get到其他库的表内容
-
redis-cli进入后输入help可以获取使用帮助
-
key没有类型区分,value有五种类型 string(byte)包含 字符串、数值、bitmap
-
Object相关指令 object encoding key 查看key的value的类型(例:set k1 99, type k1 = int,int不是数据库五大类型之一,他是string类型的一种数值,查看value这个值的类型,跟设置的方法无关)
-
string类型(String一共分为数值,字符串和bitmap三种)
①:字符串相关
set key value nx 新建key的value,失败返回nil(nx代表key不存在时才可以新建key:value,使用场景:分布式锁,一群人调用一个redis,一个成功其他都为nil)
set key value xx 更新key的value,失败返回nil(xx代表key存在时才可以更新key:value)
mset key value key value … … 批量设置key value
mget key key … … 批量获取key的 value
append key “” 在key的value后追加str字符串
getrange key 取出key从start下标到end下标的字符串(索引和java字符串一样是从0开始下标) 元素的正向索引(从左往右)从0开始,逆向索引(从右往左)从-1开始-2 -3 …
setrange key 将key的value从offset索引位以后都替换为str strlen key 获取key的value的字节长度
type key 查看当初设置key:value的组的类型(例:set k1 99, type k1 = string,因为Set方法属于string类型的组,type只会查看当初设置这个value所用方法属于是什么类型)
getset key newValue 把key的value改为newValue并返回原value
msetnx key value key value … … 批量设置多个key的value,只有key不存在时才可以设置,这个方法具有原子性,多个key value只要有一个key存在,这方法所有key value设置无效
②:数值相关
incr key 若value值为int类型,直接+1,存入key的value
incrby key 给value值加int,存入key的value decr key -1,存入 decrby key -int存入
incrbyfloat key +float(比如0.5),存入 float相关类似上面 -
redis中二进制安全
①:因为在不同的语言中对int的宽度的理解是不同的,所以一般来讲跨语言都比较喜欢实用json,xml这种文本的传输,而不使用序列化,因为容易发生数据的溢出截断。 由于这种情况,redis的二进制安全就是这种意思,redis只取字节流而不取字符流,因为编码、语言的不同造成的数据截断等情况不会发生,给什么存什么,不会发生字节流转换字符流出现溢出阶段,所以读取的时候客户端的编码和redis的编码一致就不会乱码,但内容实际上不会发生改变,即存的时候的编码风格只不过看的时候因为编码不一致而乱码,保证了数据存储的安全。
②: key有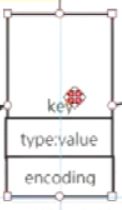 两个过程。
两个过程。
1)先进行type:value的过程,如果类型不对报错,防止程序中进行计算再出现字符串和数值相加的异常
2)在进行endcoding,防止后续字节流转换字符流计算问题,提速 当设置了一个key的value为int时,就会标记这个value为int,下次调用incr等计算时就直接判断encoding,就不需要转码,而是判断类型如果不合适计算就报错了,直接进入计算,这也就是redis快的一个原因,跳过了一个转码过程
③:所以在多人客户端连接一个redis时,客户端之间要沟通好编码 -
一个字节8个二进制位
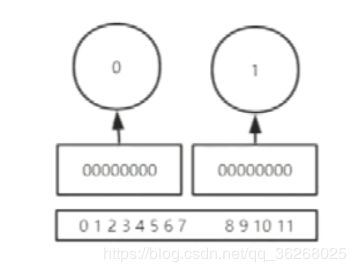
中间两个长方形代表两个字节,里面的0代表位,上面圈代表一个字节的一个索引,下面的长方形中的数字代表二进制位的索引,在Redis中二进制位也有索引,虽然字节是割裂的但是二进制位的索引是连续的。 -
bitMap类型(属于String类型中,也是8、String中的③:)
