准备
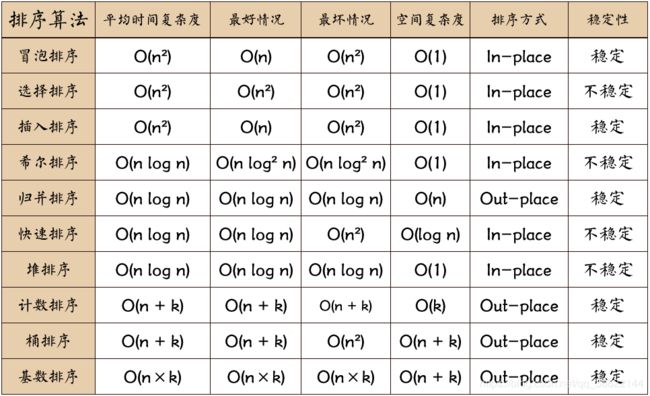
排序
1.排序算法的稳定性:a = b,a在b的前面,排序之后a任然在前,稳定排序,可能在后面为不稳定排序。
稳定排序算法:冒泡,简单插入排序,归并排序
不稳定排序:选择排序,快速排序,希尔排序
都属于内部排序,不要外存。
希尔排序
先将整个待排序的记录序列分割成为若干子序列分别进行直接插入排序,具体算法描述:
- 步骤1:选择一个增量序列t1,t2,…,tk,其中ti>tj,tk=1;
- 步骤2:按增量序列个数k,对序列进行k 趟排序;
- 步骤3:每趟排序,根据对应的增量ti,将待排序列分割成若干长度为m 的子序列,分别对各子表进行直接插入排序。仅增量因子为1 时,整个序列作为一个表来处理,表长度即为整个序列的长度。
归并排序
建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。归并排序是一种稳定的排序方法。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为2-路归并。
算法描述
- 步骤1:把长度为n的输入序列分成两个长度为n/2的子序列;
- 步骤2:对这两个子序列分别采用归并排序;
- 步骤3:将两个排序好的子序列合并成一个最终的排序序列。
数据库
1.存储过程:是一组SQL语句,用作访问数据库的函数。为了减少网络流量并提高性能,可使用存储过程。
2.索引:用于加速查询的性能。它可以更快地从表中检索数据。可以在一组列上创建索引。
3.事务,事务可看作是对数据库操作的基本执行单元,可能包含一个或者多个SQL语句。
ACID,
原子性:这些语句在执行时,要么都执行,要么都不执行;
一致性:从一个正确状态转换为另外一个正确状态;
隔离性:事务之间相互隔离;
持久性:事务对数据库的更改是永久的。
更新丢失:两个事务对某个数据进行操作,一个事务更改导致另一个事务的更改失效;
读脏数据:A改,B读,A回滚rollback,导致读出的数据是错误的,脏数据。
不可重复读:A读,B改,A再读导致两次读出的数不一致
幻读:A读,B增加一条记录,B再读,导致幻读
隔离的等级:
read uncommitted 解决数据丢失
read committed 解决读脏数据、数据丢失
repeatable read 解决不可重复读、读脏数据、数据丢失
serializable 都解决
4.数据库存储引擎
INNODB会支持一些关系数据库的高级功能,如事务功能和行级锁,MyISAM不支持。
MyISAM的性能更优,占用的存储空间少,所以,选择何种存储引擎,视具体应用而定。
如果你的应用程序一定要使用事务,毫无疑问你要选择INNODB引擎。不能够理解为MyISAM为小型应用的数据库引擎。
5.索引
B+树索引 HASH索引;
等值查询 哈希索引有优势,前提是键值是唯一的;
范围查询,模糊查询,排序不能够用哈希索引,无效。
聚集索引:字典通过拼音查询某个字,由于正文也是按照拼音a~z的顺序来的,索引和物理地址排列顺序一样。
非聚集索引:通过偏旁来查,同一个偏旁的字,物理地址和索引顺序不一致,逻辑与物理地址不对应。
6.锁 共享锁 排它锁 乐观锁 悲观锁
乐观锁,先操作再上锁,假象别人是不会对某个数据对象进行更改,提交时上锁,并比较当前version和数据库相同才提交,基于数据库版本。
