MFS利用pacemaker+corosync+iscsi实现高可用
- 上一篇文章介绍了
MFS的安装和配置,由于MFS自身的Mfslogger本身的的不可靠性,这里的高可用是对于单节点mfs master来进行配置的,mfs master处理用户的挂载请求,并且分发数据,很容易成为节点的故障所在; - 这里来配置
MFS+pacemaker+corosync+iscsi集群的高可用性 首先列出上次服务的规划
Client: server6.com 172.25.23.6
Master: server7.com 172.25.23.7
Metalogger: server8.com 172.25.23.8[这个废弃]
Chunkserver: server9.com 172.25.23.9 sever10.com 172.25.23.10在上次规划上面进行如下的修改
Client: server6.com 172.25.23.6
Master: server7.com 172.25.23.7
Metalogger: server8.com 172.25.23.8[这个废弃]
Chunkserver: server9.com 172.25.23.9 sever10.com 172.25.23.10
iscsi starget: server10.com
iscsi initiator: server6.com server7.com
pacemaker + corosync配置在server6.com server7.com上面,并且提供VIP首先配置
ISCSI starget给节点server6.com server7.com来使用
ISCSI详细的配置过程参考
[root@server10 ~]# fdisk /dev/vdc
[root@server10 ~]# partx /dev/vdc
[root@server10 ~]# mkfs.ext4 /dev/vdc1
[root@server10 ~]# vim /etc/tgt/targets.conf
添加
.2018-03.com.server10:testscsi>
backing-store /srv/iscsi/disk1.img
backing-store /dev/vdb1
backing-store /dev/server/iscsi
initiator-address 172.25.23.0/24
incominguser westos westos
write-cache off
[root@server10 ~]# /etc/init.d/tgtd start
[root@server10 ~]# chkconfig tgtd on- 然后配置
iscsi initiator两台服务器
[root@server6 mnt]# vim /etc/iscsi/iscsid.conf
更改或者添加:
node.session.auth.username = westos
node.session.auth.password = westos
discovery.sendtargets.auth.username = westos
discovery.sendtargets.auth.password = westos
[root@server6 mnt]# scp /etc/iscsi/iscsid.conf 172.25.23.7:/etc/iscsi/
iscsid.conf 100% 11KB 11.3KB/s 00:00 - 在另一个节点上面下载同样的软件,因为这里将配置文件复制给另一个节点,所以下载服务之后可以直接启动
- 两个结点上面启动服务,并且检测
target查看结果是否正常
[root@server6 mnt]# /etc/init.d/iscsi start
[root@server6 mnt]# iscsiadm -m discovery -t sendtargets -p 172.25.23.10
Starting iscsid: [ OK ]
172.25.23.10:3260,1 iqn.2018-03.com.server10:testscsi
[root@server7 x86_64]# /etc/init.d/iscsi start
[root@server7 x86_64]# iscsiadm -m discovery -t sendtargets -p 172.25.23.10
Starting iscsid: [ OK ]
172.25.23.10:3260,1 iqn.2018-03.com.server10:testscsi- 然后进行登陆操作
[root@server6 mnt]# iscsiadm -m node -T iqn.2018-03.com.server10:testscsi --login
[root@server7 mnt]# iscsiadm -m node -T iqn.2018-03.com.server10:testscsi --login
得到了新的设备
Disk /dev/sda: 5368 MB, 5368398336 bytes
166 heads, 62 sectors/track, 1018 cylinders
Units = cylinders of 10292 * 512 = 5269504 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x00000000
对这块设备进行格式化
[root@server6 mnt]# mkfs.ext4 /dev/sda- 首先需要挂载这块硬盘将重要的信息复制到这块硬盘里面
- 这个过程就是在停止
mfsmaster之后,然后将master产生的所有文件复制到/dev/sda1文件里面,然后将这个分区挂载到mfs master的目录,重新启动服务;
[root@server7 x86_64]# mount /dev/sda /mnt/
[root@server7 mnt]# mfsmaster stop
[root@server7 mnt]# cp /var/lib/mfs/* .
