那些你曾错过的JAVA题(二)


6
线程安全的map在JDK 1.5及其更高版本环境 有哪几种方法可以实现?
A.Map map = new HashMap()
B.Map map = new TreeMap()
C.Map map = new ConcurrentHashMap();
D.Map map = Collections.synchronizedMap(new HashMap())
解析:
HashMap,TreeMap 未进行同步考虑,是线程不安全的,所以 A,B排除。
HashTable 和 ConcurrentHashMap 都是线程安全的。区别在于他们对加锁的范围不同,HashTable 对整张Hash表进行加锁,而ConcurrentHashMap将Hash表分为16桶(segment),每次只对需要的桶进行加锁。
Collections 类提供了synchronizedXxx()方法,可以将指定的集合包装成线程同步的集合。比如,
List list = Collections.synchronizedList(new ArrayList());
Set set = Collections.synchronizedSet(new HashSet());
答案:C,D
7
下面有关JVM内存,说法错误的是?
A.程序计数器是一个比较小的内存区域,用于指示当前线程所执行的字节码执行到了第几行,是线程隔离的
B.虚拟机栈描述的是Java方法执行的内存模型,用于存储局部变量,操作数栈,动态链接,方法出口等信息,是线程隔离的
C.方法区用于存储JVM加载的类信息、常量、静态变量、以及编译器编译后的代码等数据,是线程隔离的
D.原则上讲,所有的对象都在堆区上分配内存,是线程之间共享的
解析:
JVM运行时,数据区包含:虚拟机栈,堆,方法区,本地方法栈,程序计数器,其中,堆和方法区是线程共享的,虚拟机栈和程序计数器是线程私有的
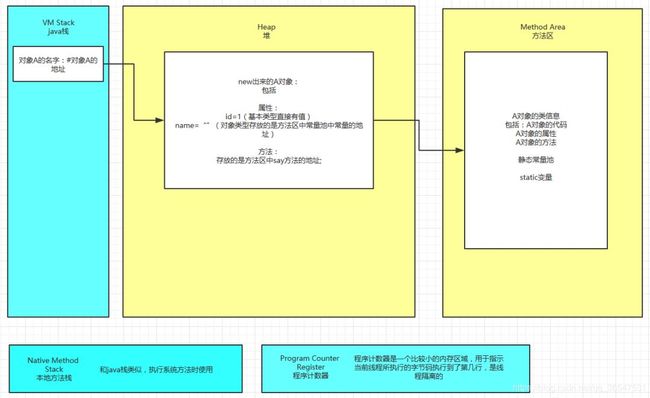
大多数 JVM 将内存区域划分为 Method Area(Non-Heap)(方法区) ,Heap(堆) , Program Counter Register(程序计数器) , VM Stack(虚拟机栈,也有翻译成JAVA 方法栈的),Native Method Stack ( 本地方法栈 ),
其中Method Area 和 Heap 是线程共享的 ,VM Stack,Native Method Stack 和Program Counter Register 是非线程共享的。为什么分为 线程共享和非线程共享的呢?请继续往下看。
首先我们熟悉一下一个一般性的 Java 程序的工作过程。一个 Java 源程序文件,会被编译为字节码文件(以 class 为扩展名),每个java程序都需要运行在自己的JVM上,然后告知 JVM 程序的运行入口,再被 JVM 通过字节码解释器加载运行。那么程序开始运行后,都是如何涉及到各内存区域的呢?
概括地说来,JVM初始运行的时候都会分配好 Method Area(方法区) 和Heap(堆) ,而JVM 每遇到一个线程,就为其分配一个 Program Counter Register(程序计数器) , VM Stack(虚拟机栈)和Native Method Stack (本地方法栈), 当线程终止时,三者(虚拟机栈,本地方法栈和程序计数器)所占用的内存空间也会被释放掉。这也是为什么我把内存区域分为线程共享和非线程共享的原因,非线程共享的那三个区域的生命周期与所属线程相同,而线程共享的区域与JAVA程序运行的生命周期相同,所以这也是系统垃圾回收的场所只发生在线程共享的区域(实际上对大部分虚拟机来说知发生在Heap上)的原因。(---解析来自牛客网网友)
答案:C
8
关于依赖注入,下列选项中说法错误的是()
A.依赖注入能够独立开发各组件,然后根据组件间关系进行组装
B.依赖注入使组件之间相互依赖,相互制约
C.依赖注入提供使用接口编程
D依赖注入指对象在使用时动态注入
解析:
B 依赖注入的动机就是减少组件之间的耦合度,使开发更为简洁
补充:
依赖注入和控制反转是同一概念:
依赖注入和控制反转是对同一件事情的不同描述,从某个方面讲,就是它们描述的角度不同。依赖注入是从应用程序的角度在描述,可以把依赖注入描述完整点:应用程序依赖容器创建并注入它所需要的外部资源;而控制反转是从容器的角度在描述,描述完整点:容器控制应用程序,由容器反向的向应用程序注入应用程序所需要的外部资源。
答案:B
9
有关hashMap跟hashTable的区别,说法正确的是?ABCD
A.HashMap和Hashtable都实现了Map接口
B.HashMap是非synchronized,而Hashtable是synchronized
C.HashTable使用Enumeration,HashMap使用Iterator
D.Hashtable直接使用对象的hashCode,HashMap重新计算hash值,而且用与代替求模
解析:
HashTable和HashMap区别
①继承不同。
public class Hashtable extends Dictionary implements Map
public class HashMap extends AbstractMap implements Map②Hashtable 中的方法是同步的,而HashMap中的方法在缺省情况下是非同步的。在多线程并发的环境下,可以直接使用Hashtable,但是要使用HashMap的话就要自己增加同步处理了。
③Hashtable中,key和value都不允许出现null值。
在HashMap中,null可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为null。当get()方法返回null值时,即可以表示 HashMap中没有该键,也可以表示该键所对应的值为null。因此,在HashMap中不能由get()方法来判断HashMap中是否存在某个键, 而应该用containsKey()方法来判断。
④两个遍历方式的内部实现上不同。Hashtable、HashMap都使用了 Iterator。而由于历史原因,Hashtable还使用了Enumeration的方式 。
⑤哈希值的使用不同,HashTable直接使用对象的hashCode。而HashMap重新计算hash值。
⑥Hashtable和HashMap它们两个内部实现方式的数组的初始大小和扩容的方式。HashTable中hash数组默认大小是11,增加的方式是 old*2+1。HashMap中hash数组的默认大小是16,而且一定是2的指数。
10
关于访问权限说法正确 的是 ? ( )
A.类定义前面可以修饰public,protected和private
B.内部类前面可以修饰public,protected和private
C.局部内部类前面可以修饰public,protected和private
D.以上说法都不正确
解析:对于外部类来说,只有两种修饰,public和默认(default),因为外部类放在包中,只有两种可能,包可见和包不可见。对于内部类来说,可以有所有的修饰,因为内部类放在外部类中,与成员变量的地位一致,所以有四种可能
一个努力中的公众号
如果觉得对你有用帮忙转发至朋友圈吧!

往期精彩回顾

JAVA易错题 | 那些你曾错过的JAVA题(一)
持续更新中...

关注我,你能变得更牛逼!
长按识别二维码关注