悲观锁,先上锁再操作,认为别人会对该数据进行修改,上锁之后别的事务就不能够更改,
一般情况下,读多写少更适合用乐观锁,读少写多更适合用悲观锁。
悲观锁和乐观锁是数据库用来保证数据并发安全防止更新丢失的两种方法。
共享锁(S) 对某个数据上共享锁,别人也能够读这些数据,上读锁,不能够上写锁。
排他锁(X)分为,对某个数对象上X锁,则其他事物不能够对这个对象上任何读写锁,必须等改事务释放之后才行。二者都是行级锁。
死锁
但是使用锁会导致一种情况,2个事务永远在等待一块数据:
事务A 给 数据1 加上排他锁并且等待获取数据2
事务B 给 数据2 加上排他锁并且等待获取数据1
这叫死锁。
7.SQL语句的优化
优化insert语句:一次插入多值;
- 应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描;
- 应尽量避免在 where 子句中对字段进行null值判断,否则将导致引擎放弃使用索引而进行全表扫描;
- 优化嵌套查询:子查询可以被更有效率的连接(Join)替代;
- 很多时候用 exists 代替 in 是一个好的选择。
8.什么是存储过程?有哪些优缺点?
存储过程是事先经过编译并存储在数据库中的一段SQL语句的集合。进一步地说,存储过程是由一些T-SQL语句组成的代码块,这些T-SQL语句代码像一个方法一样实现一些功能(对单表或多表的增删改查),然后再给这个代码块取一个名字,在用到这个功能的时候调用他就行了。存储过程具有以下特点:
- 存储过程只在创建时进行编译,以后每次执行存储过程都不需再重新编译,而一般 SQL 语句每执行一次就编译一次,所以使用存储过程可提高数据库执行效率;
- 当SQL语句有变动时,可以只修改数据库中的存储过程而不必修改代码;
- 减少网络传输,在客户端调用一个存储过程当然比执行一串SQL传输的数据量要小;
- 通过存储过程能够使没有权限的用户在控制之下间接地存取数据库,从而确保数据的安全。
设计模式
创建型模式,行为型模式,构造型模式
单例模式:一个自身实例化的类,通过自身方法getInstance方法来实例化,两种单例模式,懒汉单例和饿汉单例,懒汉单例:先声明一个空对象,然后判断这个对象是否被实例化过没有,没有就在方法里面实例化,有就跳过,说明以前已经实例化过,然后返回。饿汉单例在类加载时就实例化,然后返回;
简单工厂模式:一个产品接口,多个实现该接口产品类(即为一类产品),一个工厂类实现多种产品对象的创建;产品:鼠标,键盘;工厂:联想,在一个工厂实现;
工厂方法模式:一个产品接口,多个实现该接口产品类,一个工厂接口,多个实现该工厂接口的具体工厂类,里面分别实现创建不同的产品对象;产品:鼠标,键盘,工厂:联想鼠标厂,联想键盘厂
抽象工厂模式:多个产品接口,每个接口有多个产品类,一个工厂接口,多个继承自该工厂接口的具体工厂类,里面可以实现多个产品对象的创建;产品1:联想鼠标,联想键盘,产品2:富士康鼠标,富士康键盘;工厂:联想厂,富士康厂,每个工厂里面都可以实现键盘和鼠标对象的创建;
抽象工厂模式通常适用于以下场景:
当需要创建的对象是一系列相互关联或相互依赖的产品族时,如电器工厂中的电视机、洗衣机、空调等。
系统中有多个产品族,但每次只使用其中的某一族产品。如有人只喜欢穿某一个品牌的衣服和鞋。
系统中提供了产品的类库,且所有产品的接口相同,客户端不依赖产品实例的创建细节和内部结构。
浏览器输入URL后发生什么?
