Web和HTTP《计算机网络——自顶向下方法(James F. Kurose, Keith W. Rose)》
1. HTTP概况
(1)超文本传输协议(HyperText Transfer Protocol,HTTP)是web的应用层协议。有两个程序组成:客户程序+服务器程序。HTTP默认端口:80
(2)web页面=多个对象组成(对象只是一个文件,如一个html文件,一个图形,一个java小程序或一个视频)。每个对象通过一个对应的URL寻址。
(3)URL有两部分组成:主机名+对象的路径名。
(4)HTTP使用TCP作为它的运输协议:(应用层协议HTTP无需担心数据丢失和错误恢复,那是TCP及协议栈较低层协议的工作)

(5)HTTP是无状态协议(stateless protocol),不保存关于客户的任何信息。
2. 非持续连接(non-persistent connection)和持续连接(persistent connection)
使用持续连接或非持续连接是由应用层决定的(HTTP默认使用的是持续连接);
而解析Web页面是由浏览器决定的,HTTP规范仅定义了客户程序与服务器程序的通信协议。
(1)采用非持续连接的HTTP
①每个TCP连接只传输一个请求报文和一个响应报文。
②服务器想客户传输一个Web页面的步骤:
客户进程发起到服务器的TCP连接(www.someschool.com)——>客户向服务器发送请求报文(包含路径名/someFile/home.index)——>服务器发送响应报文——>服务器通知客户断开连接——>客户接收完响应报文后,断开连接——>客户检查HTML文件,对每个应用重复上述步骤.
③从客户请求文件起到该客户收到整个文件止所花费的时间(设计TCP的三次握手):2RTT+服务器传输文件的时间
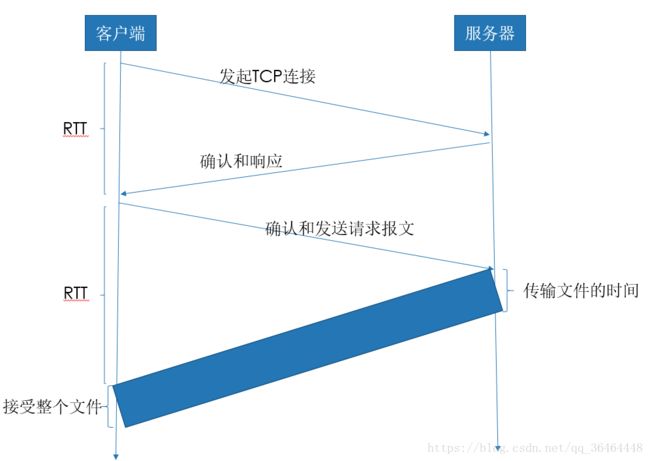
(2)采用持续连接的HTTP
①非持续连接的缺点:首先,要为每个请求的对象建立一个连接,对于每个连接,客户和服务器中都要分配TCP缓冲区和保持TCP变量,给服务器带来严重负担;第二,每个对象都要遭受两倍RTT时延,一个RTT用来建立连接,一个RTT用来请求和接受对象。
②持续连接:服务器在发送响应之后保持该TCP连接打开。因此,位于同一台服务器的多个Web页面都可以在单个TCP上进行传输。请求可以一个接一个地发而不必等待未决请求的回答(流水线)。
3. HTTP报文格式
(1)HTTP请求报文

一个请求报文的通用格式:
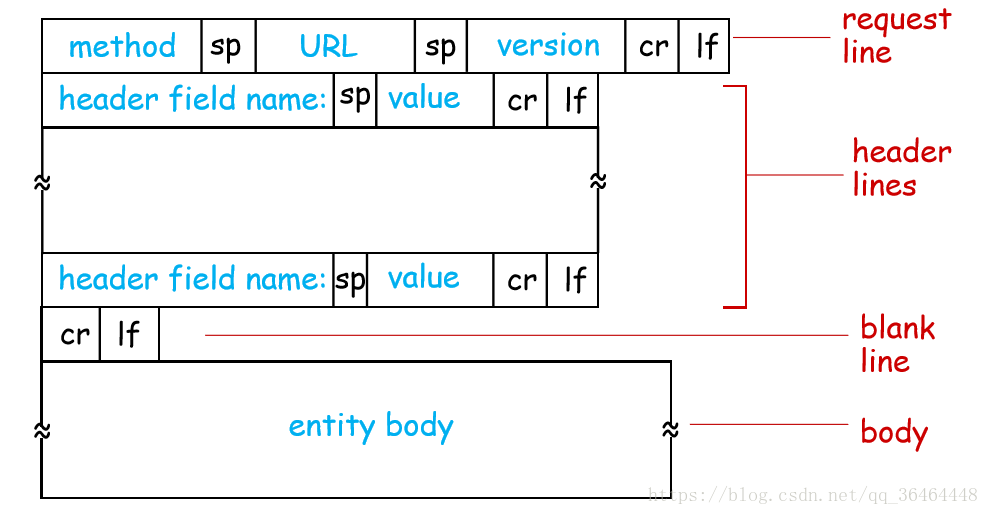
常用的方法字段有:GET、POST、HEAD、PUT、DELETE。
使用GET时,body字段为空;
使用POST时,body中包含用户要提交的值。(当然,GET方法也可以通过将样提交的值包含在URL字段中进行提交);
使用HEAD时,服务器会用HEAD进行响应,但不返回对象(通常用来调试跟踪);
使用PUT允许用户上传对象到服务器上。
(2)HTTP响应报文