[root@server7 mnt]# ls
changelog.10.mfs changelog.4.mfs changelog.9.mfs metadata.mfs.empty
changelog.11.mfs changelog.5.mfs lost+found stats.mfs
changelog.15.mfs changelog.6.mfs metadata.mfs
changelog.16.mfs changelog.7.mfs metadata.mfs.back.1
[root@server7 mnt]# chown mfs.mfs -R /mnt/
[root@server7 /]# mount /dev/sda1 /var/lib/mfs/- 提供可以使用的服务启动脚本
[root@server7 init.d]# cat mfsd
# cat /etc/init.d/mfs
#!/bin/bash
#
# Init file for the MooseFS master service
#
# chkconfig: - 92 84
#
# description: MooseFS master
#
# processname: mfsmaster
# Source function library.
# Source networking configuration.
. /etc/init.d/functions
. /etc/sysconfig/network
# Source initialization configuration.
# Check that networking is up.
[ "${NETWORKING}" == "no" ] && exit 0
[ -x "/usr/sbin/mfsmaster" ] || exit 1
[ -r "/etc/mfs/mfsmaster.cfg" ] || exit 1
[ -r "/etc/mfs/mfsexports.cfg" ] || exit 1
RETVAL=0
prog="mfsmaster"
datadir="/var/lib/mfs"
mfsbin="/usr/sbin/mfsmaster"
start () {
echo -n $"Starting $prog: "
$mfsbin >/dev/null 2>&1
if [ $? -ne 0 ];then
$mfsbin -a >/dev/null 2>&1
fi
RETVAL=$?
echo
return $RETVAL
}
stop () {
echo -n $"Stopping $prog: "
$mfsbin stop >/dev/null 2>&1 || killall -9 $prog #>/dev/null 2>&1
RETVAL=$?
echo
return $RETVAL
}
restart () {
stop
start
}
reload () {
echo -n $"reload $prog: "
$mfsbin reload >/dev/null 2>&1
RETVAL=$?
echo
return $RETVAL
}
restore () {
echo -n $"restore $prog: "
$mfsrestore -a >/dev/null 2>&1
RETVAL=$?
echo
return $RETVAL
}
case "$1" in
start)
start
;;
stop)
stop
;;
restart)
restart
;;
reload)
reload
;;
restore)
restore
;;
status)
status $prog
RETVAL=$?;;
*)
echo $"Usage: $0 {start|stop|restart|reload|restore|status}"
RETVAL=1
esac
exit $RETVAL- 测试这个脚本的正常功能然后将这个脚本复制到另一个管理节点上面
[root@server7 init.d]# /etc/init.d/mfsd start
Starting mfsmaster:
[root@server7 init.d]# /etc/init.d/mfsd status
mfsmaster (pid 1636) is running...
[root@server7 init.d]# /etc/init.d/mfsd stop
Stopping mfsmaster: - 将这个文件复制到另一个节点上面
[root@server7 init.d]# scp mfsd 172.25.23.6:/etc/init.d/
mfsd 100% 1363 1.3KB/s 00:00- 接下来需要在
server6.com上面配置mfs master服务
[root@server6 ~]# yum install moosefs-master-3.0.80-1.x86_64.rpm libpcap-* -y- 停止
server7.com上面的mfs master服务,卸载工作目录/var/lib/mfs的挂载然后在server1.com上面进行启动查看是否正常
[root@server6 ~]# iscsiadm -m node -T iqn.2018-03.com.server10:testscsi --login
[root@server6 ~]# mount /dev/sda1 /var/lib/mfs/
[root@server6 ~]# /etc/init.d/mfsd start
[root@server6 ~]# /etc/init.d/mfsd status- 这里查看两者
mfs用户的id,如果不相同,就更改成一样的
[root@server6 ~]# id mfs
uid=498(mfs) gid=499(mfs) groups=499(mfs)
[root@server7 mnt]# id mfs
uid=498(mfs) gid=499(mfs) groups=499(mfs)- 接下来安装
pacemaker
[root@server6 ~]# yum install pacemaker -y
[root@server6 ~]# yum install pssh-2.3.1-2.1.x86_64.rpm crmsh-1.2.6-0.rc2.2.1.x86_64.rpm -y
[root@server7 ~]# yum install pacemaker -y