①:setbit key value 设置key的值的二进制位偏移量为offset的值为value(在二进制中值只能填0或者1) 直接连接下面11、项bitmap来解释 (例:setbit k1 1 1 代表k1的二进制位的1偏移量的值改为1 此时strlen k1 = 1 因为目前两个二进制位,8个二进制位才为1字节,strlen取的是字节长度 get k1 = @ 因为1偏移量也就是1索引位置被改成了1,所以二进制位为01,而01在ASCII码中为@)
②:man ascii 查询ASCII码表
③:bitpos key 在key的value的start到end索引的字节之中,寻找二进制位bit的第一个索引
④:bitcount key 在key的value的start到end索引的字节之中的二进制位中,寻找1出现的次数(只能专门搜索1出现的次数)
⑤:0100 0001 = A 0100 0010 = B 1)二进制位操作: 与:有0则0,全1为1 或:有1则1,全0为0
⑥:bitop newKey key1 key2 对key1和key2的值进行二进制的operate操作,结果存入newKey的值 例如:k1存的为01000001=A,k2存的为01000010=B, 则:bitop and k3 k1 k2 get k3 = 01000000 = @
⑦:bitmap的重要性: 场景:
1)需求:用户系统,统计用户的登陆天数且窗口随机。
实现:若是使用关系型数据库,需要一张用户登录表,登陆一次产生一条记录,表中至少一个存储用户数据的外键字段(保守说4个字节需要),还需要一个登录日期字段(保守四个字节),这就需要四个字节来存储一条登录数据,在大数据情况下查询成本高,一年用户天天登录需要8365字节存储
优化:使用redis数据,用每个二进制位表示一天,一个用户仅需365/8的字节存储登陆天数,setbit allen 364 1,设置allen这个人第365天登录了,需求中的窗口随机代表,突然老板说想看最近这两周半个月登录情况(随机什么时间的登录情况就叫窗口随机),因为一个二进制位为一天,只需数出最后十五天的二进制位为1的数量,bitcount allen -2 -1 = 1,因为这里的-2,-1都是字节的索引位,-1是倒数第一个,-2是倒数第二个,也就是28=16二进制位=16天的为1的二进制位数量,也就是最近十六天登陆天数。此时的二进制位代表的是登陆的天数,横向排列。
2)需求:商城618活动,这一天登陆送礼物,每人唯一,大库备货多少礼物,假设京东一共2亿用户账号
常识:用户分为僵尸用户、冷热用户/忠诚用户
实现:活跃用户统计,实际上有多少用户,随机窗口,统计1号2号3号用户登录数量,去重。
优化:redis。
比如第一天:setbit 20190101 1 1,20190101后面的第一个1事先做好一个映射到那个用户,也就是说1代表allen或者谁,2代表谁…,上面表示20190101这天,1号(约定他就是allen)登陆了
第二天:setbit 20190102 1 1, setbit 20190102 7 1,20190102这天1号又登陆了,7号(约定是谁)也登陆了
以此类推。最后数出这两天活跃用户:bitop or destkey 20190101 20190102 ,20190101和20190102的二进制位进行逻辑或运算(有1为1),存入destkey中。
bitcount destkey 0 -1 = 2 ,查询从头到最后一个的1的数量为2,这就是这两天活跃用户(这是因为数据少所以写0 -1,具体可以根据需求缩小范围)。
这个需求的优化跟第一个相比把代表天数的二进制位旋转了90度,竖向排列,此时每个key(也就是每行)代表的是这一天所有登陆的用户,然后对需要的天数的key的value进行逻辑运算压缩到一条value中,最后相同位置的用户的1都被压缩为1,最终的destkey的value的1的数量就是活跃用户的数量。
以上两个场景总结:
映射可以是用户表的id
第一个二进制矩阵:
天数: 12345678
用户:allen 01010101
用户: json 01011111
第二个二进制矩阵:
用户: 12345678(粗略表示,用户1-8)
20190101日期: 01000001
20190102日期: 11010101 -
字符集一般是ascii,其他的叫扩展字符集(其它字符集不再对ascii重新编码),在ascii中二进制位第一个必须是0,根据剩余七个的不同来代表不同字符(一个字节,8个二进制位时)
-
redis在对一个key的value改变长度后会把长度存在key中一份,以后查询长度直接返回,这个地方也是redis快的一点