总体分为以下几个过程:
1.输入地址
2.域名解析 DNS解析
3.TCP连接
4.发送HTTP请求
5.返回HTTP响应
6.浏览器解析渲染页面
7.断开连接
线程与进程
简而言之,进程是程序运行和资源分配的基本单位,一个程序至少有一个进程,一个进程至少有一个线程。进程在执行过程中拥有独立的内存单元,而多个线程共享内存资源,减少切换次数,从而效率更高。线程是进程的一个实体,是cpu调度和分派的基本单位,是比程序更小的能独立运行的基本单位。同一进程中的多个线程之间可以并发执行。
算法题
1.合并两个有序数组
输入:
nums1 = [1,2,3,0,0,0], m = 3
nums2 = [2,5,6], n = 3
思路:两种方法,一是先将数组2加入数组1后面,然后再排序,即先合并在排序,复杂度为O(NlogN),不是最优;
方法二:双指针,分别指向两个数组的有数的最后一位,一个指向数组1的最后一位p,ab比较,大的放在最后,并且将大的那个数对应的索引减1,直到a或b其中一个为0,然后如果nums2的索引b不为0,将nums的前b个数复制到数组1即可。时间复杂度为O(M+N)
class Solution {
public void merge(int[] nums1, int m, int[] nums2, int n) {
for(int i = m;i < m+n;i++){
nums1[i] = nums2[i-m];
}
Arrays.sort(nums1);
}
public void merge1(int[] nums1, int m, int[] nums2, int n) {
int a = m-1, b = n-1,p = m+n-1;
while(a >= 0 && b >= 0){
nums1[p--] = nums1[a] < nums2[b] ? nums2[b--] : nums1[a--];
}
//System.arraycopy(nums2,0,nums1,0,b+1);
while(b >= 0){
nums1[p--] = nums2[b--];
}
}
}
2.合并两个有序链表
输入:1->2->4, 1->3->4
输出:1->1->2->3->4->4
递归
l1为空返回l2,l2为空返回l1;
当l1.val <= l2.val时,list.next = 递归 (l1.next,l2),return l1
当l1.val > l2.val时,l2.next = 递归(l1,l2.next)return l2;
迭代
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
public ListNode mergeTwoLists1(ListNode l1, ListNode l2) {
if(l1 == null) return l2;
if(l2 == null) return l1;
if(l1.val <= l2.val){
l1.next = mergeTwoLists(l1.next,l2);
return l1;
}
else{
l2.next = mergeTwoLists(l1,l2.next);
return l2;
}
}
public ListNode mergeTwoLists(ListNode l1, ListNode l2) {
ListNode res = new ListNode(0);
ListNode temp = res;
while(l1!=null && l2!=null){
if(l1.val <= l2.val){
temp.next = l1;
l1 = l1.next;
}
else{
temp.next = l2;
l2 = l2.next;
}
temp = temp.next;
}
temp.next = l1==null ? l2:l1;
return res.next;
}
}
3.交换两个数
方法一:引入一个变量存放;
方法二:做加法运算,先将a赋值为a+b,b = a-b,a = a-b;一行代码:a = (a+b) - (b = a);
方法三:乘法运算,a = (a*b)/(b = a);
方法四:位运算,一个数异或另外一个数两次等于它本身,因为两个数相同异或等于0,0异或任何数都等于本身,所以:a = a^b, b = a^b,a = a^b;
一行代码:a = (a^ b)^(b = a);
4.双指针移除数组重复元素 和 移除指定元素
输入: nums = [0,0,1,1,1,2,2,3,3,4]
输出: 5 (0,1,2,3,4)
class Solution {
public int removeDuplicates(int[] nums) {
if (nums.length == 0) return 0;
int i = 0;
for (int j = 1; j < nums.length; j++) {
if (nums[j] != nums[i]) {
i++;
nums[i] = nums[j];
}
}
return i + 1;
}
}
输入:nums = [1,2,3,2] val = 2
输出:2 (1,3)
class Solution {
public int removeElement(int[] nums, int val) {
if(nums == null || nums.length == 0) return 0;
int i = 0;
for(int j = 0;j<nums.length;j++){
if(nums[j]!=val)
nums[i++] = nums[j];
}
return i;
}
}