[root@server7 ~]# yum install crmsh-1.2.6-0.rc2.2.1.x86_64.rpm pssh-2.3.1-2.1.x86_64.rpm -y- 接下来配置
pacemaker
totem {
version: 2
secauth: off
threads: 0
interface {
ringnumber: 0
bindnetaddr: 172.25.23.0
mcastaddr: 226.94.1.10
mcastport: 5405
ttl: 1
}
}
service {
name: pacemaker
ver: 0
}- 然后将这个配置文件复制给另一个节点
[root@server7 corosync]# scp corosync.conf 172.25.23.6:/etc/corosync/
corosync.conf 100% 485 0.5KB/s 00:00 - 接下来启动
corosync,添加fence设备
[root@server6 ~]# /etc/init.d/corosync start
[root@server7 corosync]# /etc/init.d/corosync start- 首先确认真机的
fence_virtd.service服务是启动的;
[root@my Desktop]# systemctl status fence_virtd.service
● fence_virtd.service - Fence-Virt system host daemon
Loaded: loaded (/usr/lib/systemd/system/fence_virtd.service; disabled; vendor preset: disabled)
Active: active (running) since 四 2018-03-22 16:31:26 CST; 4h 4min ago
Process: 21110 ExecStart=/usr/sbin/fence_virtd $FENCE_VIRTD_ARGS (code=exited, status=0/SUCCESS)
Main PID: 21111 (fence_virtd)
CGroup: /system.slice/fence_virtd.service
└─21111 /usr/sbin/fence_virtd -w- 将真机的
fence_xvm.key给每一个corosync的节点
[root@my Desktop]# scp /etc/cluster/fence_xvm.key 172.25.23.6:/etc/cluster/
fence_xvm.key 100% 128 0.1KB/s 00:00
[root@my Desktop]# scp /etc/cluster/fence_xvm.key 172.25.23.7:/etc/cluster/
fence_xvm.key 100% 128 0.1KB/s 00:00 - 对于
fence设备这里使用fence_xvm,所以首先查看是否有这个设备
[root@server7 corosync]# stonith_admin -I | grep xvm
46 devices found
fence_xvm
[root@server6 ~]# stonith_admin -I | grep xvm
46 devices found
fence_xvm- 如果不存在,需要安装
fence_xvm; - 接下来配置
fence设备
[root@server7 corosync]# crm
crm(live)# configure
crm(live)configure# show
node server6.com
node server7.com
property $id="cib-bootstrap-options" \
dc-version="1.1.10-14.el6-368c726" \
cluster-infrastructure="classic openais (with plugin)" \
expected-quorum-votes="2"
crm(live)configure# property no-quorum-policy=ignore
crm(live)configure# commit - 首先添加
fence设备
[root@server7 corosync]# crm
crm(live)# configure
crm(live)configure# show
node server6.com
node server7.com
crm(live)configure# primitive vmfence stonith:fence_xvm params pcmk_host_map="server7.com:rhel6.5-6;server6.com:rhel6.5-5" op monitor interval=60s
crm(live)configure# commit
- 接下来需要在两个节点上面创建目录,并且用于保存
fence秘钥信息
[root@server6 corosync]# mkdir /etc/cluster
[root@server7 corosync]# mkdir /etc/cluster
[root@my Desktop]# scp /etc/cluster/fence_xvm.key 172.25.23.6:/etc/cluster/fence_xvm.key
fence_xvm.key 100% 128 0.1KB/s 00:00
[root@my Desktop]# scp /etc/cluster/fence_xvm.key 172.25.23.7:/etc/cluster/fence_xvm.key
fence_xvm.key - 继续配置资源
crm(live)configure# primitive vip ocf:heartbeat:IPaddr2 params ip=172.25.23.100 cidr_netmask=32 op monitor interval=10s
crm(live)configure# commit - 查看资源的运行状态
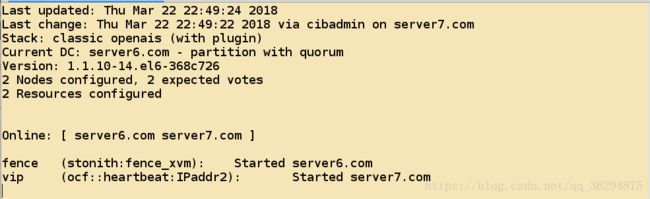
- 停止关于
mfs的服务,并且修改master的解析信息
[root@server9 ~]# mfschunkserver stop
sending SIGTERM to lock owner (pid:1104)