-
List类型(插入、弹出元素有序)
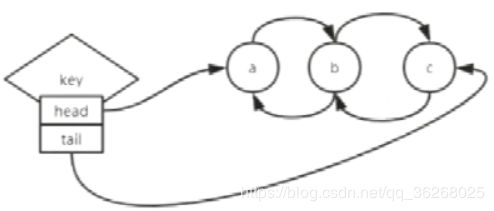
key有head(头)、tail(尾)两个指针,head可以迅速定位到list(链表)的第一个元素,tail可以到最后一个元素,图中abc是双向无环链表(双向指的是来回皆可,无环指的是不能从a直接到c形成一个环)
lpush key 往key的value中加入一个或多个元素(因为是L开头的命令,所以是从左往右依次防止),,上述图片放入后为 f e d c b a,因为先推进去的a然后推b,以此类推。
rpush key 往key的value中加入一个或多个元素(因为是R开头的命令,所以是从右往左依次防止)
lpop key 弹出key中的value的左侧第一个元素(弹出来后元value就没有这个被弹出的元素了,所以再执行一次弹出的是未被弹出状态的第二个元素也是当前状态的第一个元素)
rpop key 弹出key中的value的右侧第一个元素(弹出来后元value就没有这个被弹出的元素了,所以再执行一次弹出的是未被弹出状态的第二个元素也是当前状态的第一个元素)
由以上得出,同进同出,同向命令,类似java中的栈;
反向命令,类似java中的队列。 所以其实很多命令不需要在java的api中进行
lrange key 取出key的value的start索引到end索引中的元素(这里的L开头不是left的意思,就是List的L,无意义)
lindex key 取出key的index索引处的元素
lset key 将key的index索引处元素改为value
由以上得出,对索引操作,类似java中的数组。
lrem key将key的value元素移除(具体移除需看index_count的值的正负或0。
index_count>0时移除从左【前】往右【后】index_count个value元素;
index_count<0时移除从右【后】往左【前】index_count个value元素)
linsert key在key的oldValue的前面或后面插入一个newValue元素(如果有两个oldValue,只能在第一个oldValue的对应位置插入)
blpop key 阻塞的弹出key的value(后面的timeout指的是阻塞时间。填0则为一直阻塞)
如果有三个客户端都连接了6379端口的redis,如果redis当前还没有ooxx,第一个客户端blpop ooxx 0,取不出ooxx的value,阻塞住,第二个客户端blpop ooxx 0,同样阻塞住,第三个客户端lpush ooxx hello,压入一个hello到ooxx,切换回第一个客户端发现已经通畅并取出hello,而第二个依然还在阻塞,第三个客户端再次lpush ooxx world ,压入world到ooxx,此时第二个客户端才通畅取出world。
由以上得出,list也可以是阻塞的,单播队列,阻塞队列,谁先阻塞的谁先取到先到的值,也体现redis在处理数据方面的单线程。
ltrim key 删除key的start的左面的元素和end的右面的元素(也就是Start和End的两端以外的所有元素) -
hash类型(key-value,这个hash指的是key库的value的类型是hash,也就是value里面有key-value格式)
①:hset key 将key中设置一个key:value的值(这就是hash类型) ②:mset key 批量设置key:value
③:hget key 取出key的key1的value
④:hmget key 批量取出
⑤:hkeys key 取出key的所有key
⑥:hvalues key 取出key的所有value
⑦:hgetall key 取出Key的所有key,value
⑧:hincrbyfloat key 对key的key对应的value加v(数值计算,减法的话v写负数即可) -
set类型(插入、弹出元素无序,去重)
①:sadd key value1 valu2 value2 批量插入value1 value2 value3到key中
②:smembers key 取出key中所有value
③:srem key value1 value2 将value1和value2从key中移除
④:sinter key1 key2 … 做key1,key2…集合之间的交集(共同元素)返回出来