Content-Type首部行指示了实体体中对象的类型。下面是响应报文的通用格式:
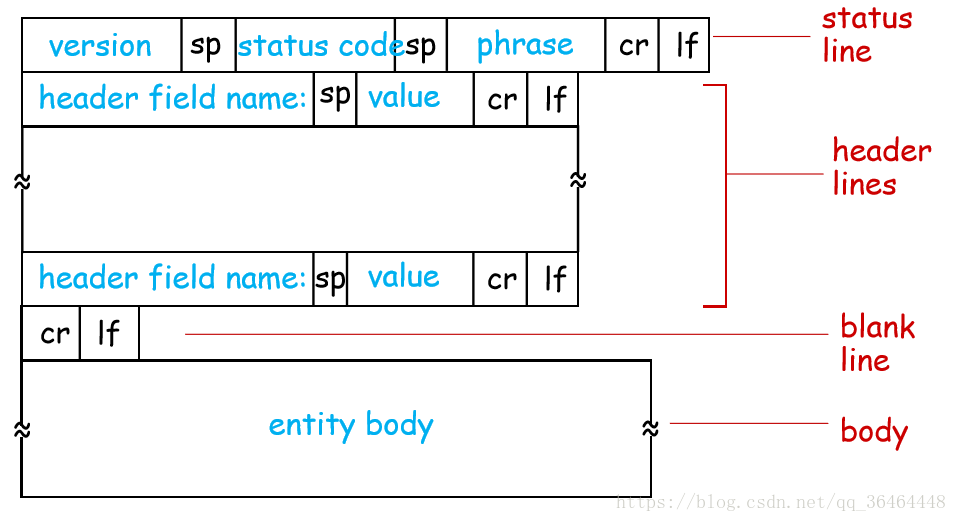
常见的状态码:
200 OK
400 Bad Request
404 Not Found
505 HTTP Version Not Supported
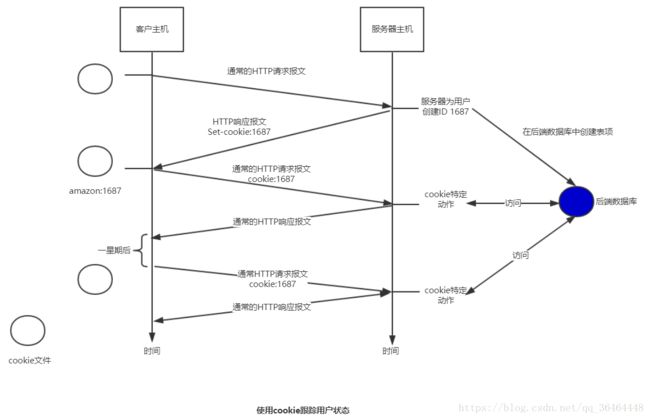
4. 用户与服务器的交互: cookie
HTTP服务器是无状态的,为了允许站点对用户进行跟踪,HTTP使用了cookie。
cookie技术由4个组件:
a. 在HTTP响应报文中的一个cookie首部行
b. 在HTTP请求报文中的一个cookie首部行;
c. 在用户端系统中保留一个cookie文件,并由用户浏览器管理;
d. 位于web站点的一个后端浏览器
下面通过一个典型的例子看cookie工作过程:
5. Web缓存(Web cache)
(1)Web缓存也叫代理服务器(proxy server),它是能够代替初始web服务器来满足HTTP请求的一种网络实体。它在村粗空间中保存最近请求过的对象的副本。通过配置用户的浏览器,可以使得用户的所用HTTP请求首先指向Web缓存器。
通俗地说,Web缓存器在客户和初始服务器之间充当传话筒。
(2)Web缓存器存在的原因:
a. 可以大大减小对客户请求的响应时间
b. 能够大大减少一个机构的接入链路到因特网的通信量
c. 能够从整体上大大降低因特网上的web流量
(3)Web缓存器如何确定其存储的对象是最新的?
条件get方法(condition GET):GET方法+“If-Modified-Since”。Web缓存器通过向服务器发送condition GET 确认对象的Last-Modified是否与本地缓存的对象副本相同。如果相同,服务器返回一个空的304 Not Modified报文,如果不同,服务器返回包含最新对象的报文。