waiting for termination terminated
[root@server10 ~]# mfschunkserver stop
sending SIGTERM to lock owner (pid:1103)
waiting for termination terminated
[root@server6 ~]# vim /etc/hosts
172.25.23.100 mfsmaster- 将修改的解析文件复制给每一个节点
[root@server6 ~]# for I in {7,8,9,10};do echo server$I.com; scp /etc/hosts 172.25.23.$I:/etc/hosts ; done
server7.com
hosts 100% 929 0.9KB/s 00:00
server8.com
ssh: connect to host 172.25.23.8 port 22: No route to host
lost connection
server9.com
hosts 100% 929 0.9KB/s 00:00
server10.com
hosts 100% 929 0.9KB/s 00:00 - 再次添加一个资源,也就是文件系统资源
crm(live)configure# primitive mfsdata ocf:heartbeat:Filesystem params device=/dev/sda1 fstype=ext4 directory=/var/lib/mfs op monitor interval=30s- 添加
lsb风格的管理脚本
crm(live)configure# primitive mfsmaster lsb:mfsd op monitor interval=30s- 将这几个资源定义为组资源
crm(live)configure# group mfsgroup vip mfsdata mfsmaster - 之前这些资源运行在不同的节点上面

- 之后定义为组的资源,就运行在同一个节点上面
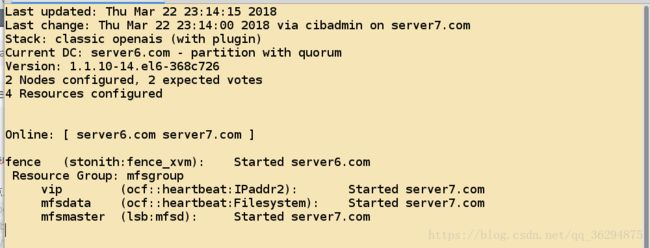
- 接下来启动集群的服务
[root@server9 ~]# mfschunkserver
open files limit has been set to: 16384
working directory: /var/lib/mfs
lockfile created and locked
setting glibc malloc arena max to 8
setting glibc malloc arena test to 1
initializing mfschunkserver modules ...
hdd space manager: path to scan: /mnt/chunk1/
hdd space manager: start background hdd scanning (searching for available chunks)
main server module: listen on *:9422
stats file has been loaded
mfschunkserver daemon initialized properly
[root@server10 ~]# mfschunkserver
open files limit has been set to: 16384
working directory: /var/lib/mfs
lockfile created and locked
setting glibc malloc arena max to 8
setting glibc malloc arena test to 1
initializing mfschunkserver modules ...
hdd space manager: path to scan: /mnt/chunk2/
hdd space manager: start background hdd scanning (searching for available chunks)
main server module: listen on *:9422
stats file has been loaded
mfschunkserver daemon initialized properly- 这里可以看到关于组资源的信息
[root@server7 corosync]# ip addr show
1: lo: mtu 16436 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 52:54:00:0f:3e:c9 brd ff:ff:ff:ff:ff:ff
inet 172.25.23.7/24 brd 172.25.23.255 scope global eth0
inet 172.25.23.100/32 brd 172.25.23.255 scope global eth0
inet6 fe80::5054:ff:fe0f:3ec9/64 scope link
valid_lft forever preferred_lft forever
[root@server7 corosync]# df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/mapper/VolGroup-lv_root 18171208 1115856 16133268 7% /
tmpfs 251136 21936 229200 9% /dev/shm
/dev/vda1 495844 33448 436796 8% /boot
/dev/sda1 5156292 144964 4749400 3% /var/lib/mfs - 这里是
mfs client里面挂载的文件的信息
[root@server6 dir1]# ls
bigfile passwd
[root@server6 dir1]# pwd
/mnt/mfs/dir1
[root@server6 dir1]#
元数据挂载的信息
[root@server6 mfsmeta]# pwd
/mnt/mfsmeta- 这样一个
pacemaker + corosync + iscsi组成的提供了fence + VIP + filesystem + lsb的MFS高可用集群就配置完成了;