⑤:sinterstore key1 k2 k3 在k2和k3之间做交集,结果存入key1 ⑥:sunion key1 key2 在key1和key2之间做并集(总元素)返回出来
⑦:sdiff key1 key2 在key1和key2之间做差集(不同元素)返回出来【此方法有左差,右差的方向之分,谁在第一个就返回出第一个集合之内与其他元素不同的所有元素】
⑧:srandmembers key count若为正数,取出一个去重的结果集(内容是key里面的随机count个,不能重复抽到),一定是count个,不能超过已有集合;若为负数,取出一个可能带重复的结果集(内容是key里面的随机count个,可以重复抽到),一定满足count的数量;若为0,则不返回值。(这就是随机事件)
随机事件应用场景:
抽奖:10个奖品,用户可能小于或大于10,中奖人是否可以重复(可以重复用负数,不能重复用正数;即便用户小于10,可以重复,只用redis不用代码可能会出现有的人一次没有抽到)。
⑨:spop key 在key中抽取弹出一个value(为什么说抽取因为set是无序的),并在key中去掉这个value -
Zset(或Sorted Set类型)(默认是左小右大的物理摆放方式,不随命令而改变方向,以下的排序值实际上就是值)
1、用法
①:zadd key value1 value2 … … 往key中添加对应排序值(score1 …)的value(value1 …)
②:zrange key [withscores] 取出key中start到end索引位的所有value(从低到高排序过的,若加入withscores,则返回值也体现出各个value的排序值)
③:zrangebyscore key 取出key中排序值从startScore到endScore的所有value(从低到高排序过的)
④:zrevrange key [withscores] 取出key中start到end索引位的所有value(从高到低排序之后的反向start到end位value)
反向一般在z后面加个rev,因为物理内存中左小右大不随命令改变方向,所以加rev时会将写的正向索引翻译成逆向索引开始执行,所以内容是整个翻个改变方向的。
⑤:zscore key value 取出value的排序值
⑥:zrank key value 取出value的排名
⑦:zincrby key value 对key中value的排序值增加incrValue
2、集合操作(权重/聚合指令)
①并集:zunionstorekey1 key2 … [weights key1M key2M …] [aggregate max] 对key1和key2中的元素进行合并操作,对排序值进行一定操作(默认是不同元素直接放入,相同元素值相加),结果放入disKey当中(
1:不加所有[]内容的话若有重复元素,不同元素直接放入,两个集合重复元素的排序值相加;
2:加入[weights]内容,key1M集合所有元素排序值×key1M,key2M集合所有元素排序值×key2M …,然后相同元素的排序值相加,不同元素直接放入,结果存入disKey
3:加入[aggregate]内容,若有相同元素,取最大的那个值,不同元素直接放入,结果放入disKey当中)
②交集:
3、面试:
问:排序是怎么实现的;增删改查的速度
答:因为skip list(跳跃表、也叫平衡树)结构(数据少的时候不需要,这种结构在大数据下增删改查的平均值最稳定)。
解释:
①:插入逻辑原理:,正常链表只有最下面那一行3 7 22 45 (例子假设),每个元素都只有两个一前一后指针,不能跨越去看,在skip list结构里面,上面会多几层,也就是多一个向上的指针,若上几层不一定会有自己位置的元素,若没有元素则指向的下一个,若此层只有自己,则指向nil(redis中的空),此时有个11要插入,先跟最上面一行的头比较,后面到nil发现没有元素,下降一行去比较22,发现小,在22前面半个处下降,最后比较7发现大,找到了自己应该所在位置,把7向右到22的指针去掉,自己加上到7的,22向左到7的指针去掉,加入自己的位置的指针,至于上面的几个层,每个元素插入随机造层,上面几个层的指针修改需要11先到7发现7不能到上面层,再往前到3,再上去修改指针地址,例如11随机造了3层,则效果如下:
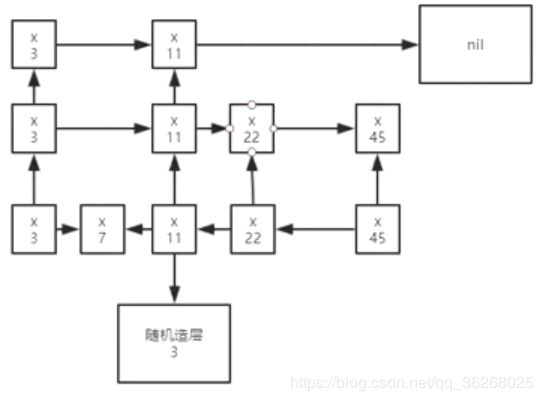
②:修改值原理:
如上的例子,想把22修改为8,实际上是将22元素的所有层和自己全部删除,两侧元素指针重新排列,然后修改为对应值再重新进行一次①中的插入过程。
第一次写博客见谅排版